Теоретические основы реляционной модели данных

Базовые понятия теории множеств. Наиболее простой структурой данных будет такая, в которой отсутствуют какие-либо взаимосвязи между ее отдельными элементами. Совокупность таких данных представляет собой множество. Понятие множества является неопределяемым. Множество не обладает внутренней структурой, но является совокупностью элементов, обладающих некоторым общим свойством. Чтобы некоторую… Читать ещё >
Теоретические основы реляционной модели данных (реферат, курсовая, диплом, контрольная)
Теоретическую основу реляционной модели данных составляют теория множеств, реляционная алгебра и реляционное исчисление.
Базовые понятия теории множеств. Наиболее простой структурой данных будет такая, в которой отсутствуют какие-либо взаимосвязи между ее отдельными элементами. Совокупность таких данных представляет собой множество. Понятие множества является неопределяемым. Множество не обладает внутренней структурой, но является совокупностью элементов, обладающих некоторым общим свойством. Чтобы некоторую совокупность элементов можно было назвать множеством, необходимо существование правил, позволяющих: определять, принадлежит ли рассматриваемый элемент данной совокупности; отличать элементы друг от друга. Последнее правило означает, что множество не может содержать двух одинаковых элементов.
Множества обозначаются заглавными латинскими буквами. Если элемент х принадлежит множеству А, то это обозначается следующим образом:

Если каждый элемент множества В является также элементом множества A, то говорят, что множество В является подмножеством множества A:

Подмножество В множества A называется собственным подмножеством, если 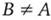 .
.
Производя операции над множествами, можно построить новые объекты. Основными операциями над множествами являются объединение, пересечение и разность.
Объединением двух множеств называется новое множество, элементами которого являются элементы, принадлежащие первому или второму множеству.
Пересечением двух множеств называется новое множество, элементами которого являются элементы, принадлежащие и первому, и второму множеству.
Разностью двух множеств называется новое множество, элементами которого являются элементы первого множества за исключением его элементов, являющихся также и элементами второго множества.
Важной операцией создания новых объектов из имеющихся множеств является декартово произведение множеств.
Если А и В множества, то выражение 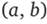 , где
, где 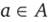 и
и  , называется упорядоченной парой. Равенство вида
, называется упорядоченной парой. Равенство вида 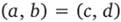 означает, что
означает, что 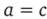 и
и  .
.
В общем случае можно рассматривать упорядоченную последовательность элементов 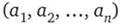 из элементов
из элементов 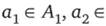
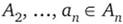 . Такие упорядоченные последовательности элементов множеств называют наборами, или кортежами.
. Такие упорядоченные последовательности элементов множеств называют наборами, или кортежами.
Декартовым произведением множеств 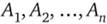 называется множество упорядоченных кортежей вида.
называется множество упорядоченных кортежей вида.

Степенью декартова произведения называют число множеств n, входящих в это декартово произведение.
Подмножество R декартова произведения множеств 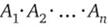 называется отношением степени n, или n-арным отношением. Мощность множества кортежей, входящих в отношение R, называют мощностью отношения Я.
называется отношением степени n, или n-арным отношением. Мощность множества кортежей, входящих в отношение R, называют мощностью отношения Я.
Понятие отношения лежит в основе всей реляционной теории БД. Ключевыми являются следующие моменты:
¦ все элементы отношения являются однотипными кортежами. Однотипность кортежей позволяет их считать аналогами строк простой таблицы, т. е. таблицы, в которой все строки состоят из одинакового числа ячеек и в соответствующих ячейках содержатся одинаковые типы данных;
¦ отношение включает в себя не все возможные кортежи декартова произведения. Это значит, что для каждого отношения имеется критерий, по которому определяют, какие кортежи входят в отношение. Этот критерий определяет семантику, или смысловое значение, отношения. Логическое выражение, позволяющее определить, будет ли кортеж принадлежать отношению, называют предикатом отношения.
Отсюда следует, что степень отношения является аналогом столбцов, а мощность — аналогом числа строк в таблице.
Организация данных в СУБД иерархического типа определяется в терминах: «элемент данных» («атрибут»), «агрегат», «запись» («группа»), «групповое отношение», «база данных» .
Атрибут (элемент данных) — наименьшая единица структуры данных. Обычно каждому элементу при описании БД присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
Запись — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов.
Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей — вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись. При удалении родительской записи автоматически удаляются все подчиненные.
Иерархические БД имеют два недостатка:
- 1) частично дублируется информация между записями Сотрудник и Исполнитель (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями;
- 2) модель реализует отношение между исходной и дочерней записью по схеме 1: N, т. е. одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте, т. е. возникает связь типа М: N. В этом случае в БД необходимо ввести еще одно групповое отношение, в котором Исполнитель будет являться исходной записью, а Контракт — дочерней. Таким образом, опять необходимо дублировать информацию.
В иерархической модели определены следующие операции над данными:
¦ Добавить в БД новую запись. Для корневой записи обязательно формирование значения ключа;
¦ Изменить значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям;
¦ Удалить некоторую запись и все подчиненные ей записи;
¦ Извлечь: корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей; следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева).
В операции Извлечь допускается задание условий выборки (например, извлечь сотрудников с окладом более 1000 руб.).
Как видим, все операции изменения применяются только к одной «текущей» записи, которая предварительно извлечена из БД. Такой подход к манипулированию данными получил название навигационного.
В этом случае поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка), но не обеспечивается автоматическое поддержание соответствия парных записей, входящих в различные иерархии.
На разработку этого стандарта структуры сетевой модели данных большое влияние оказал американский ученый Ч. Бахман. Основные принципы сетевой модели данных были разработаны в середине 1960;х гг., эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам БД (Conference on DAta SYstem Languages) CODASYL (1971).
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1: N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства, общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно, пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа, т. е. сотрудник, например, не может работать в двух отделах.
Иерархическая структура преобразовывается в сетевую.
Каждый экземпляр группового отношения характеризуется способом упорядочения подчиненных записей: произвольный, хронологический (очередь), обратный хронологический (стек), сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания.
Каждый экземпляр группового отношения характеризуется также режимом включения подчиненных записей:
¦ автоматический — невозможно занести в БД запись без того, чтобы она была сразу же закреплена за неким владельцем;
¦ ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем;
¦ режим исключения.
Принято выделять три класса членства подчиненных записей в групповых отношениях.
- 1. Фиксированное. Подчиненная запись жестко связана с записью-владельцем, и ее можно исключить из группового отношения только путем удаления. При удалении записи-владельца все подчиненные записи тоже автоматически удаляются. В рассмотренном ранее примере фиксированное членство предполагает групповое отношение «Заключает» между записями «Контракт» и «Заказчик», поскольку контракт не может существовать без заказчика.
- 2. Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи «Сотрудник» и «Отдел». Если отдел расформировывается, все его сотрудники должны быть либо переведены в другие отделы, либо уволены.
- 3. Необязательное. Можно исключить запись из группового отношения, но сохранить ее в БД, не прикрепляя к другому владельцу. При удалении записи-владельца ее подчиненные записи — необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить запись «Выполняет» между записями «Сотрудник» и «Контракт», поскольку в организации могут существовать работники, чья деятельность не связана с выполнением каких-либо договорных обязательств перед заказчиками.
В сетевой модели определены следующие операции над данными:
¦ Добавить — внести запись в БД, и в зависимости от режима включения либо включить ее в групповое отношение, где она объявлена подчиненной, либо не включать ни в какое групповое отношение;
¦ Включить в групповое отношение — связать существующую подчиненную запись с записью-владельцем;
¦ Исключить из группового отношения — разорвать связь между записью-владельцем и записью-членом;
¦ Переключить — связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении;
¦ Обновить — изменить значение элементов предварительно извлеченной записи;
¦ Извлечь — извлечь записи последовательно по значению ключа, а также, используя групповые отношения, от владельца можно перейти к записям-членам, а от подчиненной записи — к владельцу набора;
¦ Удалить — убрать из БД запись. Если эта запись является владельцем группового отношения, то анализируется класс членства подчиненных записей. Обязательные члены должны быть предварительно исключены из группового отношения, фиксированные удалены вместе с владельцем, необязательные останутся в БД.
Как и в иерархической, в сетевой модели обеспечивается только поддержание целостности по ссылкам (владелец отношения — член отношения).
Реляционная модель данных. Реляционная модель предложена сотрудником компании IBM Е. Коддом в 1970 г. В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
Структура данных в реляционной модели достигает гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В статье Е. Кодда утверждается, что реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т. е. без потребности введения какой-либо дополнительной структуры для целей машинного представления. Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от англ. «relation» — отношение).
Перейдем к рассмотрению структурной части реляционной модели данных. Прежде всего необходимо дать несколько определений.
Для заданных конечных множеств  (не обязательно различных) декартовым произведением
(не обязательно различных) декартовым произведением 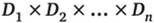 называется множество произведений вида
называется множество произведений вида 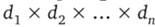 , где
, где 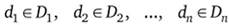
Например, если даны два множества 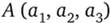 и
и 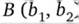 , то их декартово произведение будет иметь вид
, то их декартово произведение будет иметь вид 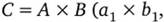
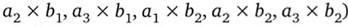
Отношением R, определенным на множествах  , называется подмножество декартова произведения
, называется подмножество декартова произведения 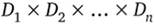
При этом:
¦ множества 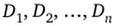 называются доменами отношения;
называются доменами отношения;
¦ элементы декартова произведения 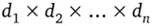 называются корт ежам и;
называются корт ежам и;
¦ число п определяет степень отношения (П = 1 — унарное, 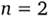 — бинарное,…, n-арное);
— бинарное,…, n-арное);
¦ количество кортежей называется мощностью отношения.
На множестве С из предыдущего примера могут быть определены отношения 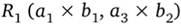 или
или 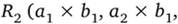

Отношения удобно представлять в виде таблиц. На рис. 20.1 представлена таблица (отношение степени 5), содержащая некоторые сведения о работниках гипотетического предприятия. Строки.
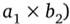
Рис. 20.1. Основные компоненты реляционного отношения таблицы соответствуют кортежам. Каждая строка фактически представляет собой описание одного объекта реального мира (в данном случае работника), характеристики которого содержатся в столбцах. Можно провести аналогию между элементами реляционной модели данных и элементами модели «сущность — связь». Реляционные отношения соответствуют наборам сущностей, а кортежи — сущностям. Поэтому так же, как и в модели «сущность — связь», столбцы в таблице, представляющей реляционное отношение, называют атрибутами.
Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута.
Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене. На рис. 20.1 атрибуты «Оклад» и «Премия» определены на домене «Деньги». Поэтому понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом примере сравнение атрибутов «Табельный номер» и «Оклад» является семантически некорректным, хотя они и содержат данные одного типа.
Именованное множество пар «имя атрибута — имя домена» называется схемой отношения. Мощность этого множества называют степенью, или арностью, отношения. Набор именованных схем отношений представляет собой схему базы данных.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). В рассматриваемом случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ.
Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей.
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Отношения обладают следующими свойствами.
- 1. Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого кортежа первичного ключа. Для каждого отношения по крайней мере полный набор его атрибутов является первичным ключом. Однако при определении первичного ключа должно соблюдаться требование минимальности, т. е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа — однозначно определять кортеж.
- 2. Отсутствие упорядоченности кортежей.
- 3. Отсутствие упорядоченности атрибутов. Для ссылки на значение атрибута всегда используется имя атрибута.
- 4. Атомарность значений атрибутов, т. е. среди значений домена не могут содержаться множества значений (отношения).
Построению информационной модели предшествует системный анализ:
¦ выделяются существенные части и свойства объекта в рамках поставленной задачи;
¦ установление связей между существенными факторами в моделируемой системе;
¦ определение ее структуры.
Изучение предметной области заключается в выявлении существенных процессов и факторов, оказывающих определяющее влияние на достижение целей.
Модель предметной области — это записанные знания об объектах реального мира, которыми необходимо управлять наиболее рациональным образом. Эти знания могут быть представлены как в чисто текстовом виде, так и с использованием методологий структурного функционального моделирования — SADT, IDEF0, IDEF3, методологий и стандартов описания состава, структуры и взаимосвязей используемой в деятельности предприятия информации — IDEF1, DFD [8, 17]. Нотации названных методологий используются в инструментальных case-средствах — BPWin, АIO WIN, ProCap, ProSim, SmartER, а также ARIS, дополнительно обеспечивающего поддержку стандарта ERM, UML и предоставляющего существенно большие возможности по работе с отдельными объектами модели.
Логическая модель данных описывает понятия предметной области и их взаимосвязи и является прототипом будущей БД. Логическая модель разрабатывается в терминах информационных понятий, но без какой-либо ориентации на конкретную СУБД. Наиболее широко используемым средством разработки логических моделей баз данных являются диаграммы «сущность — связь» (Entity-Relationship, ER-диаграммы). Следует заметить, что логическая модель данных, представленная ER-диаграммами, в принципе, может быть преобразована как в реляционную модель данных, так и в иерархическую, сетевую, постреляционную.
Физическая модель данных строится на базе логической модели и описывает данные уже средствами конкретной СУБД. Отношения, разработанные на стадии логического моделирования, преобразуются в таблицы, атрибуты в столбцы, домены в типы данных, принятые в выбранной конкретной СУБД. На этапах логического и физического моделирования, как правило, используется стандарт IDEF1X и case-средства ERWin или SmartER. Указанные инструментальные средства проектирования поддерживают несколько десятков наиболее популярных СУБД. Результатом физического моделирования является генерация программного кода БД на соответствующем выбранной СУБД диалекте структурированного языка запросов SQL.
Несмотря на постоянно совершенствуемые возможности case-средств по автоматической генерации кода БД, детальное ее проектирование все-таки остается работой и заботой человека. Case-средства помогают создать прототип БД, на котором строится ее рабочая версия. Поскольку практически любая база кроме таблиц содержит дополнительный программный код в виде триггеров и хранимых процедур, которые пишутся на процедурных расширениях языка SQL или универсальном языке программирования, то полностью автоматизировать ее создание из логической модели пока не представляется возможным, а может быть и нужным.
Хранимые процедуры — это процедуры и функции, хранящиеся непосредственно в БД в откомпилированном виде, которые могут запускаться непосредственно пользователем или прикладными программами, работающими с БД. Их основным назначением является реализация бизнес-процессов предметной области,.
Триггеры — это хранимые процедуры, связанные с некоторыми событиями, происходящими во время работы БД. В качестве таких событий обычно выступают операции вставки, обновления и удаления строк таблиц. Если в БД определен некоторый триггер, то он запускается автоматически всегда при возникновении события. Важным является то, что пользователи не могут обойти триггер, независимо от того кто из них и каким образом инициировал запускающее его событие. Основным назначением триггеров является автоматическая поддержка целостности БД, но они могут использоваться и для реализации достаточно сложных ограничений, накладываемых предметной областью, например с операцией вставки нового товара в накладную может быть связан триггер, который проверяет наличие необходимого товара на складе и выполняет другие необходимые действия.