Ф4. 5. Критерий метода К-средних

Данный критерий зависит от двух наборов переменных, S и с, и поэтому может быть минимизирован с помощью метода альтернативной минимизации, смысл которого заключается в регулярном повторении одного и того же шага минимизации по одной из групп переменных. При заданных значениях группы переменных нужно оптимизировать критерий по другой группе переменных. Потом при найденных значениях этой второй… Читать ещё >
Ф4. 5. Критерий метода К-средних (реферат, курсовая, диплом, контрольная)
Метод К-средних оперирует с разбиением множества объектов на К неперссекающихся кластеров, S = {.S', S2,…, SK}, представленных в виде списков номеров объектов Sk, и центрами этих кластеров ск = (ск1, ск2, ???, ckv), к = 1,2,…, К.
В основе работы алгоритма К-средних находится математическая модель представления данных с помощью кластерной структуры. Согласно этой модели каждый объект i, заданный соответствующей строкой матрицы Y как yi = (yiV yi2, …, yiV), принадлежит к какому-то из кластеров Sk, и равен, с точностью до малых ошибок, центру этого кластера:
Проблема кластер-анализа ставится так: найти 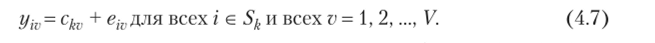 такое разбиение S = {5', S2…
такое разбиение S = {5', S2…
SK} и такие центры кластеров ск = (ск1, ск2,…, ckv), к = 1, 2,…, К, которые минимизировали бы суммарную квадратичную ошибку в равенствах (4.7), равную.
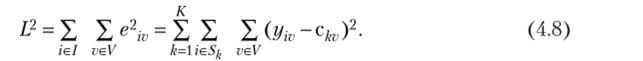
Критерий (4.8) может быть переформулирован в терминах евклидовых расстояний. Величина (4.8) есть не что иное, как сумма квадратов Евклидовых расстояний между объектами и центрами их кластеров (рис. 4.17).
Необходимо иметь в виду, что число расстояний в сумме равно N и не зависит от количества кластеров. Вот явное выражение критерия через расстояния между векторами (cfo.) и (г/,"): 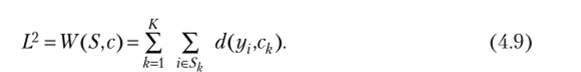
Здесь расстояние d между любыми векторами х = (хГ) и у = (у,) определяется формулой 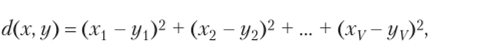
что в точности совпадает с внутренней суммой в уравнении (4.8) при х = у, и у = ск.

Рис. 4.17. Расстояния между объектами и центрами в критерии 1У ($, с).
Данный критерий зависит от двух наборов переменных, S и с, и поэтому может быть минимизирован с помощью метода альтернативной минимизации, смысл которого заключается в регулярном повторении одного и того же шага минимизации по одной из групп переменных. При заданных значениях группы переменных нужно оптимизировать критерий по другой группе переменных. Потом при найденных значениях этой второй группы оптимизировать критерий по первой группе переменных, и так продолжать, пока процесс не сойдется.
Если дан набор центров с = (с{, с2, ск), можно легко найти разбиение 5,.
минимизирующее суммарное расстояние (4.9). Для этого достаточно определить для каждого объекта i е IК расстояний d (ifv q), d (yv с2), …, d (yv ск) до всех центров. Минимизация (4.9) по S при заданных центрах происходит с использованием правила минимального расстояния: для каждого i е /, выбираем минимум из d (yjy ck)y k = 1, …, К, и приписываем объект i ближайшему центру. В случае когда минимум достигается на нескольких центрах, можно взять любой из них. При этом может оказаться, что некоторым центрам не приписано ни одного объекта. Чтобы избежать такой дегенерации решения, достаточно взять начальные центры из числа объектов анализируемого множества.
Следующим шагом альтернативной минимизации будет минимизация (4.9) относительно центров с при заданном 5, найденном на предыдущем шаге. Аддитивная форма критерия (4.9) делает кластеры и их компоненты независимыми друг от друга. Как хорошо известно (см. табл. 2.1 в гл. 2), решением задачи минимизации квадрата ошибки является среднее, поэтому векторы средних внутрикластерных значений минимизируют выражение (4.9) но с* при данном S.
Таким образом, метод альтернативной минимизации критерия (4.9) состоит в следующем. Сначала каким-то образом выбираются центры с = (q, с2, ск),.
после чего начинаются повторяющиеся итерации, состоящие из двух шагов: (а) обновление кластеров — определение кластеров S по правилу минимального расстояния и (б) обновление центров как векторов внутрикластерных средних значений по каждой компоненте отдельно. Вычисления останавливаются, когда новые кластеры совпадают с кластерами, полученными на предыдущем шаге. Очевидно, этот метод совпадает с параллельным методом К-средних.
Сходимость метода достигается благодаря двум следующим фактам: (i) на каждом шаге значение критерия (4.9) может только уменьшаться, и (ii) количество разбиений S конечно. Конечно, достижение глобального оптимума не гарантировано.
Вопрос 4.5. Сколько расстояний суммируются в ЙД5, с)?
Ответ. Ровно столько, сколько объектов, т. е. N.
Вопрос 4.5(1). Зависит ли это число от количества кластеров Ю
Ответ. Нет.
Вопрос 4.6. Верно ли, что имеет место следующий факт: чем больше К, тем меньше минимальное значение W (5, с)?
Ответ: Да. Подсказка: потому что число расстояний в критерии одно и то же, то их можно сделать в среднем меньше путем увеличении числа кластеров. Например, возьмем какой-нибудь кластер оптимального разбиения 5 и разобъем его пополам, взяв два центра вместо одного. Сумма расстояний до них станет меньше.
Вопрос 4.7. Почему гарантирована сходимость метода /(-средних?
Ответ. Потому что метод /(-средних является альтернативным процессом минимизации, в котором критерий W (S, с) может только уменьшаться на каждом шаге. Сходимость следует из того, что на конечном множестве объектов / может быть только конечное число разбиений.
Вопрос 4.8. Допустим, что d (yt, ck) в W (S, с) это не квадрат евклидова расстояния, а расстояние городских кварталов. Можно ли изменить метод /(-средних таким образом, чтобы сделать его методом альтернативной минимизации для модифицированного критерия W (S, с)?
Ответ. Да, при обновлении кластеров надо использовать расстояние городских кварталов, а центры формировать не из средних, а медиан признаков внутри кластеров.
Вопрос 4.9. Приведет ли такая замена расстояния к каким-либо отличиям?
Ответ. Обычно да, особенно в случае, когда распределения признаков асимметричны.
Вопрос 4.10. Продемонстрировать, что в данных о компаниях значение W (S, с) на разбиении {1−2-3, 4−5-6, 7−8} но продукту меньше, чем па разбиении {1−4-6, 2, 3−5-7−8}, найденном, начиная с центров в объектах 1, 2 и 3.
Ответ. Действительно, суммы внутрикластерных расстояний от объектов до центров кластеров по продукту равны 0,7193, 0,8701, 0,3070 соответственно, что в сумме даст 1,8964. Во втором же разбиении суммарные расстояния до центров — 1,4411, 0, 2,1789, в сумме 3,62, чуть ли не в 2 раза больше.
Вопрос 4.11. Доказать, что в данных о компаниях значение W (5, с) на разбиении {1−2-3, 4−5-6, 7−8} по продукту меньше, чем на разбиении {1−2-3, 4−6, 5−7-8}, найденном исходя из начальных центров в объектах 1, 4 и 7.
Ответ. Действительно, суммы внутрикластерных расстояний до центров кластеров по продукту равны 0,7193, 0,8701, 0,3070 соответственно, т. е. в сумме 1,8964, тогда как внутрикластерные суммы расстояний во втором разбиении равны 0,7193, 0,4413,4,1020, т. е. 2,2626.'.
В4.5. Вычисления по методу /(-средних с использованием системы МатЛаб Сформулируем шаги алгоритма /(-средних.
- 0. Выбираем начальные данные.
- 1. Нормализуем данные.
- 2. Выбираем количество кластеров К.
- 3. Определяем К начальных центров.
- 4. Обновляем кластеры, приписывая объекты центрам по правилу минимальных расстояний.
- 5. Обновляем центры, определяя центры как центры масс кластеров.
- 6. Повторяем шаги 4 и 5, пока не сойдутся.
Коды МатЛаба для самых сложных шагов 4 и 5 представлены ниже.
4. Обновление кластеров: Присваиваем точки центрам по правилу минимальных расстояний.
Вход: матрица данных X и К х V массив центров, выход: массив размерности N номеров кластеров, приписанных объектам, и сумма расстояний от всех объектов до соответствующих центров (переменная wc в коде):
function [labelc, wc]=clusterupdate (X, cent).
[K, m]=size (cent);
[N, m]=size (X); for k=l:K.
cc=cent (k:); %центр кластера k Ck=rcpmat (cc, N, 1); dif=X-Ck;
ddif=dif.*dif; %Nxm матрица квадратов разностей dist (k:)=sum (ddif);
%это расстояния от всех объектов до соответствующих центров end.
[aa, bb]=min (dist); % правило минимального расстояния.
wc=sum (aa);
labelc=bb;
return.
5. Обновление центров: Определяем центры масс кластеров, заданных вектором номеров кластеров labelc, соответственно данным в матрице X. Для вычисления новой К х V матрицы центров, используем следующее:
function centres=ceupdate (X, labclc).
K=max (labelc); for k=l:K.
clk=find (labelc=k); elemk=X (clk:); centres (k:)=mean (elemk); end return.
Параллельный метод iC среди их релизуется в МатЛабе включением в вычисление шагов 3—6, описанных выше, и выдачей массива Clusters типа cell. В нем рассчитаны также вклады в квадратичный разброс данных. Входная информация: предварительно нормализованная матрица X и множество начальных центров (cent):
function [Clusters, uds]=k_mcans (X, cent).
[N, m]=size (X);
[K, ml]=size (cent); flag=0; %— критерий останова membership=zeros (N, l); dd=sum (sum (X.*X)); %— разброс данных %— обновление кластеров и центров while llag=0.
[labelc, wc]=clusterupdate (Y, cent); if isequal (labelc, membership).
%—критерий останова.
flag=l;
centre=cent;
w=wc;
else.
cent=ceupdatc (Y, labelc); membership=labelc;
end.
end.
%…подготовка выдачи результатов.
uds=w*100/dd;
Clusters) 1 }=membership;
Clusters{2}=centre;
return.
Таблица 4.13
Таблица сопряженности разбиения ирисов на таксоны и разбиения, полученного в результате применения метода /^-средних (с начальными центрами 1, 51 и 101). Кластер 1 совпадает с таксоном Iris Setosa, но остальные два кластера неправильно классифицируют 14 + 3 = 17 объектов двух оставшихся групп.
Кластер | Setosa. | Versicolor. | Virginica. | Всего. |
S1. | ||||
S2. | ||||
S3. | ||||
Всего. |
Вопрос 4.12. Показать, что если метод iC-срсдних применить к данным об ирисах, стандартизованным путем вычитания среднего из каждого признака с последующим делением признака на размах, при К= 3 и объектах 1,51 и 101 в качестве начальных центров, то итоговые результаты кластеризации и перекрестной классификации будут, как в табл. 4.13.