Метод кодирования Хаффмана

Метод кодирования или сжатия информации на основе двоичных кодирующих деревьев был предложен Д. А. Хаффманом в 1952 году задолго до появления современного цифрового компьютера. Обладая высокой эффективностью, он и его многочисленные адаптивные версии лежат в основе многих методов, используемых в современных алгоритмах кодирования. Код Хаффмана редко используется отдельно, чаще работая в связке… Читать ещё >
Метод кодирования Хаффмана (реферат, курсовая, диплом, контрольная)
Метод кодирования или сжатия информации на основе двоичных кодирующих деревьев был предложен Д. А. Хаффманом в 1952 году задолго до появления современного цифрового компьютера. Обладая высокой эффективностью, он и его многочисленные адаптивные версии лежат в основе многих методов, используемых в современных алгоритмах кодирования. Код Хаффмана редко используется отдельно, чаще работая в связке с другими алгоритмами кодирования. Метод Хаффмана является примером построения кодов переменной длины, имеющих минимальную среднюю длину. Этот метод производит идеальное сжатие, то есть сжимает данные до их энтропии, если вероятности символов точно равны отрицательным степеням числа 2.
Этот метод кодирования состоит из двух основных этапов:
- · Построение оптимального кодового дерева.
- · Построение отображения код-символ на основе построенного дерева.
Алгоритм основан на том, что некоторые символы из стандартного 256-символьного набора в произвольном тексте могут встречаться чаще среднего периода повтора, а другие — реже. Следовательно, если для записи распространенных символов использовать короткие последовательности бит, длиной меньше 8, а для записи редких символов — длинные, то суммарный объем файла уменьшится. В результате получается систематизация данных в виде дерева («двоичное дерево»).
Пусть A={a1,a2,…, an} - алфавит из n различных символов, W={w1,w2,…, wn} - соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов C={c1,c2,…, cn}, такой что:
— ci не является префиксом для cj, при i≠j; минимальна (|ci| длина кода ci) называется минимально-избыточным префиксным кодом или иначе кодом Хаффмана.
Бинарным деревом называется ориентированное дерево, полустепень исхода любой из вершин которого не превышает двух.
Вершина бинарного дерева, полустепень захода которой равна нулю, называется корнем. Для остальных вершин дерева полустепень захода равна единице.
Пусть Тбинарное дерево, А=(0,1) — двоичный алфавит и каждому ребру Т-дерева приписана одна из букв алфавита таким образом, что все ребра, исходящие из одной вершины, помечены различными буквами. Тогда любому листу Т-дерева можно приписать уникальное кодовое слово, образованное из букв, которыми помечены ребра, встречающиеся при движении от корня к соответствующему листу. Особенность описанного способа кодирования в том, что полученные коды являются префиксными.
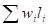

Очевидно, что стоимость хранения информации, закодированной при помощи Т-дерева, равна сумме длин путей из корня к каждому листу дерева, взвешенных частотой соответствующего кодового слова или длиной взвешенных путей:, где — частота кодового слова длины во входном потоке. Рассмотрим в качестве примера кодировку символов в стандарте ASCII. Здесь каждый символ представляет собой кодовое слово фиксированной (8 бит) длины, поэтому стоимость хранения определится выражением, где Wколичество кодовых слов во входном потоке.
Поэтому стоимость хранения 39 кодовых слов в кодировке ASCII равна 312, независимо от относительной частоты отдельных символов в этом потоке. Алгоритм Хаффмана позволяет уменьшить стоимость хранения потока кодовых слов путем такого подбора длин кодовых слов, который минимизирует длину взвешенных путей. Будем называть дерево с минимальной длиной путей деревом Хаффмана.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
- 1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение;
- 2. Выбираются два свободных узла дерева с наименьшими весами;
Создается их родитель с весом, равным их суммарному весу;
Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка;
Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0;
Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая таблица частот.
Табл. 1.
А. | Б. | В. | Г. | Д. |
На первом шаге из листьев дерева выбираются два с наименьшими весами — Г и Д. Они присоединяются к новому узлуродителю, вес которого устанавливается 5+6= 11. Затем узлы Г и Д удаляются из списка свободных. Узел Г соответствует ветви 0 родителя, узел Д — ветви 1.
На следующем шаге то же происходит с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве. Создается новый узел с весом 13, а узлы Б и В удаляются из списка свободных.
На следующем шаге «наилегчайшей» парой оказываются узлы Б/В и Г/Д.
Для них еще раз создается родитель, теперь уже с весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д — ветви 1.
На последнем шаге в списке свободных осталось только 2 узла — это узел, А и узел Б (Б/В)/(Г/Д). В очередной раз создается родитель с весом 39, и бывшие свободные узлы присоединяются к разным его ветвям.
Поскольку свободным остался только один узел, то алгоритм построения дерева кодирования Хаффмана завершается.
Каждый символ, входящий в сообщение, определяется как конкатенация нулей и единиц, сопоставленных ребрам дерева Хаффмана, на пути от корня к соответствующему листу.
Для данной таблицы символов коды Хаффмана будут выглядеть, как показано в табл. 2.
Табл. 2. Коды Хаффмана.
А. | |
Б. | |
В. | |
Г. | |
Д. |
Наиболее частый символ сообщения, А закодирован наименьшим количеством бит, а наиболее редкий символ Д — наибольшим. Стоимость хранения кодированного потока, определенная как сумма длин взвешенных путей, определится выражением 15*1+7*3+6*3+6*3+5*3=87, что существенно меньше стоимости хранения входного потока (312).
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока.
Алгоритм декодирования предполагает просмотр потоков битов и синхронное перемещение от корня вниз по дереву Хаффмана в соответствии со считанным значением до тех пор, пока не будет достигнут лист, то есть декодировано очередное кодовое слово, после чего распознавание следующего слова вновь начинается с вершины дерева.
Классический алгоритм Хаффмана имеет один существенный недостаток. Для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и дерева Хаффмана), другого собственно для кодирования.