ОСНОВНАЯ ЧАСТЬ: Автоматизация мониторинга и системного анализа распределенной проблемно-ориентированной информации в среде интернет

Приведенные в работе методы, основанные на формализованных описаниях основных служб Интернета, потенциально позволяют достичь максимальной полноты охвата информационных ресурсов в сети Интернет соответствующих определенной предметной области. Однако на практике в WWW часто бывает сложно выявить замкнутые информационные массивы и найти в них начальные страницы, такие, что предоставляют возможность… Читать ещё >
ОСНОВНАЯ ЧАСТЬ: Автоматизация мониторинга и системного анализа распределенной проблемно-ориентированной информации в среде интернет (реферат, курсовая, диплом, контрольная)
Во введении обоснована актуальность проводимой работы, а также необходимость разработки новых подходов и исследования процессов мониторинга и системного анализа распределенной проблемно-ориентированной информации в компьютерных сетях, а также создания программных продуктов обеспечивающих быстрый доступ к слабоструктурированной или неструктурированной информации. Здесь сформулирована цель работы и задачи, которые необходимо решить для достижения поставленной цели, указана научная новизна и приводится краткий обзор структуры работы.
В первой главе анализируются проблемы разработки и применения методов системного анализа обработки распределенной проблемно-ориентированной информации в среде Интернет. На основании работ В. Н. Волковой, А. А. Денисова, О. Г. Тайца, С. Оптнера, Д. Клиланда, Н. Н. Моисеева, Ю. И. Черняка, Ф. И. Перегудова и других ученых рассмотрены подходы к выполнению системного анализа информационных ресурсов. Также рассмотрены подходы и пути автоматизации анализа данных (работы: И. Ф. Кодда, Н. Пендса, С. К. Дулина, И. А. Киселева, А.В. Заболеева-Зотовой, А. В. Андрейчикова, Т. А. Гавриловой, В. Ф. Хорошевского и др.), мониторинга информации (работы: С. В. Кузнецова, О. Б. Сладковой, С. К. Дулина, Т. Я. Ашихминой, Б. А. Баллода, Э. С. Манелиса и др.), теории информационного поиска (работы: Дж. Солтона, К. Спарк-Джоунз, И. И. Попова, А. Г. Романенко, О. Ф. Самойлюка, В. А. Копылова, Ю. И. Шемакина, П. Б. Храмцова и др.).
Анализ результатов научных исследований в области мониторинга и системного анализа информационных ресурсов, а также информации web-серверов компаний-производителей современных средств поиска и систем управления знаниями («Microsoft», «IBM», «Google», «Яndex», «Рамблер Интернет Холдинг» и др.) показал наличие в них средств, позволяющих решать отдельные задачи обработки информации. В связи с этим были сделаны следующие выводы:
Ввиду специфики темы работы, ориентированной на обеспечение постоянного мониторинга и системного анализа информации, проанализированы подходы к организации хранения и анализа данных на основе использования технологий хранилищ данных.
Методы, используемые для обработки информации Интернета, в том числе для поиска информации, и созданные с их использованием автоматизированные программные системы реализуют лишь часть реально необходимых в организациях функций по управлению информацией. К основным нереализуемым современными подходами и системами функциям относятся:
описание проблемы в соответствии со структурой предметной области;
автоматическое расширение накопленных знаний полученных из информации сети Интернет;
автоматизированный анализ всего перечня результатов в средствах поиска;
централизованное управление запросами и результатами поиска из различных систем.
На рис. 1 представлен сравнительный анализ основных параметров существующих систем и разработанной в рамках диссертационной работы системы формирования знаний, а также определено место данной информационно-аналитической системы среди этих систем.
Система формирования знаний является для организации связующим звеном между системами информационного поиска Интернета и системами управления знаниями, позволяя накапливать необходимые информационные ресурсы. Проведенный на рис. 1 сравнительный анализ рассматриваемых систем выявил их основные отличительные признаки: использование модели предметной области, возможность кластеризации информации и анализа результата поиска.
Вторая глава посвящена постановке задачи мониторинга и системного анализа распределенной проблемно-ориентированной информации в среде Интернет.
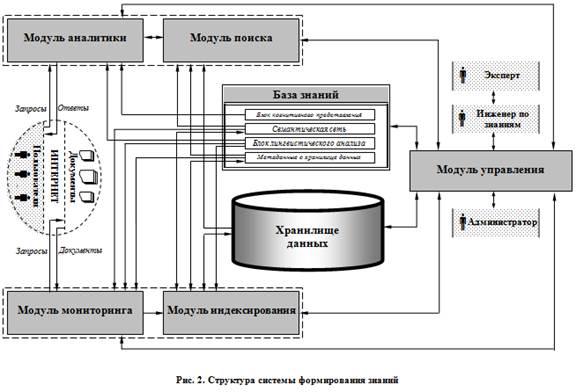
В этой главе приводится обоснование выбора и анализ свойств объекта исследования. Вводится новый тип систем — системы формирования знаний (knowledge forming system), под которыми понимается программное средство, выполняющее специально организованное, систематическое наблюдение за состоянием проблемно-ориентированных данных и получение из них знаний на основе моделей, методов и алгоритмов, опирающихся на комплексный подход и учет взаимосвязей между данными (рис. 2).
Система формирования знаний должна обеспечивать следующие функциональные возможности:
описание предметной области;
мониторинг проблемно-ориентированной информации;
индексирование информации;
предварительная обработка собранной и индексированной информации (очищение, согласование, агрегирование и др.);
структурирование (кластеризация, классификация) информации для построения на основе этого хранилища данных;
хранение и управление информацией в хранилище данных;
понимание запроса, сформулированного пользователем, причем от пользователя не требуется знание способа организации информации в системе;
выборка информации, релевантной запросу пользователя, представленной разнотипными документами;
представление информации на запрос пользователя в виде удобном для восприятия и анализа.
Рассмотрен принцип работы данного типа систем, которые автоматизируют процесс сбора и анализа информации из сети Интернет, что значительно облегчает работу пользователя. Общая схема работы предлагаемой системы включает два этапа:
- 1. Периодически с использованием модуля управления системы запускаются на выполнение модули мониторинга и индексирования. Цель работы данных модулей — найти новые и измененные информационные ресурсы в сети Интернет относящиеся к тематике предметной области, на которую ориентирована система, скорректировать хранилище данных системы и базу знаний в соответствии с текущим состоянием информационных ресурсов.
- 2. Параллельно с модулями мониторинга и индексирования и независимо от них в системе выполняются другие два модуля — модуль аналитики и модуль поиска. Цель этих модулей — отобрать данные, соответствующие запросам пользователей и провести их аналитическую обработку, используя для этого многомерное хранилище данных системы и базу знаний. При этом в ответ на запрос выдаются только те данные, информация о которых уже известна системе к моменту поступления запроса, т. е. эти данные проиндексированы и занесены в хранилище данных.
Следует отметить, что разработанная система универсальна в том смысле, что подходы, используемые в ней, не зависят от конкретной предметной области. Система может быть настроена на работу с информацией из широкого спектра различных предметных областей.
Рассмотренный тип систем, основанный на формировании знаний, позволяет эффективно выполнять мониторинг и системный анализ проблемно-ориентированной информации и таким образом способствует решению многих задач в организации.
Были разработаны общие принципы математического моделирования системы формирования знаний (рис 3.). Математическая модель включает модель предметной области, а также модели процессов мониторинга, индексирования, классификации и кластеризации.
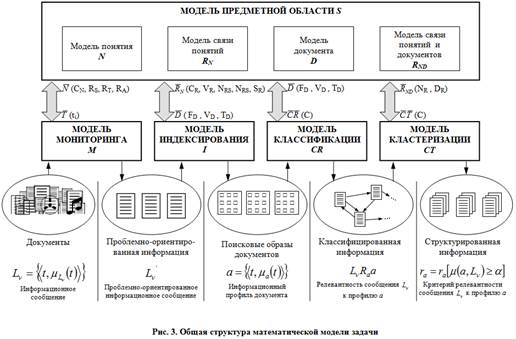
Документы, поступающие на вход в систему, проверяются на соответствие предметной области. Все соответствующие заданной предметной области документы образуют множество проблемно-ориентированных документов, каждый из которых в системе представляется в виде поискового образа. Документы классифицируются в соответствии с построенной моделью. Значительные по объему группы документов разделяются на более мелкие на основе алгоритмов кластеризации.
Сделано описание модели предметной области, на которую ориентирована система. В основе модели, описываемой предметной области, была положена семантическая сеть S:
S = ,(1).
гдеN = {N1, N2, …, NK} - множество элементов, отражающих понятия предметной области;
RN = RN (Ni, Nj) — отношение задающее тип и силу взаимодействия между понятиями.
D = {D1, D2, …, DL} - множество документов, относящихся к заданной предметной области;
RND = RND (Ni, Dj) — отношение сопоставляющее понятиям предметной области документы.
Третья глава посвящена исследованию системных связей и закономерностей функционирования процессов мониторинга и анализа распределенной проблемно-ориентированной информации в среде Интернет.
Мониторинг распределенной проблемно-ориентированной информации в сети Интернет осуществляется в разработанной системе формирования знаний на основе модели предметной области (основной частью которой является классифицирующая структура), которая формируется экспертом и выполняется путем взаимодействия системы с существующими в Сети системами информационного поиска (информационно-поисковые системы, каталоги, метапоисковые системы), а также самостоятельного исследования всего информационного пространства.
Для формализованного описания процесса мониторинга путем навигации в данных службах используется аппарат теории графов.
Служба WWW представлена в виде ориентированного графа W, состоящего из множества вершин (документов) D = {D1, D2, …, DM} и множества дуг (гиперссылок) LINKS:
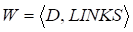
.(2).
Служба FTP представима в виде леса N, состоящего из множества деревьев {Ni ¦ i = 1, …, L}:
N = {Ni ¦ i = 1, …, L}.(3).
Каждое из деревьев представляет отдельный FTP-ресурс. Узлами FTP-ресурса являются папки F = {F1, F2, …, FK} и файлы (документы) D = {D1, D2, …, DM}.
Приведенные в работе методы, основанные на формализованных описаниях основных служб Интернета, потенциально позволяют достичь максимальной полноты охвата информационных ресурсов в сети Интернет соответствующих определенной предметной области. Однако на практике в WWW часто бывает сложно выявить замкнутые информационные массивы и найти в них начальные страницы, такие, что предоставляют возможность обойти все документы отдельного массива. В качестве таких начальных страниц могут выступать главные страницы крупных информационных ресурсов (в основном глобальных, региональных, локальных и специализированных каталогов). Универсального алгоритма поиска начальных страниц нет ввиду специфики организации Интернета. Источниками адресов этих страниц могут являться периодическая печать, СМИ, пользователи Интернета и др.
В данной главе подробно рассматривается метод мониторинга информационных ресурсов в системе формирования знаний — доступ к ним через существующие системы информационного поиска Интернета.
После осуществления доступа к информационному ресурсу с использованием любого из изложенных подходов модуль мониторинга выполняет проверку на предмет отсутствия сведений о нем в системе и, если данная проверка успешна, то выполняется еще одна проверка ресурса на предмет его соответствия заданной предметной области (наличие в нем ключевых слов запроса или их синонимов). Обе проверки могут быть выполнены модулем мониторинга автоматически, т. е. без привлечения человека. Если вторая проверка пройдена успешно — документ передается модулю индексирования для последующей обработки.
Обобщенно алгоритм работы модуля мониторинга может быть представлен схемой (рис. 4).
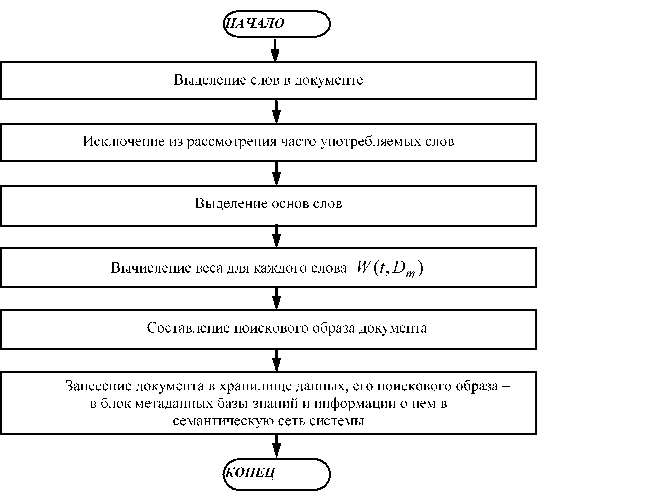
Процесс занесения документа Интернета в систему и формирование сведений о нем осуществляется алгоритмом изображенным на рис. 5.
Самый главный этап процесса индексирования — вычисление веса слова. На значение веса слова влияют следующие факторы:
частота употребления слова в документе, место употребления слова;
наличие у слова синонимов в тексте документа.
Значение веса слова в документе определяется по формуле:
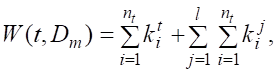
(4).
гдеDm — текстовый документ (m = 1, …, M; M — количество текстовых документов);
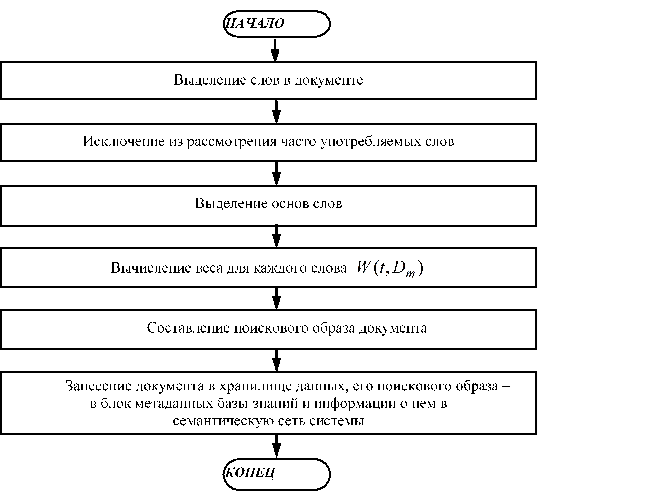
Рис. 4. Алгоритм работы модуля мониторинга
t — слово документа Dm;
— количество вхождений слова t в документ Dm;
l — количество синонимов слова t используемых в документе Dm;
— количество вхождений синонима l слова t в документ Dm;
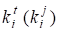
— переменная определяющая значимость слова t (j), находящегося в документе Dm на позиции i;
— вес слова t в документе Dm.
После завершения выполнения процессов индексирования и классификации может сложиться ситуация, при которой к одному объекту (термину) сети будет сопоставлена большая группа документов, анализ пользователем которой затруднен. В этом случае необходимо выполнить разделение данного объекта на более мелкие разделы, поддающиеся анализу.
Для решения описанной ситуации в системе имеется процесс автоматической кластеризации документов (рис. 6). Сделанное разбиение объектов с использованием данного модуля на части — подразделы в дальнейшем может быть скорректировано инженером по знаниям на основе данных полученных от эксперта.
Поиск и представление найденной, индексированной, классифицированной и кластеризованной информации пользователю выполняется по алгоритму рис. 7.
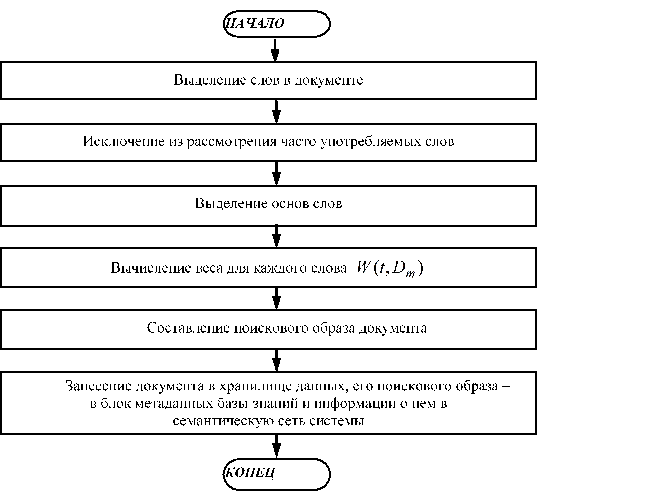
Рис. 5. Алгоритм индексирования
Ключевым этапом процесса поиска является вычисление меры релевантности документа запросу.
Эта мера показывает, на сколько слова входящие в запрос соответствуют содержимому документа. Она позволяет выявить какой из двух документов соответствует запросу больше. Значение меры сходства определяется по формуле:
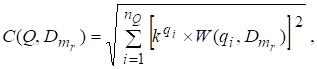
(5).
гдеQ — сделанный системе запрос;
nq — количество слов в запросе Q;
qi — i-ое слово запроса (qi Q; i = 1, … nq);
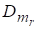
— поисковый образ текстового документа, соответствующего запросу Q (mr = 1, …, Mr; Mr — количество релевантных запросу текстовых документов в безе документов);
Рис. 6. Алгоритм кластеризации информации
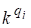
— коэффициент значимости слова qi запроса Q. Значения этого коэффициента задаются пользователем при вводе запроса. Если коэффициент не задан, то он принимается равным 1;
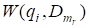
— вес слова qi в документе. Значение веса слова в документе вычисляются по формуле (4) в процессе индексирования документа (см. выше);
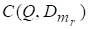
— мера сходства запроса Q и документа .
Блок когнитивного представления базы знаний системы позволяет пользователю представить результат поиска в форме графического изображения. На основе правил данного блока семантическая сеть представляется в виде дерева, различным типам узлов которого сопоставлены информационные пиктограммы и названия. При выборе узла сети, в зависимости от его типа может быть выполнено одно из следующих действий:
если выбран узел-документ, то автоматически отображается перечень соответствующих ему ключевых слов, а также перечень соответствующих документов с целым рядом наборов атрибутов. При выборе документа он загружается в окно просмотра. Все атрибуты документа можно посмотреть в отдельном графическом окне и в случае необходимости внести соответствующие изменения;
Рис. 7. Алгоритм поиска и классификации информации
если выбран узел-документ-папка, то дополнительно к выше описанным действиям может быть выбран просмотр подузлов данного узла с теми же функциональными возможностями;
узлы-ссылки позволяют выполнить автоматический переход в другие участки семантической сети, которые логически сходны с данным участком;
узлы-паки служат только для логического объединения узлов-документов, узлов-документов-папок и узлов-ссылок.
Информация о документах Интернета в системе формирования знаний хранится в хранилище данных. Структурно разработанное хранилище данных по предметной области можно представить в виде куба с измерениями: охват, время и потребность.
В четвертой главе освещаются вопросы разработки программного комплекса автоматизирующего мониторинг и системный анализ распределенной проблемно-ориентированной информации в среде Интернет.
Требования к программному комплексу формируются с учетом разработанных математических моделей и общих принципов построения распределенных информационных систем.
Приводятся архитектура и функциональная схема программного комплекса (ПК ЛОЦМАН) (рис. 8), реализующего программную поддержку математических моделей и семантического моделирования. В разработанном программном комплексе предусмотрен доступ к хранилищу данных и базе знаний, а также интерфейс системы с пользователем.
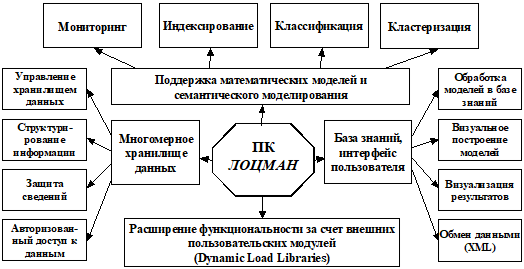
Рис. 8. Функциональная схема программного комплекса Лоцман
При создании системы использовалась среда программирования Borland Delphi 7. В главе рассмотрены вопросы организации хранилища данных с использованием языка XML.
Излагается пользовательский интерфейс системы формирования знаний и схема поиска информации с использованием данной системы пользователем. В завершении главы приводится функциональная схема аппаратных средств, необходимых для функционирования разработанной системы. Анализируются возможные направления развития и пути применения программного комплекса.
В пятой главе освещаются вопросы, связанные с применением программного комплекса автоматизирующего мониторинг и системный анализ распределенной проблемно-ориентированной информации в среде Интернет. Рассматривается практическое применение разработанной системы при инновационной деятельности на предприятии, в образовательном процессе и медицине, а также при проведении мониторинга общественного мнения.
Описано применение разработанной системы формирования знаний при инновационной деятельности на предприятии. Управление инновационной деятельности на предприятии включает несколько взаимосвязанных блоков от маркетинга до производства новых изделий. На каждом из этапов требуется своя специфическая информация из сети Интернет. Система была апробирована при сборе информации о конкурентах предприятия. Разработанная система на основе построенной модели предметной области умеет самостоятельно выявлять новые предприятия на рынке, заносить их в различные классы сформированной модели и предоставлять полученную информацию специалистам в виде удобном для просмотра.
Система формирования знаний экономически эффективна. Заложенные в ней методы, позволяют в значительной степени автоматизировать процесс индексирования и поиска документов. Разработанная система универсальна в том смысле, что подходы, используемые в ней, не зависят от конкретной предметной области. Система может быть настроена на работу с информацией из широкого спектра различных предметных областей. Cистема была апробирована не только в промышленности, но и в медицине. Предложенный в данной работе подход позволяет реализовать эффективный доступ к проблемно-ориентированной информации из больших распределенных неструктурированных массивов информации, в том числе и из сети Интернет.