Распознавание трехмерных объектов

Модульные кодировщики на нейронных сетях используются для несупервизорного распознавания ЗЭ-объектов. Набор модульных кодировщиков автоматически решает задачу кластеризации видов. Кластеризация и кодирование видов реализуются с помощью модульной нейронной сети, которая может выполнять автоматическое распознавание ЗЭ-объектов без учителя. Ее основу составляют нейросетевые модули типа… Читать ещё >
Распознавание трехмерных объектов (реферат, курсовая, диплом, контрольная)
Зрительная система человека способна распознавать трехмерные (3D) объекты по их двумерным (2D) изображениям, которые значительно меняются с точки зрения наблюдателя. Поэтому важной проблемой систем технического зрения (СТЗ), предназначенных для распознавания ЗО-объектов, является способность к выполнению инвариантного к видам распознавания [9].
Традиционный подход — реконструировать ЗD-мoдeль объекта по его 2D-видам и использовать эту модель для распознавания объектов. Однако такой подход связан с существенными вычислительными сложностями. Альтернативно используются подходы, основанные на видах, где ЗО-объекты распознаются прямо из их 2D-b^job (проекций). В этих подходах СТЗ обучается на ограниченном числе видов объекта, чем достигается инвариантное к видам распознавание вследствие свойства генерализации обученной системы. Эти подходы не только эффективны в вычислительном плане, но и адекватны биологическим аналогам. Физиологи показали, что представление 3D-o6beKTOB в зрительной системе человека видоснецифично, т. е. привязывается к точке наблюдения.
Рисунок 19.5 отображает классификацию подходов к распознаванию 3Dобъектов с использованием 3D-моделей (рис. 19.5, а) и 2D-bh, tob (рис. 19.5,6).
Реконструкция ЗО-моделей по видам связана со слиянием изображений от нескольких неподвижных видеокамер или обработкой последовательно появляющихся видов от одной движущейся камеры. При таком объединении используется калибровка каждой камеры, позволяющая убрать искажения при ротации и сдвиге. Так, в пакете Open Computer Vision[1]
в рамках ЗЕ)-реконструкции решаются задачи построения 2[)-видов от виртуальной камеры, расположенной в заданной точке (view morphing), или определения позы известного объекта при слежении с учетом ортографии объекта и масштабирования (POSIT — pose from orthography and scaling). С использованием этих процедур распознавание ЗО-объектов может быть произведено путем сопоставления текущего 20-вида с виртуально генерируемыми 20-видами объекта.
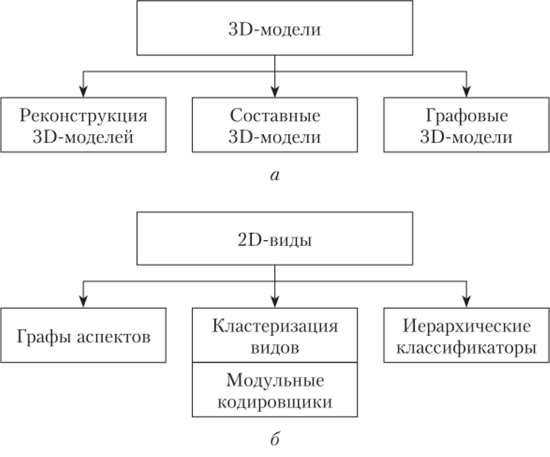
Рис. 19.5. Классификация подходов к распознаванию ЗО-объектов.
Составные и графовые ЗО-модели строятся как аппроксимации сложных ЗО-объектов компонентными объемными примитивами (многогранниками) или ЗО-графами. При распознавании главной и наиболее трудоемкой задачей является сопоставление ЗО-моделей. Это связано с изоморфизмом и топологической эквивалентностью составных или графовых ЗО-моделей.
Подходы к распознаванию ЗО-объектов, такие как графы аспектов, кластеризация видов, модульные кодировщики и иерархические классификаторы, основаны на 20-видах и используют разные пространства признаков, полученные при обработке видов. Распознавание производится путем сопоставления наборов признаков текущего изображения и шаблонов для разных объектов и в разных ракурсах и масштабах.
Графы аспектов, или визуальные потенциалы, используются для распознавания ЗО-объектов. Подход базируется на кластеризации бесконечного набора возможных видов объектов в конечный набор репрезентативных видов или аспектов. В принципе, аспектом может быть любой набор признаков, полученный при обработке 20-видов, инвариантных или относительно инвариантных к некоторому ограниченному размещению точки наблюдения. Но чаще всего виды, которые кластеризуются, предварительно обрабатываются путем проецирования на план изображения краев многогранных объектов или их поверхностей (при этом получаются изображения из линий — проволочные модели). Репрезентативные виды образуются путем разбиения пространства видов на равные части или на части, учитывающие топологию объекта.
В графе аспектов каждый узел является аспектом, а каждая дуга представляет изменение или преобразование вида при переходе к другому аспекту. Таким образом, граф аспектов является дуальным графом, описывающим пространство наблюдений объекта. Метод распознавания базируется на сопоставлении графов аспектов шаблона и текущего объекта. Здесь решается сложная в вычислительном отношении задача изоморфизма графов и их топологической эквивалентности.
Для распознавания должны быть созданы графы аспектов шаблонов по одному для каждого наблюдаемого (классифицируемого) объекта. Из текущего 20-изображения создается проволочная модель наблюдаемого объекта, которая топологически сравнивается с запомненными аспектами графов аспектов шаблонов. Если одно или более сопоставлений будут найдены только в одном графе аспектов, объект считается распознанным. Иначе наблюдение объекта продолжается при перемещении точки наблюдения (при изменении ракурса). Это перемещение дает последовательность топологически различных проволочных моделей объекта, которые должны быть сопоставлены с последовательностью аспектов в разных графах аспектов шаблонов. Такое активное топологическое сопоставление продолжается до ситуации, когда оно будет уверенно обеспечиваться только для одного графа шаблонов. Эта ситуация означает идентификацию объекта, определяемого этим шаблоном. Заметим, что топологическая идентификация является по природе приближенной и обладает значительной вычислительной сложностью.
Кластеризация видов — другой подход к ЗЭ-распознаванию, который подразумевает обобщение появляющихся видов с учетом топологической структуры объекта. Обобщенные виды затем подвергаются процедурам 20-расиознавания, например с использованием ранее рассмотренного преобразования типа ППИМ.
Модульные кодировщики на нейронных сетях используются для несупервизорного распознавания ЗЭ-объектов. Набор модульных кодировщиков автоматически решает задачу кластеризации видов. Кластеризация и кодирование видов реализуются с помощью модульной нейронной сети, которая может выполнять автоматическое распознавание ЗЭ-объектов без учителя. Ее основу составляют нейросетевые модули типа автокодировщиков. Каждый модуль реализует нелинейное преобразование, подобное АГК, в результате чего изображение (или набор признаков) сжимается, и на выходе получается его низкоразмерное представление.
Автокодировщик построен как автоассоциативная пятислойная нейронная сеть, которая находит идентичное, но сжатое отображение, используя «узкое горло» в среднем скрытом слое, имеющем меньшее число нейронов, чем во входном и выходном слоях. По существу, такая сеть снимает избыточность входных данных и за счет этого редуцирует их размерность.
Эти сжатые представления от группы автокодировщиков кластеризуются по видам ЗО-объектов, снятым в разных ракурсах и позах. Модули авгокодировщиков обучаются кодировать и декодировать различные виды разных объектов.
При распознавании 3D-объектов обученный модуль может возвратить все виды только одного объекта. Тогда возможно идентифицировать любой входной вид как объект путем выбора модуля, выходной вид которого наилучшим образом соответствует входному виду. Это реализуется расположенным на выходе системы соревновательным классификатором. Если один из модулей имеет выход, который наилучшим образом сопоставляется с входом, то выходное значение соответствующей единицы классификатора станет близким к единице, а выходные значения других единиц станут близкими к нулю.
Иерархическая классификация SD-объектов по 2D-видам реализуется с использованием многоуровневой сети легковесных классификаторов невысокой точности, работающих с разными пространствами признаков и обученными на детектирование каждый своего вида объекта. Каждый узел такой сети является локальным классификатором, настроенным на свой класс объекта, свой 2D-вид этого объекта и свое пространство признаков.
Пример иерархической системы распознавания
Система, структура которой представлена на рис. 19.6, предназначена для классификации 4 классов объектов (автомобили разных типов) по 4 углам наблюдения (спереди, слева, справа, сзади) и 3 признаковым пространствам (графовое, вейвлеты и ППИМ) 19]. Система обучалась на множестве видов объектов, которые отбирались вручную из последовательности кадров, полученных путем видеосъемки.
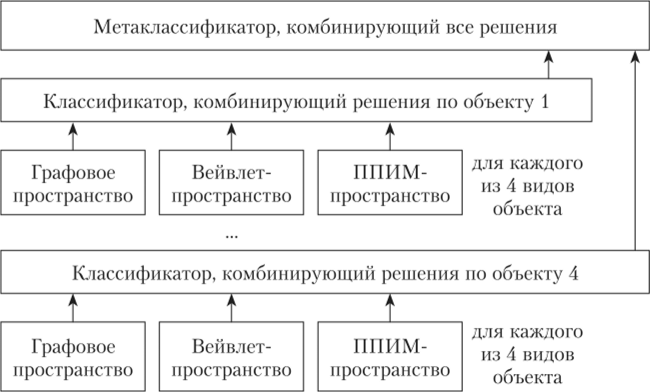
Рис. 19.6. Иерархический классификатор .'Ш-объектов
Сеть включала 48 локальных классификаторов (4 • 4 • 3), причем каждый локальный классификатор обучался распознаванию объектов определенного класса и характеризовался тремя измерениями: 1) класс объектов, на которые он настроен; 2) угол наблюдения за собственным объектом; 3) признаковое пространство, возможно с разными параметрами настройки.
Решение каждого локального классификатора при обработке изображения индицируемого пространства формировалось в 5 ситуациях: 1) решение есть и оно соответствует существованию объекта его класса; 2) решение есть, но в индицируемом пространстве располагается объект другого класса; 3) решение есть, но нет объекта интереса; 4) решения нет, но объект «собственного» класса существует; 5) решения нет и пет объекта «собственного» класса.
Комбинирование этих решений от множества локальных классификаторов для каждого класса объектов сначала производит классификатор объекта, а затем их обобщает метаклассификатор. Эти классификаторы построены на правилах. Они представляют верхние уровни системы распознавания. Сначала отфильтровываются слабые решения, которые не превысили установленный порог, но вероятности решения, а затем комбинируются оставшиеся решения и получается общее решение системы. Для этого классификаторы объектов и метаклассификатор настраиваются с использованием специальной процедуры обучения с голосованием и супервизором, показывающим правильные комбинации решений для отдельных объектов и системы в целом.
- [1] См.: http://opencv.org