Метрики релевантности.
Разработка программного продукта для решения задач бикластерного анализа англоязычных текстов

Где — длина документа d в словах, а — средняя длина документов в коллекции D. Здесь и b являются настраиваемыми параметрами. Можно заметить, что от величины зависит вес — частоты слова — в метрике: при значении, равном нулю, частота слова, как и длина документа, не учитываются вовсе, тогда как большое значение параметра приводит метрику к виду практически идентичному метрике TF-IDF. Аналогично… Читать ещё >
Метрики релевантности. Разработка программного продукта для решения задач бикластерного анализа англоязычных текстов (реферат, курсовая, диплом, контрольная)
Интуитивно понятно, что чем чаще некоторое слово встречается в тексте, тем оно более релевантно для этого текста. Отсюда получаем базовую метрику релевантности:
.
где — это количество вхождений слова w в текст d. Однако такая метрика, например, для слова the в англоязычном тексте, скорее всего, даст очень высокое значение, тогда как значимость этого слова при анализе текста чаще всего очень мала. Далее в этом разделе мы рассмотрим несколько более сложных метрик, хорошо себя зарекомендовавших в практических приложениях.
1) TF-IDF.
Пожалуй, самой известной и распространённой метрикой релевантности слово-текст является TF-IDF (Term Frequency — Inverse Document Frequency). В основу этой метрики легла идея о том, что слова, встречающиеся в малом количестве текстов, скорее всего, несут в себе больше информации и лучше отражают назначение текстов, по сравнению с широко используемыми словами — как уже много раз упомянутое слово the. Таким образом, появилась концепция IDF, которая в какой-то степени отражает «вес» слова в коллекции текстов:
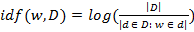
.
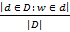
где D — коллекция документов (текстов). Отношение под логарифмом в явном виде отражает широту использования слова w. Данную формулу также иногда интерпретируют как собственную информацию, которую несёт слово w, для данной коллекции. Это следует из того, что отношение можно рассматривать, как условную вероятность появления слова w в тексте — Pw, тогда собственная информация этого события будет равна:
.
Общая формула для подсчёта релевантности по метрике TF-IDF выглядит следующим образом:
.
Эта метрика хорошо себя зарекомендовала себя для ранжирования документов по поисковому запросу.
2) Okapi BM25.
Так же, как и TF-IDF, метрика Okapi BM25 — далее просто BM25 — является эвристической моделью, которая, помимо уже рассмотренных компонентов tf и idf, также учитывает длину текста. В дополнение, BM25 включает в себя два настраиваемых параметра, назначение которых можно будет скоро увидеть. Чаще всего данная метрика записывается в следующем виде:
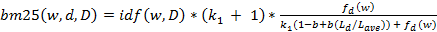
.
где — длина документа d в словах, а — средняя длина документов в коллекции D. Здесь и b являются настраиваемыми параметрами. Можно заметить, что от величины зависит вес — частоты слова — в метрике: при значении, равном нулю, частота слова, как и длина документа, не учитываются вовсе, тогда как большое значение параметра приводит метрику к виду практически идентичному метрике TF-IDF. Аналогично, параметр b влияет на «значимость» длины документа d относительно средней длины по коллекции. При b = 0, метрика не учитывает относительную длину документа, тогда как при b = 1, относительная длина имеет наиболее значительный вклад в подсчёт релевантности. При выборе значений этих двух параметров рекомендуется выбирать из отрезка и b = 0,75.
3) Метод АСД.
Метод Аннотированного Суффиксного Дерева (АСД) довольно сильно отличается от уже рассмотренных методов. В первую очередь, данный метод обрабатывает тексты не как набор слов, а как последовательность символов, что делает метод более гибким. В то же время, при оценке степени вхождения ключевого словосочетания или слова в конкретный текст, не учитываются другие тексты из коллекции, как это делается в TF-IDF и BM25.
Суффиксное дерево — это дерево, хранящее все суффиксы некоторой строки в виде последовательности символов.
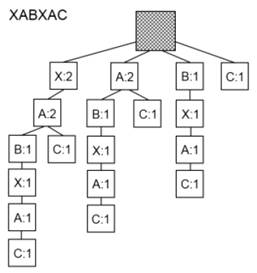
Рисунок 1. Аннотированное суффиксное дерево для строки XABXAC.
На рисунке 1 один представлено суффиксное дерево, построенное для строки XABXAC. Это дерево отличается от суффиксных деревьев стандартного вида тем, что каждой вершине в этом дереве (кроме корня) присвоено число, которое обозначает количество вхождений подстроки — образованной цепочкой символов от корня к вершине — в начальную строку XABXAC. Такое дополнение к базовому варианту суффиксных деревьев позволяет построить метрику релевантности.
Для того, чтобы ввести эту метрику нужно сначала ввести несколько понятий. Условной вероятностью вершины v будем называть, где f (v) — это частота, присвоенная вершине v, а parent (v) — родительская вершина для v. Теперь, если мы хотим рассчитать степень вхождения подстроки s в дерево A, то сперва нужно найти цепочку максимальной длины от корня дерева к некоторой вершине (…), которая совпадает с префиксом подстроки s. Теперь:
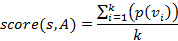
Для того, чтобы подсчитать степень вхождения всей строки S в дерево A необходимо сперва оценить степень вхождения всех её суффиксов в A, после чего объединить их по формуле:
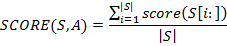
Подводя итог по методу, стоит отметить, что он получил применение в задаче фильтрации спама, и показал хорошие результаты при рубрикации научных статей.
4) Методы подсчёта метрик релевантности.
Разработанное программное обеспечение предоставляет пользователю возможность выбирать одну из метрик TF-IDF, BM25 или метод АСД. Также могут использоваться простые метрики: количество вхождения слова/фразы в текст и количество вхождений в текст, делённое на длину текста без учёта слов из стоп-листа.
При подсчёте всех метрик, в которых тексты представляются в формате «мешка слов» (то есть всех перечисленных выше, кроме метода АСД), тексты из коллекции предварительно обрабатываются. Для этого был разработан следующий подход: для каждого текста составляется хеш-таблица, где ключём выступает основа (стем) слова, — фрагменты слов, полученные удалением аффиксов — а значением является массив индексов. Такой массив содержит порядковые индексы тех слов в тексте, основы которых совпадают с ключем.
Например, в предложении «Development of an effective cluster validity measure with outlier detection and cluster merging algorithms for support vector clustering» три раза встречается основа «cluster» (один раз в изменённой форме «clustering»). Соответственно, если нумеровать слова в предложении с нуля, то массив индексов для основы «cluster» будет содержать индексы {4, 11, 17}. Важно отметить, что массивы индексов в хеш-таблицах упорядочены по возрастанию (что получается естественным образом, так как данные массивы заполняются по мере прохождения циклом по всем словам в тексте) Такое представление текстов было выбрано в связи с тем, что массивы индексов для разных основ слов легко объединять в единый упорядоченный список, пользуясь которым можно быстро находить вхождения ключевых словосочетаний в текст. Допустим, необходимо найти количество вхождений словосочетания «cluster validity» в рассмотренное выше предложение. Для этого посмотрим в хэш-таблицу на основы слов «cluster» и «valid» и объединим массивы индексов:
Таблица 1. Массивы индексов.
«cluster». | «valid». | Объединённый массив. |
{4, 11, 17}. | {5}. | {4, 5, 11, 17}. |
После объединения массивов необходимо найти все группы последовательных индексов нужной длины (в данном случае длины 2, так как ключевое словосочетание состоит из двух слов) и проверить, действительно ли они составляют вместе ключевое словосочетание. В данном примере присутствует только одна такая группа — (4, 5) — которая как раз соответствует ключевому словосочетанию «cluster validity». Заметим, что при поиске в предложении изменённых словосочетаний, таких как «clustering validity» или «clustering validation», в данном примере также найдётся вхождение, так как проверяются не сами слова, а их основы.
Такой подход позволяет при нахождении вхождений ключевого словосочетания в текст, сканировать не весь текст целиком, а только индексы слов, входящих в это словосочетание. Это сильно повышает эффективность алгоритма, ведь задача объединения k упорядоченных списков имеет линейную сложность относительно суммы длин этих списков.
Возвращаясь к методу АСД: для подсчёта релевантности по этому методу используется линейный алгоритм, представленный Михаилом Дубовым в 2014 году, и реализованный в модуле для языка Python — EAST.
Что касается ключевых словосочетаний, предоставляемых библиотекой IEEE Xplore, при анализе аннотаций к научным статьям, метрики релевантности не использовались. Вместо этого матрицы релевантности фраза/текст строились, как бинарные, то есть для каждой статьи помечались единицей те словосочетания, которые были указаны авторами самой статьи или были выбраны специалистами при индексации в базе данных Inspec.