Предлагаемые методы и математическое обеспечение

В первом случае кластер представляет четыре независимых уникальных объекта (a, b, c, d), которые входят в кластер количеством (3, 2, 2, 1) соответственно. Таким образом, кластер имеет ширину W=4, то есть включает в себя 4 типа объектов. Площадью S будем считать вхождение в кластер всех объектов, то есть S=3+2+2+1=8. Зная два этих параметра можно рассчитать высоту кластера H=S/W=8/4=2. Если тоже… Читать ещё >
Предлагаемые методы и математическое обеспечение (реферат, курсовая, диплом, контрольная)
Методы кластеризации
CLOPE.
Алгоритм CLOPE является алгоритмом кластеризации транзакционных данных. Транзакция в данном контексте — это произвольный набор объектов. То есть в конкретном случае транзакция похожа на кортеж в котором могут находить нетипизированные данные, не имеющие никой связи между собой, и, не выстраиваемые в пространстве. Задача кластеризации подобных данных состоит в получении такого разбиения, чтобы схожие транзакции находились в одном кластере, а отличные — в одном из других. Для этого в алгоритме применяется принцип максимизации глобальной функции стоимости[ссылка], сближающей транзакции в кластерах, увеличивая параметр кластерной гистограммы.
Например, для набора транзакций {(a, b), (a, b, c), (a, c, d), (d, e), (d, e, f)} сравним два разбиения на кластеры:
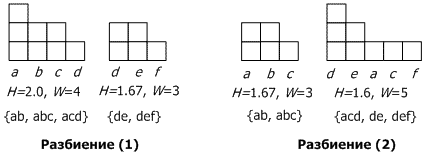
Рис. 5.1 Разбиение кластеризацией CLOPE
В первом случае кластер представляет четыре независимых уникальных объекта (a, b, c, d), которые входят в кластер количеством (3, 2, 2, 1) соответственно. Таким образом, кластер имеет ширину W=4, то есть включает в себя 4 типа объектов. Площадью S будем считать вхождение в кластер всех объектов, то есть S=3+2+2+1=8. Зная два этих параметра можно рассчитать высоту кластера H=S/W=8/4=2. Если тоже самое проделать с остальными с кластерами, то мы увидим, что при одинаковом количестве элементов в кластере параметры H, W, S могут произвольно меняться. Если посмотреть оба разбиения, то можно понять, что разбиение 1 выгоднее, так как обеспечивает большее число меньшее количество уникальных объектов и большее число наложений. Именно в этом заключается принцип максимизации стоимости.
Пусть D — множество транзакций {t1,…, tn}, где t — набор объектов {i1,…, in}. Найти такое множество кластеров {C1,…, Ck} для множества {t1,…, tn}, такое что.
Гистограмма кластера — это графическое изображение его расчетных характеристик.
Алгоритм должен учитывать высоту H при разбиении, потому что транзакция, максимально увеличивающая площадь по отношению к другим существующим кластерам, не увеличивая ширины, наиболее подходит к уже содержащимся в кластере транзакциям. Но оценка высоты не является эффективным критерием в случае разбиений с одинаковой высотой, например H=1. В таком случае вместо оценки высоты необходимо вычислять градиент G (C)=H (C)/W (C)=S (C)/W©.
Обобщая, выведем формулу глобального критерия.
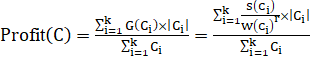
(5.1.1.2).
Где |Ci| - количество объектов в i-м кластере.
k — количество кластеров.
r — коэффициент отталкивания (repulsion), положительно вещественное число превосходящее 1.
При помощи коэффициента отталкивания определяется степень сходства транзакций в кластере, причём зависимость обратно пропорциональна, то есть с повышением значения коэффициента, снижается показатель схожести транзакций при сравнении, и тем самым увеличивается количество кластеров.
Таким образом, постановка задачи кластеризации для алгоритма CLOPE выглядит так:
Работа алгоритма проходит методом итеративного перебора записей базы данных, а глобальность критерия оптимизации, основанном на расчете параметров кластеров, позволяет обрабатывать данные значительно быстрее, чем в сравнении транзакций между собой.
Алгоритм работает в два этапа. На первом этапе происходит первый проход по базе с целью инициализации данных и построения первичного разбиения. Второй этап осуществляет итеративные обходы базы, оптимизируя функцию стоимости до прекращения изменений в кластерной структуре.
Вполне очевидно, что CLOPE — масштабируемый алгоритм, способный работать на ограниченных ресурсах. Во время его работы в памяти находится только текущая транзакция и кластерные характеристики (CF — cluster features). При вхождении 10 000 объектов в 1 000 кластер требуется всего около 40 Мб памяти для хранения данной информации.
Вычислительная сложность алгоритма возрастает линейно с увеличением таблицы и ростом числа кластеров, она равна O (N*K*A), где.
N — общее число транзакций;
K — максимальное число кластеров;
A — средняя длина транзакции.
Таким образом алгоритм относится к эффективным на большим объёмах данных.
Данный алгоритм можно успешно применять не только для транзакционных данных, но и для любых категорийных. Основным требованием является нормализация данных. Это может быть бинарная матрица или отображение уникальных объектов {u1, u2, …, uq} и множеством целых чисел {1, 2, …, q}. Таким образом к виду транзакции можно свести любой набор данных, поэтому CLOPE находит своё место в обработке категорийных данных.
K-meanes.
Теперь рассмотрим подробно самый популярный и простой в реализации алгоритм k-means. Этот алгоритм был открыть в различных дисциплинах Ллойдом (1957), Форджи (1965), Фридманом и Рубином (1967), а так же МакКуином (1967).
K-means применим к объектам в d-мерном векторном пространстве, представимых как набор D = {xi | i=1, …, N}, где xi? Rd — i-й объект. Суть алгоритма состоит в объединении D так, чтобы каждая xi попала только в один k раздел. В результате образуется кластерный составной вектор m длиною N, где mi — номер кластера xi. Параметр k — входное значение для работы алгоритма и является конечным числом кластеров. Этот параметр является экспертным вводом, основанным на наблюдениях, анализе предварительных результатов или просто интуитивном предпочтении аналитика. Неважно каким будет значение k для понимание разделения набора данных, но оптимальное значение достигается путём ряда итеративных экспериментов.
В работе алгоритма каждый кластер представлен точкой в Rd и представляется как множество C={cj | j=1, …, k}. Эти состояния называют центроидами кластера. Для кластеризации применяются меры близости, в частности евклидово расстояние, уже рассмотренное ранее. Работа алгоритма заключается в минимизации функции стоимости, которая представлена как квадрат расстояния между каждой точкой xi и ближайшим представителем кластера cj.
(5.1.2.1).
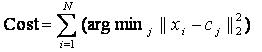
Приведённое уравнение часто называют целевой функцией k-means.
Алгоритм строится в 2 шага, которые итеративно чередуются между собой:
- 1. Переписывание номера кластера для всех объектов в D
- 2. Обновление данных кластера по содержащимся в нём объектам
Сначала инициализируются представители кластера, но основании выборки k из Rd случайным образом, устанавливая их как решения подмножества, либо нарушая среднее значение данных k-раз. Затем выполняется итерации до сходимости за 2 шага:
- 1. Каждому объекту присваивается самый близкий представитель, произвольно нарушая связи данных, что приводит к их разделению;
- 2. Центроид кластера перемещается на место среднего арифметического всех объектов в кластере.
Алгоритм сходится при невозможности осуществлять перемещения. Таким образом целевая функция уменьшается с каждым шагом, а сближение гарантировано за конечное число итераций.
К сожалению значение целевой функции не информативно с точки зрения подбора количества кластеров, потому что функция стоимости принимает минимальное значение в том случае, когда число кластеров равно числу объектов.
Реализация алгоритма:
- 1. Выберем случайным образом k точек из D как представителей класса C в соответствии с формулой (1)
- 2. Вычислим центр для каждого кластера
- 3. Перераспределим объекты по кластерам
Каждая итерация в таком случае будет иметь сложность O (N*k), а число итераций, необходимых неизвестно, но растёт с числом объектов N. Решение проблемы скорости в данном случае может быть предложено путём распределения вычислений на потомки, в этом случае необходимо разбить множество данных на P частей равному по значению количеству потоков, а каждый поток будет работать со своим набором данных.
Актуальной проблемой разбиения является проблема «пустых кластеров». Этот недостаток усиливается с увеличением числа k, когда в момент работы образуется центройд кластера cj, такой, что все точки xi в D оказываются ближе к центроиду другого кластера. В таком случае точки перераспределятся, а исходному кластеру будут назначены нулевые значения, образуя из него пустое множество. В таком случае необходимо предусмотреть переинициализацию центроида пустого кластера.
Несмотря на недостатки, алгоритм k-means является наиболее распространённым инструментом кластеризации на практике. Это простой и масштабируемый метод, который обладает достаточной эффективностью и способен работать как дополнение к более сложным методам, что я рассмотрю далее.
BIRCH.
Алгоритм BIRCH представляет из себя двухэтапный процесс кластеризации, который хорошо кластеризует большие наборы числовых данных. Ранее был рассмотрен алгоритм k-means, который предполагается использовать как второй этап в данном методе. Хорошая связь этих методов состоит в том, что они оба работают с числовыми данными и строят кластеры сферических форм. Для работы алгоритма BIRCH необходимо только указание пороговых значений, а количество кластеров, необходимое для k-means будет определено во время первого этапа.
Рассмотрим работу алгоритма:
Построение начального CF-дерева (CF Tree, кластерное дерево). Кластерное дерево — это взвешенно сбалансированное двухпараметрическое дерево, где Bкоэффициент разветвления, а T — пороговая величина. Каждый узел, не являющийся листом дерева, имеет не более B вхождений узлов, представленных в форме [CFi, Childi], где i=1, …, B; а Childi — указатель на дочерний i-й узел. Лист дерева имеет указатель на два соседних узла, а радиус кластера, состоящего из элементов этого узла не должен превосходить пороговое значение.
Кластер представляется как тройка (N, LSS, SS), где N — число элементов входных данных кластера, LS — сумма элементов входных данных, SS — сумма квадратов элементов входных данных.
Сжатие данных (необязательный этап) осуществляется перестроением кластерного дерева с увеличением пороговой величины T.
Глобальная кластеризация происходит применением выбранного алгоритма кластеризации на листьевых компонентах кластера. В выбранном случае здесь вступает в работу алгоритм K-means, с полученным на предыдущих этапах числом кластеров.
Улучшение кластеров (необязательный этап) использует центры тяжести, полученные в результате глобальной кластеризации, перераспределяя данные между «близкими» кластерами. Данный этап гарантирует что одинаковые данные попадут в один кластер.