Теоретические основы кодирования информации

Пусть имеется сообщение, записанное при помощи некоторого «алфавита», содержащего п «букв». Требуется «закодировать» это сообщение, т. е. указать правило, сопоставляющее каждому такому сообщению определенную последовательность из т различных «элементарных сигналов», составляющих «алфавит» передачи. Мы будем считать кодирование тем более выгодным, чем меньше элементарных сигналов приходится… Читать ещё >
Теоретические основы кодирования информации (реферат, курсовая, диплом, контрольная)
Основы и основные понятия кодирования информации
Рассмотрим основные понятия, связанные с кодированием информации. Для передачи в канал связи сообщения преобразуются в сигналы. Символы, при помощи которых создаются сообщения, образуют первичный алфавит, при этом каждый символ характеризуется вероятностью его появления в сообщении. Каждому сообщению однозначно соответствует сигнал, представляющий определенную последовательность элементарных дискретных символов, называемых кодовыми комбинациями.
Кодирование — это преобразование сообщений в сигнал, т. е. преобразование сообщений в кодовые комбинации. Код — система соответствия между элементами сообщений и кодовыми комбинациями. Кодер — устройство, осуществляющее кодирование. Декодер — устройство, осуществляющее обратную операцию, т. е. преобразование кодовой комбинации в сообщение. Алфавит — множество возможных элементов кода, т. е. элементарных символов (кодовых символов) X = {xi}, где i = 1, 2,…, m. Количество элементов кода — m называется его основанием. Для двоичного кода xi = {0, 1} и m = 2. Конечная последовательность символов данного алфавита называется кодовой комбинацией (кодовым словом). Число элементов в кодовой комбинации — n называется значностью (длиной комбинации). Число различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Цели кодирования:
- 1) Повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
- 2) Повышение помехоустойчивости при передаче данных.
В соответствии с этими целями теория кодирования развивается в двух основных направлениях:
- 1. Теория экономичного (эффективного, оптимального) кодирования занимается поиском кодов, позволяющих в каналах без помех повысить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи данных с пропускной способностью канала связи.
- 2. Теория помехоустойчивого кодирования занимается поиском кодов, повышающих достоверность передачи информации в каналах с помехами.
Научные основы кодирования были описаны К. Шенноном, который исследовал процессы передачи информации по техническим каналам связи (теория связи, теория кодирования). При таком подходе кодирование понимается в более узком смысле: как переход от представления информации в одной символьной системе к представлению в другой символьной системе. Например, преобразование письменного русского текста в код азбуки Морзе для передачи его по телеграфной связи или радиосвязи. Такое кодирование связано с потребностью приспособить код к используемым техническим средствам работы с информацией.
Декодирование — процесс обратного преобразования кода к форме исходной символьной системы, т. е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке.
В более широком смысле декодирование — это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение — это декодирование.
Способ кодирования одного и того же сообщения может быть разным. Например, русский текст мы привыкли записывать с помощью русского алфавита. Но то же самое можно сделать, используя английский алфавит. Иногда так приходится поступать, посылая SMS по мобильному телефону, на котором нет русских букв, или отправляя электронное письмо на русском языке из-за границы, если на компьютере нет русифицированного программного обеспечения. Например, фразу: «Здравствуй, дорогой Саша!» приходится писать так: «Zdravstvui, dorogoi Sasha!».
Существуют и другие способы кодирования речи. Например, стенография — быстрый способ записи устной речи. Ею владеют лишь немногие специально обученные люди — стенографисты. Стенографист успевает записывать текст синхронно с речью говорящего человека. В стенограмме один значок обозначал целое слово или словосочетание. Расшифровать (декодировать) стенограмму может только стенографист.
Приведенные примеры иллюстрируют следующее важное правило: для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от ряда обстоятельств: цели кодирования, условий, имеющихся средств. Если надо записать текст в темпе речи — используем стенографию; если надо передать текст за границу — используем английский алфавит; если надо представить текст в виде, понятном для грамотного русского человека, — записываем его по правилам грамматики русского языка.
Еще одно важное обстоятельство: выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Покажем это на примере представления чисел — количественной информации. Используя русский алфавит, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, пишем: «35». Второй способ не только короче первого, но и удобнее для выполнения вычислений. Какая запись удобнее для выполнения расчетов: «тридцать пять умножить на сто двадцать семь» или «35×127»? Очевидно — вторая.
Однако если важно сохранить число без искажения, то его лучше записать в текстовой форме. Например, в денежных документах часто сумму записывают в текстовой форме: «триста семьдесят пять руб.» вместо «375 руб.». Во втором случае искажение одной цифры изменит все значение. При использовании текстовой формы даже грамматические ошибки могут не изменить смысла. Например, малограмотный человек написал: «Тристо семдесять пят руб.». Однако смысл сохранился.
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука под названием криптография.
Пусть имеется сообщение, записанное при помощи некоторого «алфавита», содержащего п «букв». Требуется «закодировать» это сообщение, т. е. указать правило, сопоставляющее каждому такому сообщению определенную последовательность из т различных «элементарных сигналов», составляющих «алфавит» передачи. Мы будем считать кодирование тем более выгодным, чем меньше элементарных сигналов приходится затратить на передачу сообщения. Если считать, что каждый из элементарных сигналов продолжается одно и то же время, то наиболее выгодный код позволит затратить на передачу сообщения меньше всего времени.
Главным свойством случайных событий является отсутствие полной уверенности в их наступлении, создающее известную неопределенность при выполнении связанных с этими событиями опытов. Однако совершенно ясно, что степень этой неопределенности в различных случаях будет совершенно разной. Для практики важно уметь численно оценивать степень неопределенности самых разнообразных опытов, чтобы иметь возможность сравнить их с этой стороны. Рассмотрим два независимых опыта и, а также сложный опыт, состоящий в одновременном выполнении опытов и. Пусть опыт имеет k равновероятных исходов, а опыт имеет l равновероятных исходов. Очевидно, что неопределенность опыта больше неопределенности опыта, так как к неопределенности здесь добавляется еще неопределенность исхода опыта. Естественно считать, что степень неопределенности опыта равна сумме неопределенностей, характеризующих опыты и, т. е.
.
Условиям:
.
при удовлетворяет только одна функция — :
.
Рассмотрим опыт А, состоящий из опытов и имеющих вероятности. Тогда общая неопределенность для опыта, А будет равна:
Это последнее число будем называть энтропией опыта и обозначать через .
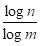
Если число букв в «алфавите» равно п, а число используемых элементарных сигналов равно т, то при любом методе кодирования среднее число элементарных сигналов, приходящихся на одну букву алфавита, не может быть меньше чем; однако он всегда может быть сделано сколь угодно близким к этому отношению, если только отдельные кодовые обозначения сопоставлять сразу достаточно длинными «блоками», состоящими из большого числа букв.
Мы рассмотрим здесь лишь простейший случай сообщений, записанных при помощи некоторых п «букв», частоты проявления которых на любом месте сообщения полностью характеризуется вероятностями р1, р2, … …, рп, где, разумеется, р1 + р2 + … + рп = 1, при котором вероятность pi проявления i-й буквы на любом месте сообщения предполагается одной и той же, вне зависимости от того, какие буквы стояли на всех предыдущих местах, т. е. последовательные буквы сообщения независимы друг от друга. На самом деле в реальных сообщениях это чаще бывает не так; в частности, в русском языке вероятность появления той или иной буквы существенно зависит от предыдущей буквы. Однако строгий учет взаимной зависимости букв сделал бы все дельнейшие рассмотрения очень сложными, но никак не изменит будущие результаты.
Мы будем пока рассматривать двоичные коды; обобщение полученных при этом результатов на коды, использующие произвольное число т элементарных сигналов, является, как всегда, крайне простым. Начнем с простейшего случая кодов, сопоставляющих отдельное кодовое обозначение — последовательность цифр 0 и 1 — каждой «букве» сообщения. Каждому двоичному коду для п-буквенного алфавита может быть сопоставлен некоторый метод отгадывания некоторого загаданного числа х, не превосходящего п, при помощи вопросов, на которые отвечается лишь «да» (1) или «нет» (0), что и приводит нас к двоичному коду. При заданных вероятностях р1, р2, … …, рп отдельных букв передача многобуквенного сообщения наиболее экономный код будет тот, для которого при этих именно вероятностях п значений х среднее значение числа задаваемых вопросов (двоичных знаков: 0 и 1 или элементарных сигналов) оказывается наименьшим.
Прежде всего, среднее число двоичных элементарных сигналов, приходящихся в закодированном сообщении на одну букву исходного сообщения, не может быть меньше Н, где Н = - p1 log p1 — p2 log p2 — … — pn log pn — энтропия опыта, состоящего в распознавании одной буквы текста (или, короче, просто энтропия одной буквы). Отсюда сразу следует, что при любом методе кодирования для записи длинного сообщения из М букв требуется не меньше чем МН двоичных знаков, и никак не может превосходить одного бита.
Если вероятности р1, р2, … …, рп не все равны между собой, то Н < log n; поэтому естественно думать, что учет статистических закономерностей сообщения может позволить построить код более экономичный, чем наилучший равномерный код, требующий не менее М log n двоичных знаков для записи текста из М букв.