Математические основы бизнес-аналитики

Предположим, что прогнозируемый столбец содержит только два состояния, и необходимо провести регрессионный анализ, сопоставляя входные столбцы с вероятностью того, что прогнозируемый столбец будет содержать конкретное состояние. Результаты, полученные методами линейной и логистической регрессии, представлены на рисунке 20"А" и 20"В" соответственно. Линейная регрессия не ограничивает значения… Читать ещё >
Математические основы бизнес-аналитики (реферат, курсовая, диплом, контрольная)
Математические основы оперативного анализа данных.
Существующие математические модели многомерных OLAP-систем обладают следующими недостатками, касающимися формальной структуры этих моделей.
- 1) Моделирование запросов к многомерной БД с помощью преобразования их в эквивалентные реляционные выражения или логические формулы делает невозможным выполнение произвольной последовательности операций.
- 2) Множественное наследование в иерархиях затрудняет реорганизацию иерархической структуры, так как одна и та же вершина может принадлежать различным путям агрегации, имеющим различные агрегирующие функции.
- 3) В процессе эволюции многомерной базы данных возникают семантические конфликты вследствие различных отношений «родительпотомок» для нескольких вершин, являющихся родительскими для одного и того же потомка.
- 4) Структура измерения допускает разбиение всего множества его значений на пересекающиеся подмножества, что может привести к некорректному агрегированию.
Статья, опубликованная в 1993 году Е. Ф. Коддом, включала 12 правил, которые теперь хорошо известны. В 1995 году к ним были добавлены еще шесть.
Основные особенности:
F1: Многомерное концептуальное представление данных (Оригинальное правило 1). Эта особенность — сердцевина OLAP.
F2: Интуитивное манипулирование данными (Оригинальное правило 10). Чтобы манипулирование данными осуществлялось посредством прямых действий над ячейками в режиме просмотра без использования меню и множественных операций.
F3: Доступность (Оригинальное правило 3). OLAP как посредник. OLAP в качестве прослойки между гетерогенными источниками данных и представлением для конечного пользователя.
F4: Пакетное извлечение против интерпретации (Новое). Это правило требует, чтобы продукт в равной степени эффективно обеспечивал доступ, как к собственному хранилищу данных, так и к внешним данным.
F5: Модели анализа OLAP (Новое). OLAP продукты поддерживают все четыре модели анализа, которые Кодд описывает в своей статье (Категориальный, Толковательный, Умозрительный и Стереотипный). Все OLAP инструменты поддерживают первые два, большинство поддерживают третий в той или иной степени, и лишь некоторые поддерживают четвертый в отдельных полезных расширениях.
F6: Архитектура «клиент-сервер» (Оригинальное правило 5). Чтобы продукт был не только клиент-серверным, но и чтобы серверный компонент был бы достаточно интеллектуальным для того, чтобы различные клиенты могли подключаться с минимумом усилий и программирования. Это требование существенно сильнее, чем просто архитектура клиент-сервер, и относительно небольшое количество продуктов удовлетворяют ему.
F7: Прозрачность (Оригинальное правило 2). Полное соответствие ему означает, что пользователь электронной таблицы способен получить все необходимые данные из OLAP — машины, даже не подозревая, откуда они, в конечном счете, берутся. Чтобы выполнить это, продукт должен обеспечивать непосредственный живой доступ к гетерогенным источникам данных и одновременно иметь встроенную полнофункциональную электронную таблицу.
F8: Многопользовательская поддержка (Оригинальное правило 8). Не все OLAP приложения работают только в режиме чтения данных, и этим правилом Кодд указывает стратегическое направление развития. Инструменты OLAP должны обеспечивать одновременный доступ (чтение и запись), интеграцию и конфиденциальность.
Специальные особенности:
F9: Обработка ненормализованных данных (Новое). Оно указывает на необходимость интеграции между OLAP-машиной и ненормализованными источниками данных. То есть модификации данных, выполненные в среде OLAP, не должны приводить к изменениям данных, хранимых в исходных внешних системах.
F10: Сохранение результатов OLAP: хранение их отдельно от исходных данных (Новое). Кодд придерживается распространенного мнения о том, что OLAP приложения, работающие в режиме чтения-записи не должны воздействовать напрямую на обрабатываемые данные. И данные, модифицированные в OLAP, должны сохраняться отдельно от данных транзакций.
F11: Исключение отсутствующих значений (Новое). Все отсутствующие значения отбрасываются в представлении.
F12: Обработка отсутствующих значений (Новое). Все отсутствующие значения будут игнорироваться OLAP анализатором без учета их источника. Эта особенность связана с F11 и является почти неизбежным следствием того, как OLAP — машина обрабатывает все данные.
Особенности представления отчетов:
F13: Гибкость формирования отчетов (Оригинальное правило 11). Требует, чтобы измерения могли быть размещены в отчете так, как это нужно пользователю.
F14: Стандартная производительность отчетов (Оригинальное правило 4). Требует, чтобы производительность формирования отчетов существенно не падала с ростом количества измерений и размеров базы данных.
F15: Автоматическая настройка физического уровня (Замена оригинального правила 7). Требует, чтобы OLAP системы автоматически настраивали свою физическую схему в зависимости от типа модели, объемов данных и разреженности базы данных.
Управление измерениями:
F16: Универсальность измерений (Оригинальное правило 6). Все измерения должны быть равноправны, каждое измерение должно быть эквивалентно и в структуре, и в операционных возможностях.
F17: Неограниченное число измерений и уровней агрегации (Оригинальное правило 12).
В случае ограничения Кодд предлагает принятие некоторого максимума, который должен обеспечивать, по крайней мере, 15 измерений, а предпочтительнее — 20. Технически нет продукта, который мог бы соответствовать этому требованию, потому что нет неограниченного объекта на ограниченном компьютере. В любом случае, немного приложений нуждается в более чем 8 или 10 измерениях. Немного приложений имеют иерархию более шести консолидированных уровней.
F18: Неограниченные операции между размерностями (Оригинальное правило 9). Все виды операций должны быть дозволены для любых измерений, а не только для измерений типа «показатель» (мера).
Срез — заключается в выделении подмножества ячеек гиперкуба при фиксировании значения одного или нескольких измерений. В результате сечения получается срез или несколько срезов, каждый из которых содержит информацию, связанную со значением измерения, по которому он был построен. Например, если выполнить сечение по значению ЗАО «Строитель» измерения Покупатель, то полученный в результате срез будет содержать информацию об истории продаж всех товаров данного предприятия, которую можно будет свести в плоскую таблицу.
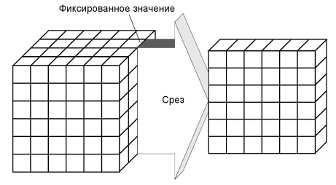
Рис. 13. Операция среза
Куб данных обозначим как множество ячеек (на примере трехмерного куба). Зафиксируем значение k, то есть. В данном примере, если выполнять операцию среза, то получим в результате плоскость, представленную матрицей .
Таким образом, = ,.
Вращение — изменение расположения измерений, представленных в отчете или на отображаемой странице. Например, операция вращения может заключаться в перестановке местами строк и столбцов таблицы. Кроме того, вращением куба данных является перемещение внетабличных измерений на место измерений, представленных на отображаемой странице, и наоборот.
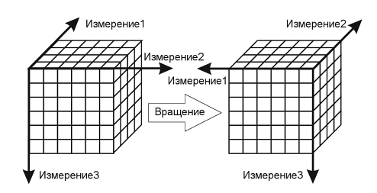
Рис. 14. Операция вращения
Таким образом, явным формальным примером операции вращения будет служить транспонирование матрицы.
Пусть — матрица вращения размера mЧn. Тогда транспонированная матрица, полученная в результате выполнения операции вращения, размером nЧm такая, что: элементы .
Консолидация и детализация — операции, которые определяют переход вверх по направлению от детального представления данных к агрегированному и наоборот, соответственно. Направление детализации (обобщения) может быть задано как по иерархии отдельных измерений, так и согласно прочим отношениям, установленным в рамках измерений или между измерениями.
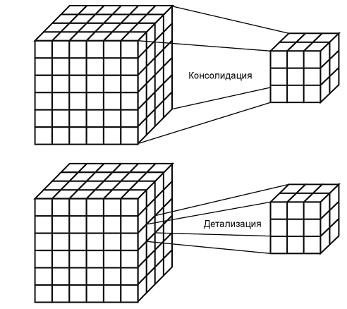
Рис. 15. Операции консолидации и детализации
Задачи, методы и алгоритмы Data Mining.
В службах Microsoft SQL Server реализовано несколько алгоритмов в решениях интеллектуального анализа данных. Все алгоритмы интеллектуального анализа данных Майкрософт настраиваются, они полностью программируются через API-интерфейсы или компоненты интеллектуального анализа данных служб SQL Server Integration Services. Выбор правильного алгоритма в конкретной аналитической задаче может быть достаточно сложным. В то время как можно использовать различные алгоритмы для выполнения одной и той же задачи, каждый алгоритм выдает различный результат. Например, можно использовать алгоритм дерева принятия решений (Майкрософт) не только для прогнозирования, но также в качестве способа уменьшения количества столбцов в наборе данных, поскольку дерево принятия решений может идентифицировать столбцы, не влияющие на конечную модель интеллектуального анализа данных.
К часто используемым методам и алгоритмам Data Mining относятся:
- 1. Упрощенный алгоритм Байеса;
- 1. Деревья решений;
- 2. Линейная регрессия;
- 3. Анализ временных рядов;
- 4. Кластеризация;
- 5. Алгоритм взаимосвязей;
- 6. Кластеризация последовательностей;
- 7. Нейронные сети;
- 8. Логическая регрессия.
Большинство аналитических методов, используемые в технологии Data Mining — это известные математические алгоритмы и методы. Новым в их применении является возможность их использования при решении тех или иных конкретных проблем, обусловленная появившимися возможностями технических и программных средств. Следует отметить, что большинство методов Data Mining были разработаны в рамках теории искусственного интеллекта.
Метод представляет собой норму или правило, определенный путь, способ, прием решений задачи теоретического, практического, познавательного, управленческого характера.
Задача классификации и регрессии.
Формально задачу классификации и регрессии можно описать следующим образом. Имеется множество объектов:
.
где — исследуемый объект.
Каждый объект характеризуется набором переменных:
.
где — независимые переменные, значения которых известны и на основании которых определяется значение зависимой переменной .
В Data Mining часто набор независимых переменных обозначают в виде вектора:
.
Каждая переменная может принимать значения из некоторого множества:
.
Если значениями переменной являются элементы конечного множества, то говорят, что она имеет категориальный тип.
Если множество значений переменной y конечное, то задача называется задачей классификации. Если переменная y принимает значение на множестве действительных чисел R, то задача называется задачей регрессии.
В задачах классификации и регрессии обнаруженная функциональная зависимость между переменными может быть представлена одним из следующих способов:
- · классификационные правила;
- · деревья решений;
- · математические функции.
Классификационные правила состоят из двух частей: условия и заключения: если (условие), то (заключение).
Условием является проверка одной или нескольких независимых переменных. Проверки нескольких переменных могут быть объединены с помощью операций «и», «или» и «не».
Заключение
м является значение зависимой переменной или распределение ее вероятности по классам.
Основным достоинством правил является легкость их восприятия и запись на естественном языке. Еще одно преимущество — их относительная независимость.
Существуют разные методы построения правил классификации: алгоритм построения 1-правил, метод Naive Bayes.
Деревья решений — это способ представления правил в иерархической, последовательной структуре.
Деревья решений легко преобразуются в правила. В условную часть таких правил записывается условие, описанное в узлах дерева на пути к листу, в заключительную часть — значение, определенное в листе.
Существуют различные методы построения деревьев решений, такие как: методика «разделяй и властвуй», алгоритм ID3, алгоритм С4.5, алгоритм покрытия.
Математическая функция выражает отношение зависимой переменной от независимых переменных. В этом случае анализируемые объекты рассматриваются как точки в (m + 1)-мерном пространстве. Тогда переменные объекта рассматриваются как координаты, а функция имеет следующий вид:
.
где — веса независимых переменных, в поиске которых и состоит задача нахождения классификационной функции.
Очевидно, что все переменные должны быть представлены в виде числовых параметров. Для преобразования логических и категориальных переменных к числовым используют разные способы.
Существуют различные методы построения математических функций: линейные методы, такие как метод наименьших квадратов, нелинейные методы, Support Vector Machines, регуляризационные сети, дискретизации и редкие сетки.
Задача кластеризации.
Большое достоинство кластерного анализа в том, что он позволяет осуществлять разбиение объектов не по одному параметру, а по целому набору признаков. Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих» объектов, называемых кластерами.
Формально задача кластеризации описывается следующим образом.
Дано множество объектов данных I, каждый из которых представлен набором атрибутов. Требуется построить множество кластеров C и отображение F множества I на множество C, т. е. F: I >C. Отображение F задает модель данных, являющуюся решением задачи. Качество решения задачи определяется количеством верно классифицированных объектов данных.
Множество I определим следующим образом:
.
где — исследуемый объект.
Каждый из объектов характеризуется набором параметров:
.
Каждая переменная может принимать значения из некоторого множества:
.
Задача кластеризации состоит в построении множества:
.
Здесь — кластер, содержащий похожие друг на друга объекты из множества:
.
где у — величина, определяющая меру близости для включения объектов в один кластер; — мера близости между объектами, называемая расстоянием.
Неотрицательное значение называется расстоянием между элементами, если выполняются следующие условия:
- 1., для всех .
- 2., тогда и только тогда, когда .
- 3. .
- 4. .
Если расстояниеменьше некоторого значения у, то говорят, что элементы близки и помещаются в один кластер. В противном случае говорят, что элементы отличны друг от друга и их помещают в разные кластеры.
Большинство популярных алгоритмов, решающих задачу кластеризации, используют в качестве формата входных данных матрицу отличия D. Строки и столбцы матрицы соответствуют элементам множества I. Элементами матрицы являются значения в строке j и столбце p. Очевидно, что на главной диагонали значения будут равны нулю:
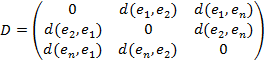
.
Расстояния между объектами предполагают их представление в виде точек mмерного пространства. В этом случае могут быть использованы различные расстояния, например,.
1. Евклидово расстояние — Иногда может возникнуть желание возвести в квадрат стандартное евклидово расстояние, чтобы придать большие веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом:
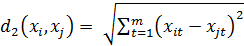
.
- 2. Расстояние по Хеммингу является просто средним разностей по координатам. Вычисляется по формуле:
- 3. Расстояние Чебышева может оказаться полезным, когда желают определить два объекта как «различные», если они различаются по какой-либо одной координате (каким-либо одним измерением). Вычисляется по формуле:
- 4. Расстояние Махаланобиса вычисляется по формуле:
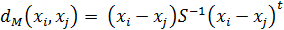
5. Пиковое расстояние предполагает независимость между случайными переменными, что говорит о расстоянии в ортогональном пространстве. Но в практических приложениях эти переменные не являются независимыми.
Задача поиска ассоциативных правил.
Обозначим объекты, составляющие исследуемые наборы (itemsets), следующим множеством:
.
где — объекты, входящие в анализируемые наборы; n — общее количество объектов.
Наборы объектов из множества I, хранящиеся в БД и подвергаемые анализу, называются транзакциями. Опишем транзакцию как подмножество множества I:
.
Набор транзакций, информация о которых доступна для анализа, обозначим следующим множеством:
.
где m — количество доступных для анализа транзакций.
Множество транзакций, в которые входит объект, обозначим следующим образом:
.
Некоторый произвольный набор объектов (itemset) обозначим следующим образом:
.
Множество транзакций, в которые входит набор F, обозначим следующим образом:
.
Отношение количества транзакций, в которое входит набор F, к общему количеству транзакций называется поддержкой (support) набора F и обозначается Supp (F):
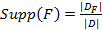
.
При поиске аналитик может указать минимальное значение поддержки интересующих его наборов. Набор называется частым (large itemset), если значение его поддержки больше минимального значения поддержки, заданного пользователем:
.
Таким образом, при поиске ассоциативных правил требуется найти множество всех частых наборов:
.
Обзор алгоритмов интеллектуального анализа данных.
Существует большое количество методов и алгоритмов интеллектуального анализа данных. Но в данной работе мы ограничимся рассмотрением тех алгоритмов, которые реализуются в SQL Server 2008, так как тема бакалаврской работы связана с рассмотрением бизнес-аналитики на этой платформе.
Таблица 3. Соответствие алгоритмов Microsoft для задач интеллектуального анализа данных.
Задача интеллектуального анализа данных. | Алгоритмы интеллектуального анализа данных. |
Классификация. | Для задачи классификации используются следующие алгоритмы Microsoft: упрошенный алгоритм Байеса, алгоритм дерева принятия решений, алгоритм нейронной сети. |
Регрессия. | Для задачи регрессии используются следующие алгоритмы Microsoft: алгоритм дерева принятия решений, алгоритм линейной регрессии, алгоритм временных рядов, алгоритм нейронной сети, алгоритм логической регрессии. |
Кластеризация. | Для задачи кластеризации используются следующие алгоритмы Microsoft: алгоритм кластеризации, алгоритм кластеризации последовательностей. |
Поиск взаимосвязей. | Для задачи поиска взаимосвязей используются следующие алгоритмы Microsoft: алгоритм дерева принятия решений, алгоритм взаимосвязей. |
Упрощенный алгоритм Байеса.
Упрощенный алгоритм Байеса — это алгоритм классификации, основанный на вычислении условной вероятности значений прогнозируемых атрибутов. Предполагается, что входные атрибуты являются независимыми и определен хотя бы один выходной атрибут.
Алгоритм основан на использовании формулы Байеса. Пусть — полная группа несовместных событий, а B — некоторое событие, вероятность которого положительна. Тогда условная вероятность события, если в результате эксперимента наблюдалось событие B, может быть вычислена по формуле:
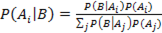
.
Формула Байеса позволяет вычислить условные (апостериорные) вероятности.
Для СУБД MS SQL Server 2008 описание модели интеллектуального анализа хранится в виде иерархии узлов. Для упрощенного алгоритма Байеса иерархия имеет 4 уровня. Среда разработки BI Dev Studio позволяет просмотреть содержимое модели.
Для корректного использования этого алгоритма необходимо учитывать:
- 1. входные атрибуты должны быть взаимно независимыми;
- 2. атрибуты могут быть только дискретными или дискретизованными (в процессе дискретизации множество значений непрерывного числового атрибута разбивается на интервалы и далее идет работы с номером интервала);
- 3. алгоритм требует меньшего количества вычислений, чем другие алгоритмы интеллектуального анализа для MS SQL Server 2008, поэтому он часть используется для первоначального исследования данных. По этой же причине алгоритм предпочтителен для анализа больших наборов данных с большим числом входных атрибутов.
Алгоритм дерева принятия решений.
Алгоритм представляет собой алгоритм регрессии и алгоритм классификации, предоставляемый службами Microsoft SQL Server Службы Analysis Services для использования в прогнозирующем моделировании как дискретных, так и непрерывных атрибутов.
Для дискретных атрибутов алгоритм осуществляет прогнозирования на основе связи между входными столбцами в наборе данных. Он использует значения этих столбцов (известные как состояния) для прогнозирования состояний столбца, который обозначается как прогнозируемый. Алгоритм идентифицирует входные столбцы, которые коррелированы с прогнозируемым столбцом.
Для непрерывных атрибутов алгоритм использует линейную регрессию для определения места разбиения дерева решений.
Если несколько столбцов установлены как прогнозируемые или если входные данные содержат вложенную таблицу, которая задана как прогнозируемая, то алгоритм строит отдельное дерево решений для каждого прогнозируемого столбца.
Принцип работы алгоритма.
Алгоритм дерева принятия решений строит модель интеллектуального анализа данных путем создания ряда разбиений в дереве. Эти разбиения представлены как узлы. Алгоритм добавляет узел к модели каждый раз, когда выясняется, что входной столбец имеет значительную корреляцию с прогнозируемым столбцом. Способ, которым алгоритм определяет разбиение, отличается в зависимости от того, прогнозирует ли он непрерывный столбец или дискретный столбец.
Алгоритм дерева принятия решений использует выбор компонентов для руководства набором наиболее полезных атрибутов. Выбор компонентов используется всеми алгоритмами интеллектуального анализа данных служб Службы Analysis Services для увеличения производительности и качества анализа. Выбор компонентов играет важную роль в предотвращении использования процессорного времени малозначительными атрибутами. Если при разработке модели интеллектуального анализа данных в нее было добавлено слишком много входных или прогнозируемых атрибутов, то ее обработка может занять очень много времени или даже привести к нехватке памяти.
Прогнозирование дискретных столбцов.
Способ, которым алгоритм дерева принятия решений строит дерево для дискретного прогнозируемого столбца, можно продемонстрировать с использованием гистограммы. Показана гистограмма, на которой построен прогнозируемый столбец «Покупатели велосипедов» в сравнении с входным столбцом «Возраст». Гистограмма «Б» показывает, что возраст человека помогает определить, купит ли этот человек велосипед.
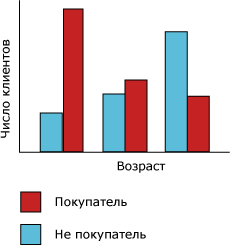
Рис. 16. Гистограмма «А»
Корреляция, показанная на диаграмме, приведет к тому, что алгоритм дерева принятия решений создаст новый узел в модели.
Добавление алгоритмом новых узлов к модели приводит к созданию древовидной структуры. Верхний узел дерева описывает разбиение прогнозируемого столбца для всех заказчиков. При продолжении роста модели алгоритм рассматривает все столбцы.
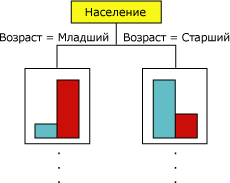
Рис. 17. Гистограмма «Б»
Прогнозирование непрерывных столбцов.
Когда алгоритм дерева принятия решений строит дерево, основанное на непрерывном прогнозируемом столбце, каждый узел содержит регрессионную формулу. Разбиение осуществляется в точке нелинейности в этой регрессионной формуле.
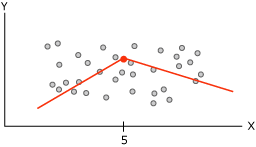
Рис. 18. Диаграмма данных
Диаграмма содержит данные, которые можно моделировать либо используя одиночную линию, либо используя две соединенные линии. Однако одиночная линия не обеспечит надлежащего представления данных. Вместо этого при использовании двух линий модель обеспечит гораздо более точное приближение данных. Точка соединения этих двух линий является точкой нелинейности и представляет собой точку, в которой разобьется узел в модели дерева решений. Эти два уравнения представляют регрессионные уравнения для этих двух линий.
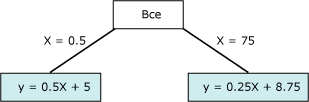
Рис. 19. Регрессионные уравнения
Алгоритм линейной регрессии.
Алгоритм линейной регрессии позволяет представить зависимость между входной и выходной переменными как линейную, а затем использовать полученный результат при прогнозировании. Подобный пример представлен на рисунке 16. Линия на диаграмме является наилучшим линейным представлением данных.
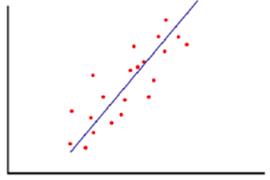
Рис. 20. Пример использования линейной регрессии
В случае одной независимой переменной (одного регрессора), задача может быть сформулирована следующим образом.
Уравнение, описывающее прямую на плоскости:. Для i-й точки будет справедливо, где — разница между фактическим значением и вычисленным в соответствии уравнением линии. Каждой точке соответствует ошибка, связанная с ее расстоянием от линии регрессии. Нужно с помощью подбора коэффициентов a и b получить такое уравнение, чтобы сумма ошибок, связанных со всеми точками, стала минимальной. Для решения этой задачи может использоваться, в частности, метод наименьших квадратов.
В SQL Server 2008 при выборе алгоритма линейной регрессии вызывается особый вариант алгоритма дерева решений с параметрами, которые ограничивают поведение алгоритма и требуют использования определенных типов данных на входе.
Линейная регрессия является полезным и широко известным методом моделирования, особенно для случаев, когда известен приводящий к изменениям базовый фактор, и есть основания ожидать линейный характер зависимости.
Алгоритм анализа временных рядов.
В общем случае, временной ряд — это набор числовых значений, собранных в последовательные моменты времени (в большинстве случаев — через равные промежутки времени). Целью анализа временного ряда может быть выявление имеющихся зависимостей текущих значений параметров от предшествующих, с последующим использованием их для прогнозирования новых значений.
Ряд можно представить как упорядоченное множество элементов или событий, каждое из которых в общем случае может быть описано набором атрибутов:. На практике чаще всего используется один атрибут. При описании варианта для интеллектуального анализа данных, отметка времени (или номер элемента во временном ряде) вводится как один из атрибутов. Как правило, предполагается, что отметка времени — дискретное числовое значение, а предсказываемый атрибут — непрерывный.
Выделяют два основных формата представления временных рядов — столбчатый и чередующийся (или смешанный, от англ. mixed). С данными в столбчатом формате несколько проще работать, но этот формат менее гибкий.
Рассмотрим теперь некоторые особенности реализации алгоритма в SQL Server 2008. Алгоритм временных рядов (Microsoft Time Series) предоставляет собой совокупность двух алгоритмов регрессии, оптимизированных для прогноза рядов непрерывных числовых значений. Ими являются:
- ? алгоритм «дерево авторегрессии с перекрестным прогнозированием» (ARTxp), который оптимизирован для прогнозирования следующего значения в ряду; он появился в SQL Server 2005;
- ? алгоритм «интегрированные скользящие средние авторегрессии» (ARIMA), являющийся отраслевым стандартом в данной области; добавлен в SQL Server 2008, чтобы повысить точность долгосрочного прогнозирования.
По умолчанию службы Analysis Services для обучения модели используют каждый алгоритм отдельно, а затем объединяют результаты, чтобы получить наиболее точный прогноз. В зависимости от имеющихся данных и требований к прогнозам, можно выбрать для использования только один алгоритм.
Учет корреляций между рассматриваемыми рядами или, иначе говоря, перекрестного влияния рядов, можно отметить в качестве особенности реализации алгоритма временных рядов в SQL Server.
Точность прогноза для временного ряда может повысить указание известной периодичности.
Авторегрессия отличается от обычной регрессии тем, что текущее значение параметра выражается через его значения в предыдущие моменты времени. Если использовать линейные зависимости, то алгоритм имеет решение в виде:
.
где: — погрешность, которую надо минимизировать путем подбора коэффициентов, в чем и заключается обучение модели. Использование аналитическими службами SQL Server дерева авторегрессии позволяет менять формулу путем разбиения в точках нелинейности.
Алгоритм кластеризации.
Кластеризация позволяет снизить размерность задачи анализа предметной области, путем «естественной» группировки вариантов в кластеры. Таким образом, кластер будет объединять близкие по совокупности параметров элементы, и в некоторых случаях, его можно рассматривать как единое целое.
В случаях, когда для группировки используются значения одного-двух параметров, задача кластеризации может быть относительно быстро решена вручную или, например, обычными средствами работы с реляционными базами данных. Когда параметров много, возникает потребность в автоматизации процесса выявления кластеров.
Предоставляемый аналитическими службами SQL Server 2008 алгоритм кластеризации (Microsoft Clustering), использует итерационные методы для группировки вариантов со сходными характеристиками в кластеры. Алгоритм сначала определяет имеющиеся связи в наборе данных и на основе этой информации формирует кластеры.
Идею можно проиллюстрировать с помощью диаграмм на рисунке 21. На первом этапе имеется множество вариантов, далее идет итерационный процесс формирования кластеров, и в итоге получен относительно небольшой набор кластеров, которым можно задать идентификаторы и продолжить анализ.

Рис. 21. Переход от отдельных вариантов к кластерам
Microsoft Clustering содержит реализацию двух алгоритмов кластеризации. Первый из них, алгоритм К-средних (англ. c-means), реализует, так называемую жесткую кластеризацию. Это значит, что вариант может принадлежать только одному кластеру. Идея алгоритма заключается в следующем:
- 1. Выбирается число кластеров k.
- 2. Из исходного множества данных случайным образом выбираются k записей, которые будут служить начальными центрами кластеров.
- 3. Для каждой записи исходной выборки определяется ближайший к ней центр кластера. При этом записи, «притянутые» определенным центром, образуют начальные кластеры.
- 4. Вычисляются центроиды — центры тяжести кластеров. Каждый центроид — это вектор, элементы которого представляют собой средние значения признаков, вычисленные по всем записям кластера. Центр кластера смещается в его центроид.
Шаги 3 и 4 итеративно повторяются, при этом может происходить изменение границ кластеров и смещение их центров. В результате минимизируется расстояние между элементами внутри кластеров. Остановка алгоритма производится тогда, когда границы кластеров и расположения центроидов не перестанут изменяться от итерации к итерации, т. е. на каждой итерации в каждом кластере будет оставаться один и тот же набор записей.
Второй метод, реализованный в Microsoft Clustering, это максимизация ожиданий (англ. Expectation-maximization, EM). Он относится к методам мягкой кластеризации, т. е. вариант в этом случае принадлежит к нескольким кластерам, а для всех возможных сочетаний вариантов с кластерами вычисляются вероятности.
При кластеризации методом EM алгоритм итеративно уточняет начальную модель кластеризации, подгоняя ее к данным, и определяет вероятность принадлежности точки данных кластеру. Этот алгоритм заканчивает работу, когда вероятностная модель соответствует данным. Функция, используемая для установления соответствия, — логарифм функции правдоподобия данных, вводимых в модель.
Если в процессе формируются пустые кластеры или количество элементов в одном или нескольких кластерах оказывается меньше заданного минимального значения, малочисленные кластеры заполняются повторно с помощью новых точек и алгоритм EM запускается снова. Результаты работы алгоритма максимизации ожидания являются вероятностными: каждая точка данных принадлежит всем кластерам, но с разной вероятностью. Поскольку метод допускает перекрытие кластеров, сумма элементов всех кластеров может превышать число элементов обучающего набора.
Реализация Майкрософт предоставляет два режима: масштабируемую и немасштабируемую максимизацию ожидания. По умолчанию при масштабируемой максимизации ожидания просматривается 50 000 записей. В случае успеха модель использует только эти данные. Если модель не удается подогнать на основании 50 000 записей, считываются еще 50 000 записей. При немасштабируемой максимизации ожидания считывается весь набор данных, независимо от его размера. Этот метод создает кластеры более точно, но предъявляет значительные требования к объему памяти.
По умолчанию используется масштабируемая максимизация ожидания, так как это более производительный алгоритм с меньшими требованиями к объему оперативной памяти. В большинстве случаев выигрыш в скорости не ведет к ухудшению качества окончательной модели.
Алгоритм взаимосвязей.
Алгоритм взаимосвязей или ассоциативных правил (Association Rules) позволяет выявить часто встречающиеся сочетания элементов данных и использовать обнаруженные закономерности для построения прогноза.
Для выявления часто встречающихся наборов объектов может использоваться алгоритм Apriori, реализация которого лежит в основе алгоритма Microsoft Association Rules, использующегося в SQL Server 2008. Алгоритм Apriori последовательно выделяет часто встречающиеся одно-, двух-, …, n-элементные наборы. На i-м этапе выделяются i-элементные наборы. Для этого сначала выполняется формирование наборов-кандидатов, после чего для них рассчитывается поддержка.
Поддержка (от англ. support) используется для измерения популярности набора элементов. Например, поддержка набора элементов {A, B} - общее количество транзакций, которые содержат как A, так и B.
Чтобы количественно охарактеризовать правило, используется вероятность (англ. probability). Этот же показатель иногда называется достоверностью.
Probability (A=>B) = Probability (B|A) = Support (A, B)/Support (A).
Вероятность для набора {A, B} рассчитывается как отношение числа транзакций, содержащих этот набор, к общему числу транзакций.
Чтобы оценить взаимную зависимость элементов используется важность (англ. importance) или показатель интереса.
Importance ({A, B})=Probability ({A, B})/(Probability (A)*Probability (B)).
Если Importance ({A, B}) = 1, то A и B — независимые элементы. Importance ({A, B}) > 1 означает, что A и B имеют положительную корреляцию (клиент купивший товар A вероятно купит и B). Importance ({A, B}) < 1 указывает на отрицательную корреляцию.
Для правил важность рассчитывается как логарифм отношения вероятностей:
Importance (A => B) = log (Probability (B|A)/(Probability (B| not A)).
В данном случае равная 0 важность означает, что между A и B нет взаимосвязи. Положительная важность означает, что вероятность B повышается, когда справедливо A; отрицательная — вероятность B понижается, когда справедливо A.
Настройками пороговых значений можно регулировать максимальное число элементов в рассматриваемых наборах, минимальную вероятность, при которой правило будет рассматриваться, минимальную поддержку для рассматриваемых наборов и т. д.
Алгоритм кластеризации последовательностей.
Задача кластеризации последовательностей — выявить часто встречающиеся последовательности событий. Важное различие заключается в том, что в данном случае учитывается, в какой очередности события происходят (или элементы добавляются в набор). Схожие последовательности объединяются в кластеры. Кроме анализа характеристик кластеров, возможно решение задачи прогнозирования наступления событий на основании уже произошедших ранее.
Используемый аналитическими службами SQL Server 2008 алгоритм Microsoft Sequence Clustering — это гибридный алгоритм, сочетающий методы кластеризации с анализом марковских цепей. Анализируемое множество вариантов формируется с использованием вложенных таблиц.
Важно, чтобы вложенная таблица содержала собственный идентификатор, который позволил бы определить последовательность элементов.
С помощью марковских моделей анализируется направленный граф, хранящий переходы между различными состояниями. Алгоритм Microsoft Sequence Clustering использует марковские цепи n-го порядка. Число n говорит о том, сколько состояний использовалось для определения вероятности текущего состояния. В модели первого порядка вероятность текущего состояния зависит только от предыдущего состояния. В марковской цепи второго порядка вероятность текущего состояния зависит от двух предыдущих состояний, и так далее.
Вероятности перехода между состояниями хранятся в матрице переходов. По мере удлинения марковской цепи, размер матрицы растет экспоненциально, соответственно растет и время обработки, что надо учитывать при решении практических задач.
Далее алгоритм изучает различия между всеми возможными последовательностями, чтобы определить, какие последовательности лучше всего использовать в качестве входных данных для кластеризации. Созданный алгоритмом список вероятных последовательностей используется в качестве входных данных для применяемого по умолчанию EM-метода кластеризации (англ. Expectation Maximization, максимизации ожидания).
Целями кластеризации являются как связанные, так и не связанные с последовательностями атрибуты. У каждого кластера есть марковская цепь, представляющая полный набор путей, и матрица, содержащая переходы и вероятности последовательности состояний. На основе начального распределения используется правило Байеса для вычисления вероятности любого атрибута, в том числе — последовательности, в конкретном кластере.
Алгоритм нейронных сетей.
В случае наличия в данных сложных зависимостей между атрибутами, «быстрые» алгоритмы интеллектуального анализа, такие как упрощённый алгоритм Байеса, могут давать недостаточно точный результат. Улучшить ситуацию может применение нейросетевых алгоритмов.
Нейронные сети — это класс моделей, построенных по аналогии с работой человеческого мозга. Существуют различные типы сетей, в частности, в SQL Server алгоритм нейронной сети использует сеть в виде многослойного перцептрона, в состав которой может входить до трех слоев нейронов, или перцептронов. Такими слоями являются входной слой, необязательный скрытый слой и выходной слой.
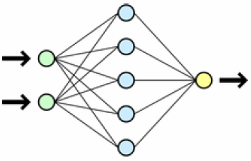
Рис. 22 Пример схемы нейронной сети
Каждый нейрон получает одно или несколько входных значений (входов) и создает выходное значение (один или несколько одинаковых выходов). Каждый выход является простой нелинейной функцией суммы входов, полученных нейроном. Входы передаются в прямом направлении от узлов во входном слое к узлам в скрытом слое, а оттуда передаются на выходной слой. Нейроны в составе слоя не соединены друг с другом. Скрытый слой может отсутствовать (в частности, это используется алгоритмом логистической регрессии).
В используемом аналитическими службами SQL Server 2008 алгоритме Microsoft Neural Network, имеющий более двух состояний дискретный входной атрибут модели интеллектуального анализа приводит к созданию одного входного нейрона для каждого состояния и одного входного нейрона для отсутствующего состояния (если обучающие данные содержат какие-либо значения NULL). Непрерывный входной атрибут «создает» два входных нейрона: один нейрон для отсутствующего состояния и один нейрон для значения самого непрерывного атрибута. Входные нейроны обеспечивают входы для одного или нескольких скрытых нейронов.
Выходные нейроны представляют значения прогнозируемых атрибутов для модели интеллектуального анализа данных. Дискретный прогнозируемый атрибут, имеющий более двух состояний, «создает» один выходной нейрон для каждого состояния и один выходной нейрон для отсутствующего или существующего состояния. Непрерывные прогнозируемые столбцы «создают» два выходных нейрона: один нейрон для отсутствующего или существующего состояния и один нейрон для значения самого непрерывного столбца.
Нейрон получает входы от других нейронов или из других данных, в зависимости от того, в каком слое сети он находится. Входной нейрон получает входы от исходных данных. Скрытые нейроны и выходные нейроны получают входы из выхода других нейронов нейронной сети. Входы устанавливают связи между нейронами, и эти связи являются путем, по которому производится анализ для конкретного набора вариантов.
Каждому входу присвоено значение, именуемое весом, которое описывает релевантность или важность конкретного входа для скрытого или выходного нейрона. Чем больше вес, присвоенный входу, тем более важным является значение этого входа. Значения веса могут быть отрицательными; это означает, что вход может подавлять, а не активировать конкретный нейрон. Чтобы выделить важность входа для конкретного нейрона, значение входа умножается на вес. В случае отрицательных весов умножение значения на вес служит для уменьшения важности входа. Схематично это представлено на рисунке 17, где — вход, — соответствующий ему вес.
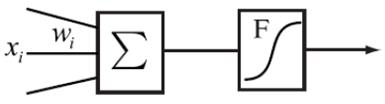
Рис. 23 Формальное представление нейрона
Каждому нейрону сопоставлена простая нелинейная функция, называемая функцией активации, которая описывает релевантность или важность определенного нейрона для этого слоя нейронной сети. В качестве функции активации в алгоритме Microsoft Neural Network.
крытые нейроны используют функцию гиперболического тангенса (tanh), а выходные нейроны — сигмоидальную (логистическую) функцию. Обе функции являются нелинейными и непрерывными, позволяющими нейронной сети моделировать нелинейные связи между входными и выходными нейронами.

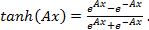
Обучение модели интеллектуального анализа данных производится по следующей схеме. Алгоритм сначала оценивает обучающие данные и резервирует определенный процент из них для использования при определении точности сети.
Затем алгоритм определяет количество и сложность сетей, включаемых в модель интеллектуального анализа данных. Определяется число нейронов в каждом слое. Процесс обучения строится по следующей схеме:
- 1. На начальной стадии случайным образом присваиваются значения всем весам всех входов в сети.
- 2. Для каждого обучающего варианта вычисляются выходы.
- 3. Вычисляются ошибки выходов. В качестве функции ошибки может использоваться квадрат остатка (квадрат разности между спрогнозированным и фактическим значением).
Шаги 2, 3 повторяются для всех вариантов, используемых в качестве образцов. После этого, веса в сети обновляются таким образом, чтобы минимизировать ошибки.
В процессе обучения может выполняться несколько итераций. После прекращения роста точности модели обучение завершается.
Алгоритм логической регрессии.
Логистическая регрессия является известным статистическим методом для определения влияния нескольких факторов на логическую пару результатов. Например, задача может быть следующей.
Предположим, что прогнозируемый столбец содержит только два состояния, и необходимо провести регрессионный анализ, сопоставляя входные столбцы с вероятностью того, что прогнозируемый столбец будет содержать конкретное состояние. Результаты, полученные методами линейной и логистической регрессии, представлены на рисунке 20"А" и 20"В" соответственно. Линейная регрессия не ограничивает значения функции диапазоном от 0 до 1, несмотря на то, что они должны являться минимальным и максимальным значениями этого столбца. Кривая, формируемая алгоритмом логистической регрессии, в этом случае более точно описывает исследуемую характеристику.

Рис. 24. Сравнение результатов, полученных методами линейной «А» и логистической регрессии «В»
В реализации Майкрософт, для моделирования связей между входными и выходными атрибутами применяется видоизмененная нейронная сеть, в которой отсутствует скрытый слой. Измеряется вклад каждого входного атрибута, и в законченной модели различные входы снабжаются весовыми коэффициентами. Название «логистическая регрессия» отражает тот факт, что кривая данных сжимается путем применения логистического преобразования, чтобы снизить эффект экстремальных значений.
В данной главе выполнен обзор технологий бизнес-аналитики, в частности — обзор оперативного анализа данных, построенного на базе OLAP, и интеллектуального анализа данных, для реализации которого может быть использован Data Mining, и указана основная их цель и преимущество.
Также приведено подробное описание моделей, используемые средствами СУБД SQL Server. В данном разделе подробно рассказывается о методах и алгоритмах, заложенных в анализе данных, а также их формализация.
В первой части работы приведена подробная архитектура СУБД для улучшения понимания происходящих процессов.
Следующая глава будет посвящена разделу с языковыми средствами для СУБД SQL Server.