Обработка тестовых данных

Перед началом обработки изображения создавались два массива HEATMAP и COUNT оба размера 3360×3360, изначально заполненные нулями. Из тестового изображения последовательно извлекались изображения размером 20×224×224 со сдвигом D=112 пикселей (см. рис.9). Для каждого изображения всеми моделями, подготовленными для данного класса делались предсказания разметки. Полученные вероятности прибавлялись… Читать ещё >
Обработка тестовых данных (реферат, курсовая, диплом, контрольная)
Набор тестовых данных был намного больше тренировочных и состоял из 429 изображений. Каждое тестовое изображение обрабатывалось отдельно. Перед началом обработки, изображение по аналогии с тренировочными данными приводилось к виду матрицы 20×3360×3360 и нормализовалось.
Перед началом обработки изображения создавались два массива HEATMAP и COUNT оба размера 3360×3360, изначально заполненные нулями. Из тестового изображения последовательно извлекались изображения размером 20×224×224 со сдвигом D=112 пикселей (см. рис.9). Для каждого изображения всеми моделями, подготовленными для данного класса делались предсказания разметки. Полученные вероятности прибавлялись к массиву HEATMAP по тем же координатам, из которых было получено изображение для анализа. К массиву COUNTS по тем же координатам соответственно прибавлялась единичка. По окончании расчета массив HEATMAP поэлементно делился на массив COUNTS. И попиксельно с использованием, полученного на этапе валидации значения THR приводился к 0 или 1. На базе полученного «двухцветного» 2D массива формировались финальные полигоны решения.
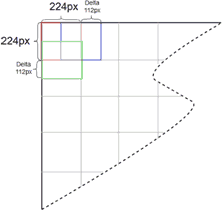
Рис. 9. — Подход на базе скользящего окна
Ниже предложены дополнительные методики увеличения точности предсказаний. Они вошли в наше финальное решение лишь частично из-за ограниченных доступных аппаратных ресурсов и ограниченное время соревнования. На обработку тестового набора для одного класса в среднем тратилось 8−10 часов.
- 1) Уменьшение шага для скользящего окна со 112 до 56 (и ниже) почти всегда приводит к улучшению метрики, но одновременно с этим увеличивает время расчета как O (N2). Например, для класса 4 на валидации счет вырос с 0.385 714 до 0.403 683 при уменьшении шага со 112 до 56 пикселей.
- 2) Точность распознавания на краях изображения в нейронной сети ниже. Поэтому были проведены эксперименты по сегментации используя только центральную часть UNET. Что дало для класса 5 на валидации:
Обычное значение: 0.507 446.
центральная часть 160×160 пикселей из квадрата 224×224 с шагом 80 пикселей: 0.514 557.
центральная часть 200×200 пикселей из квадрата 224×224 с шагом 100 пикселей: 0.512 844.
3) В некоторых случаях на валидации THR=0.5 не было самым оптимальным параметром. Поэтому имеет смысл использовать оптимальное значение. Например, для класса 6:
THR 0.1: 0.738 943.
THR 0.5: 0.757 858.
THR 0.9: 0.759 850.
На рис. 10 приведен пример получения сегментации для некоторого участка изображения для класса 5. Сначала сегментация, предсказанная каждой из 5 моделей. Затем общий HEATMAP и потом различная сегментация в зависимости от значения THR.

Рис. 10. — Пример сегментации для класса 5 (деревья)