Интерпретация результатов апробации составленной прикладной модели

Данный скриншот показывает, как сначала открывается потом с СУБД и считываются данные о пользователях, извлекаются метрики. После закрытия потока с СУБД все данные хранятся уже в оперативной памяти компьютера и уже начинает работать алгоритм C4.5, который строит дерево решений. После вывода дерева решений, алгоритм запускает проверку тестовой выборки (см. рис. 4). В тестовой выборке содержится… Читать ещё >
Интерпретация результатов апробации составленной прикладной модели (реферат, курсовая, диплом, контрольная)
Запускаем прототип с определёнными метриками (как это сделать было описано ранее). Результат работы прототипа представлен на ниже (см. рис. 3).

Рисунок 3. Результат работы прототипа.
Данный скриншот показывает, как сначала открывается потом с СУБД и считываются данные о пользователях, извлекаются метрики. После закрытия потока с СУБД все данные хранятся уже в оперативной памяти компьютера и уже начинает работать алгоритм C4.5, который строит дерево решений. После вывода дерева решений, алгоритм запускает проверку тестовой выборки (см. рис. 4).
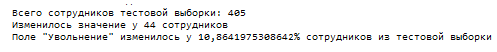
Рисунок 4. Проверка С. 4.5.
В тестовой выборке содержится 405 сотрудников и изменения изменились у 44 сотрудников, то есть у 10.86% процентов алгоритм не смог угадать — уволится сотрудник или нет. Вполне возможно, что данные сотрудники уже, как раз уволились и алгоритм сделал все верно (наша база данных не синхронизируется с настоящей).
Далее запускается алгоритм наивного байесовского классификатор, который сразу после выявления вероятностей запускает проверку тестовой выборки (см. рис. 5).

Рисунок 5. Проверка наивного байесовского классификатора.
У тех, кто собирается уволиться процент ошибки составляет 40%.
У тех, кто собирается остается процент ошибки составляет 33%.
Если посмотреть общий процент отклонения, то он составляет 34,23%. Достаточно высокий процент ошибки по сравнению с алгоритм С4.5 Но стоит отметить что это вероятностная модель и она показывает вероятность того, что сотрудник уволиться. Вполне возможно, что поведение сотрудника соответствует стереотипу человека с желанием уволиться, но он просто не решается этого делать. Так же стоит и здесь отметить, что наша база не является актуальной.