Правила перехода между уровнями представления моделей данных

Рассматривая процесс трансформации информационных структур на логический уровень, несложно увидеть, что применяемые инструментальные средства существенно отличаются друг от друга в части организации и представления структур данных. Это накладывает определенные ограничения на возможности прямой интеграции продуктов, а в случае применения продуктов различных производителей вопросы интеграции… Читать ещё >
Правила перехода между уровнями представления моделей данных (реферат, курсовая, диплом, контрольная)
Ранее, в гл. 1, были рассмотрены уровни представления моделей данных, определяющих использование соответствующей терминологии и технологий представления и описания данных, которые должны быть представлены при реализации базы данных. Так, на аналитическом и концептуальном уровнях, когда рассматриваются анализ предметной области и описание бизнес-процессов, представляются информационные структуры данных в виде бизнес-элементов и хранилищ данных. На логическом уровне разработчиками представляется логическая и инфологическая модели базы данных, ориентированные на представление базы данных и информационную структуру предметной области соответственно. На даталогическом и физическом уровнях представляется модель реализации базы данных. На внутреннем и внешнем уровнях — фактическое исполнение базы данных па магнитном носителе. Между этими уровнями, в целях обеспечения целостности проектирования, применяются процессы переходов (рис. 4.73), многие из которых реализованы в соответствующих инструментальных средствах.
 Рис. 4.73. Процесс трансформации моделей. |
Переход к логической модели базы данных
Сформированные на аналитическом и концептуальном уровнях бизнесэлементы, описывающие информационные структуры объектов, сведения о которых необходимо обрабатывать и хранить в базе данных, при организации логического уровня представления базы данных целесообразно перенести в созданную пустую логическую модель базы данных, для последующей нормализации.
Рассматривая процесс трансформации информационных структур на логический уровень, несложно увидеть, что применяемые инструментальные средства существенно отличаются друг от друга в части организации и представления структур данных. Это накладывает определенные ограничения на возможности прямой интеграции продуктов, а в случае применения продуктов различных производителей вопросы интеграции (совместной работы) продуктов зачастую становятся неразрешимыми. Поэтому для перехода между уровнями применяется метод, который де-факто стал стандартом передачи структурированных данных. Этот метод заключается в использовании формата XML, на базе которого представляются файлы, содержащие необходимую информацию.
В результате, понимая сложности прямой интеграции продуктов, разработчики инструментальных средств, в целях совместимости, предоставляют возможности экспорта и импорта моделей, представленных в соответствующих форматах. Если же инструментальные средства моделирования бизнес-процессов и моделей базы данных являются средствами одного производителя и предусматривается взаимодействие только между ними, то между продуктами организуется интеграционный механизм передачи структур данных.
Например, инструментальное средство СА BPWin Process Modeler предоставляет возможность разработчику сформировать полные структуры данных, включая их атрибутивный состав, непосредственно в инструментальном средстве, при построении моделей потоков данных (ДПД, DFD). Непосредственная интеграция с инструментом СЛ ERWin Data Modeler позволяет, не выполняя процедур формирования сущностей, сформировать их в модели базы данных. Разработчику остается только обеспечить установление связей между сущностями и их нормализацию. Проблемой этого подхода является необходимость работать с уже сформированными полными структурами данных, что зачастую вызывает сложности в корректности применения правил нормализации, поскольку в течение моделирования бизнес-процессов и потоков данных разработчики описывают документы или структуры объектов, сведения о которых нужно хранить в базе данных, не имея возможности построить модель базы данных со связями и определить правильность и полноту выделенных структур.
Учитывая такие сложности, наиболее корректным представляется метод, при котором будут созданы структуры данных, которые, хотя и представляются на уровне бизнес-моделирования атрибутами, тем не менее, в модель базы данных трансформируются самостоятельными типами сущностей, что позволяет реализовать процедуру документарного подхода к моделированию базы данных, используя комплексы правил технической и логической нормализации. Такой метод подразумевает, что любой бизнес-элемент описывается структурными элементами с неопределенными атрибутами или без атрибутов.
Ранее, с помощью инструментального средства IBM WebSphere Business Modeler был описан бизнес-процесс реализации товара в электронном магазине, где на потоках между бизнес-функциями и вспомогательными функциями определили некоторые бизнес-элементы в виде определенных структур данных, предполагая их дальнейшее преобразование в сущности логической модели базы данных. Учитывая эту особенность, разработчик при описании бизнес-процессов выстраивает структуры бизнес-элементов таким образом, чтобы иметь возможность применить правила нормализации. В случае применения документарного подхода к моделированию базы данных разработчик на уровне описания бизнес-процессов будет максимально детально описывать атрибутивный состав каждого бизнес-элемента и его структурных компонент (вложенные бизнес-элементы). Когда разработчик планирует применение объектного подхода, то атрибутивный состав бизнес-элементов основывается не на отражении характеристических атрибутов каждого бизнес-элемента или объекта, а на указании структурных объектов, которыми характеризуется каждый бизнес-элемент, что приводит к созданию сущностей-объектов, атрибутивный состав которых определяется на уровне логического моделирования базы данных.
Процедура трансформации бизнес-элементов в логическую модель базы данных предполагает выполнение нескольких шагов:
- • реализация экспорта модели бизнес-процессов для применения в средствах моделирования базы данных с указанием правил представления атрибутивных элементов в создаваемых сущностях;
- • реализация импорта выгруженной модели структур данных в инструментальное средство моделирования базы данных;
- • определение атрибутивного состава сформированных сущностей, установление связей между ними и проведение нормализации сущностей и связей до получения полной модели базы данных.
Начинается трансформация бизнес-элементов в структуры модели базы данных с выбора метода выгрузки (рис. 4.74). Для этого разработчик, на базе IBM WebSphere Business Modeler, выбирает в контекстном меню проекта бизнес-процессов пункт «Экспорт…» и потребителя выгруженных данных «InfoSphere Data Architect…» Если выгрузка структур данных направлена на дальнейшее использование в средстве IBM InfoSphere Data Architect, то выбирается соответствующий пункт выбора формата выгрузки. В случае использования сторонних инструментальных средств можно использовать формат выгрузки «Текст с разделителями (.csv, .txt)», формирующий универсальное представление для использования в различных программных средствах, включая Microsoft Excel.
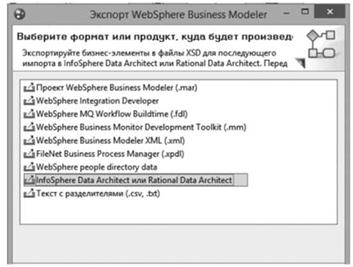 Рис. 4.74. Выбор потребителя выгруженных структур данных. |
Следующим этапом является указание панки на магнитном носителе (жесткий диск), куда необходимо сохранить выгруженные данных (рис. 4.75). При выборе варианта InfoSphere Data Architect процедура экспорта создаст схемы ХМ L-документа с расширением .xsd.
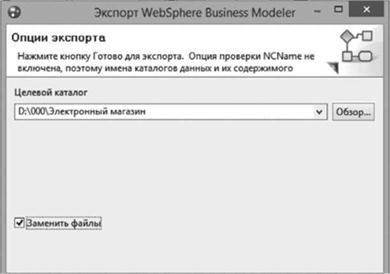 Рис. 4.75. Выбор места сохранения выгрузки. |
В итоге экспорта будет создан файл соответствующего формата для использования средства моделирования базы данных (рис. 4.76). В зависимости от выбранного формата представления данных будет использоваться нужное расширение. Дальнейшая процедура трансформации, согласно этапности, заключается в открытии и воспроизведении выгруженных данных в инструментальном средстве моделирования базы данных.
 Рис. 4.76. Результат экспорта бизнес-элементов. |
Перейдя в инструментальное средство IBM InfoSphere Data Architect в созданном проекте моделирования данных и используя пункт «Import…» контекстного меню проекта, запускают процедуру восстановления из выгруженного файла модели базы данных. Поскольку сведения выгружались из средства, не предназначенного для моделирования данных, то представление сущностей будет реализовываться на основании атрибутов, указанных в бизнес-элементах. В первом диалоговом окне импорта структур данных разработчику необходимо выбрать вид мастера формирования модели — Data Model Import Wizard (рис. 4.77).
Определив вид мастера, инструментальное средство запрашивает сведения о файле с данными и месте расположения результата импорта. Среди таких характеристик предлагается указать:
- • Model format (формат модели) — указывается тип источника данных для импорта модели, где, при использовании экспортированной модели из другого специализированного средства моделирования структур данных, указывается эго средство, либо, если искомого средства нет и формат выгруженного файла соответствует одному из вариантов, предлагаемых для выбора;
- • Model (модель) — указывается файл, где сохранены выгруженные сведения о структурах данных;
- • Target project (проект назначения) — указывает проект в рабочем пространстве инструментального средства, в котором необходимо создать модель данных, используя указанный ранее файл;
- • Model type (тип модели) — указывает вариант создаваемой модели базы данных (логическая или физическая), но, по умолчанию, инструментальное средства предлагает использовать автоопределение (Auto detect) создаваемой модели;
- • File name (имя файла) — указывается имя файла модели, которое приобретет соответствующее типу модели расширение.
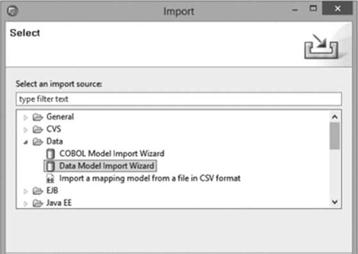 Рис. 4.77. Выбор мастера формирования модели. |
Учтя указанные свойства, инструментальное средство создаст необходимый файл модели базы данных, куда из указанного экспортированного (выгруженного) файла будут взяты сведения о структурах данных.
Следующий набор свойств указывает дополнительные характеристики импорта модели базы данных (рис. 4.78), определяя каждый атрибут самостоятельным сущностным элементом (сущностью) в модели базы данных, с которыми необходимо проводить нормализацию.
При этом разработчику предлагается не только указать дополнительные свойства трансформации, но и определить необходимость проверки создаваемой модели базы данных и, если создается физическая модель базы данных, выбрать систему управления базами данных, для которой будет формировать модель базы данных (рис. 4.79). В этом случае будут использовать особые условия представления модели базы данных, учитывая особенности ее реализации в СУБД.
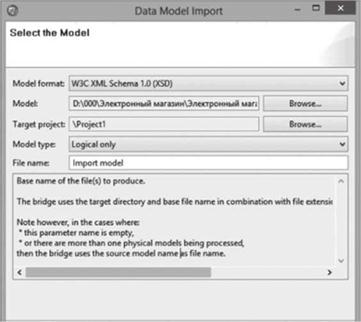 Рис. 4.78. Установка основных параметров импорта. |
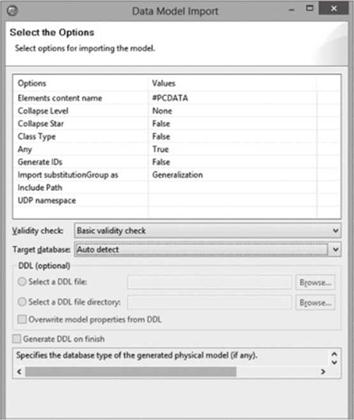 Рис. 4.79. Установка дополнительных параметров импорта. |
Однако если в средстве моделирования бизнес-процессов определены все структурные элементы данных, учитывая объектный подход, и нормализация должна проводиться на уровне ассоциированных с объектами сущностями, то процесс трансформации модели можно реализовать по другой технологии, используя физический файл схемы базы данных, который можно подгрузить в проект моделирования базы данных.
Принцип «погрузки» файла идентичен варианту импорта модели, предполагающего выбор пункта «Import…» контекстного меню проекта, но в качестве типа мастера выбирают вариант «File System» (Файловая система), после чего, взяв файл экспорта из среды бизнес-моделирования и проект получения файла, формируют схему XML-данных с указанием всех атрибутивных и сущностных элементов, как они были представлены при моделировании бизнес-процессов (рис. 4.80).
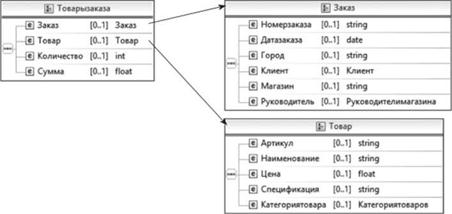 Рис. 4.80. Пример XML-схемы, импортированной в среду моделирования. |
Дальнейший переход к модели базы данных основывается на определении правил трансформации XML-схемы в модель базы данных (рис. 4.81), для чего необходимо создать правило трансформации через пункт «New/ Transformation Configuration» (Новый/Конфигурация трансформации) контекстного меню раздела проекта «Data Models» (Модели данных).
Для обеспечения трансформации разработчику необходимо указать тип трансформации «XML Schema to Logical Data Model» и проект назначения для реализации модели. Чтобы инструментальное средство знало об источнике сведений по информационной структуре объектов и документов, необходимо указать именно загруженный в проект файл XSD, а не сам проект (рис. 4.82).
В рамках последнего указания параметров трансформации от разработчика требуется определить действия по отношению к ключевым атрибутам (рис. 4.83):
• Generate surrogate key (Создавать суррогатный ключ) — свойство определяет необходимость генерирования первичного ключа для структурных элементов, с целью последующего формирования сцепленных первичных ключей по связанным сущностям.
- • Merge entities as attributes, where appropriate (Объединить сущности как атрибуты, когда необходимо) — свойство определяет возможность представления создаваемых сущностей в виде атрибутов других сущностей в случае, когда бизнес-элемент определен атрибутом другого бизнес-элемента.
- • Overwrite files without warning (Перезаписать файлы без предупреждения) — свойство обеспечивает необходимость спросить у разработчика необходимость перезаписи файла модели базы данных, если она уже существует.
- • Prefix foreign key attribute name with inverse verb phrase (Использовать префикс внешнего ключа с указанием смысловой фразы) — свойство указывает на необходимость отображения в модели па связи смыслового наполнения по создаваемому внешнему ключу.
 Рис. 4.81. Выбор основных настроек трансформации. |
 Рис. 4.82. Указание источника схемы и получателя модели. |
В результате выполнения указанных действий будет создана конфигурация трансформации файла экспорта структур данных в виде схемы XML (рис. 4.84), которую можно запустить на выполнение и получить модель базы данных, соответствующую указанным в файле характеристикам.
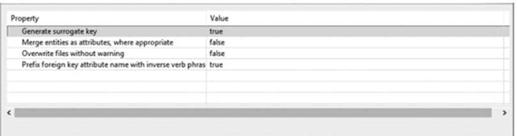 Рис. 4.83. Определение параметров для создаваемых атрибутов. |
 Рис. 4.84. Созданная конфигурация трансформации. |
Для того, чтобы трансформация была запущена, необходимо использовать кнопку «Run» (Запустить) в открытом окне конфигурации (рис. 4.85). Выполнение настроенного алгоритма трансформации приведет к появлению модели базы данных с набором сущностей и связей между ними.
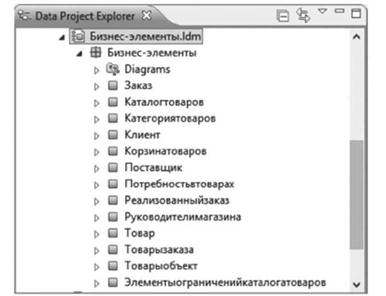 Рис. 4.85. Результат трансформации ХМЬ-схемы в логическую модель базы данных. |
В результате трансформации ХМЬ-схемы, экспортированной из модели бизнес-процессов, получаются сущности в соответствии с названиями бизнес-элементов (рис. 4.86). Важно отметить, что применение национальных алфавитов при именовании атрибутов и бизнес-элементов приводит к тому, что в модели базы данных имеющиеся пробелы между словами удаляются и наименования становятся слитными (без пробелов). При использовании.
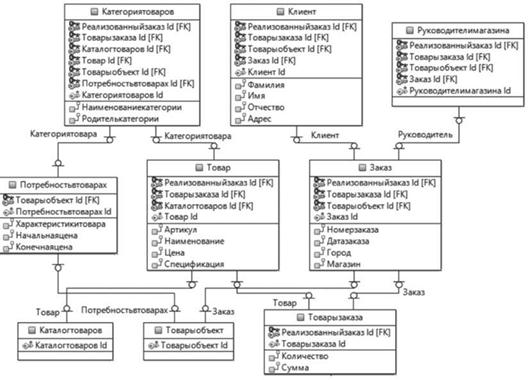 Рис. 4.86. Модель базы данных после трансформации. |
латиницы проблемы с пробелами не возникает. Однако даже при использовании национальных алфавитов можно избежать этой проблемы, определив правила трансформации, создав специальную модель имен (Glossary Model)[1], которая содержит макро правила, применяемые при трансформации моделей и нормализации связей.
При, казалось бы, полезной возможности трансформации модели существует ряд существенных недостатков использования такой технологии: первичные ключи суррогатного свойства создаются в каждой сущности независимо от существования в качестве первичных ключей атрибутов, сформированных на основании идентифицирующих связей;
— связи между сущностями определяются типом один — к — одному (1:1) и мощностью с обеих сторон связей «0,1», что требует последующего пересмотра всех существующих связей;
смысловые фразы, описывающие суть связей между сущностями, определяются существительными, характеризующими отношение дочерней сущности к родительской, что некорректно по сути формулировки, которая должна быть представлена глагольной формой;
- — если в процессе моделирования бизнес-процессов остались бизнесэлементы, не связанные с другими бизнес-элементами, то они в модели также будут представлены отдельными сущностями;
- — размерности атрибутов по типам данных, где требуется указание количества символов (обычно символьные и текстовые атрибуты), указывается в максимальной размерности.
Такие недостатки трансформации требуют от разработчика дополнительного анализа модели базы данных, пересмотра установленных связей между сущностями, определения необходимости наличия сцепленных первичных ключей и суррогатных первичных ключей, а также проведения нормализации полученной модели базы данных.
- [1] В рамках данного учебника вопрос использования макроязыка при трансформации моделей не рассматривается.