Этапы машинного анализа текстов.
Проблема многозначности естественных языков

Венцом машинного анализа текстов является прагматический анализ. Редкие системы доходят до этого этапа. На первый взгляд может показаться, что семантический и прагматический анализ — это одно и то же. На самом деле между ними существует принципиальная разница. Семантический анализ представляет собой процесс извлечения смысла текста на основе некоторой заданной модели знаний (например, онтологии… Читать ещё >
Этапы машинного анализа текстов. Проблема многозначности естественных языков (реферат, курсовая, диплом, контрольная)
Машинный анализ текстов на естественном языке предусматривает реализацию лингвистического процессора, выполняющего обработку входных текстовых документов в соответствии со следующими строго определенными этапами[1]:
- 1) графематический анализ;
- 2) морфологический анализ;
- 3) синтаксический анализ;
- 4) семантический анализ;
- 5) прагматический анализ.
Рассмотрим подобнее каждый из этапов.
Графематический анализ представляет собой самый нижний уровень обработки текстов и, соответственно, первый этап машинного анализа. Мы уже говорили, что членимость — это одно из базовых свойств текста, благодаря которому машина может произвести декомпозицию текста на структурные элементы. Графематический анализ и представляет собой такую декомпозицию текста. В зависимости от глубины и характера членения текста она может называться по-разному: графематический анализ, токенизация, сегментация.
Таким образом, главными задачами графематического анализа являются определение границ предложений (сегментация) и разделение предложений на слова (токенизация). Под токенами понимаются такие минимальные неделимые единицы текста, как слова, знаки препинания, даты, числа, сокращения и т. д. Примеры токенов:
- • даты и обозначения времени (02.04.59, 13:10);
- • аббревиатуры и сокращения, в том числе из одной буквы (СССР, СПб., 1-й, М.);
- • буквенно-цифровые названия (Tele2, Сочи-2014);
- • денежные обозначения (100 $);
- • слова, написанные вразрядку, прописными буквами, через дефис, сложные слова (л-е-т-о, ПРИКАЗЫВАЮ, хлеб-соль);
- • имена собственные (А. С. Пушкин, аль-Фараби, РиккиТикки-Тави);
- • электронные адреса и ссылки { Этот адрес e-mail защищен от спам-ботов. Чтобы увидеть его, у Вас должен быть включен Java-Script ,
- • номера телефонов в различных форматах (8−7232−540−443).
Морфологический анализ представляет собой второй этап в обработке текста. Он позволяет определить морфологические характеристики для каждого из выделенных слов текста. При этом для каждого слова определяется его лемма — нормальная форма. В русском языке нормальными считаются следующие морфологические формы слов:
- • для существительных — именительный падеж, единственное число;
- • для прилагательных — именительный падеж, единственное число, мужской род;
- • для глаголов, причастий, деепричастий — глагол в инфинитиве.
Процессу лемматизации (приведения слов к нормальным формам) присуща лексическая и морфологическая неоднозначность, которая выражается в том, что одному слову могут соответствовать несколько лемм. Эта неоднозначность может быть снята при выполнении синтаксического анализа. Например, при морфологическом разборе предложения «Дремлют в снегу одинокие ели» (И. Бунин) для всех слов, кроме слова «ели», лемма определяется однозначно. Для слова «ели» существует две леммы: «ель» (существительное) и «есть» (глагол).
Синтаксический анализ позволяет снять неоднозначность, которая возникает на морфологическом уровне. Например, с помощью синтаксического разбора можно установить, что слово «ели» играет в предложении роль подлежащего и предваряется определением «одинокие». Исходя из этих фактов, для слова «ели» выбирается лемма «ель». Таким образом, синтаксический анализ дополняет результаты морфологического и формирует дерево разбора предложения — структуру, элементы которой связаны синтаксическими правилами.
Существует два основных способа построения дерева синтаксического разбора: в виде дерева зависимостей и в виде дерева составляющих. Вершинами дерева зависимостей являются слова, а дугами — связи (зависимости) между словами (рис. 8.7). Корневой вершиной является сказуемое.
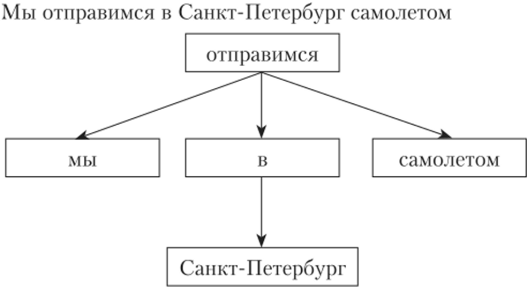
Рис. 8.7. Пример синтаксического разбора в виде дерева зависимостей
Разбор в виде дерева составляющих производится по следующему алгоритму. Сначала строятся все возможные синтаксические связи с назначенными им весами. Затем из полученного графа извлекается дерево минимального веса, включающее как можно больше вершин. Вершинами дерева составляющих являются группы слов, а дугами — связи между группами (рис. 8.8). Корневой вершиной является самая большая группа (предложение S)y которая затем распадается на две группы: именную группу NP и глагольную группу VP. Каждая из групп, в свою очередь, делится на составляющие ее подгруппы, и так до тех пор, пока на концах ветвей не окажутся все слова.
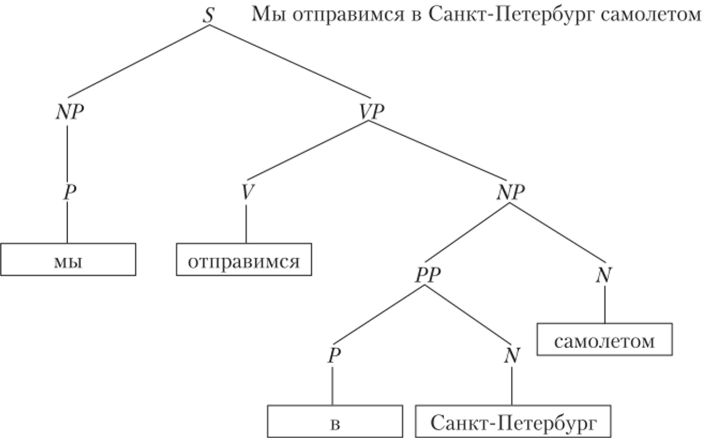
Рис. 8.8. Пример синтаксического разбора в виде дерева составляющих
Потребность в синтаксическом анализе возникает в более сложных системах, например в системах автоматического извлечения фактов. Извлечение фактов невозможно без выделения синтаксической структуры, так как значительную часть смысла передают не сами слова, а связи (отношения между словами). Для извлечения факта сначала определяется его опорный элемент (например, персона), затем, исходя из дерева разбора, определяются связи этой сущности с другими сущностями. Таким образом, формируется некая поверхностная схема факта.
Целью семантического анализа является переход от структуры синтаксических связей к ее смысловой интерпретации. Таким образом, на вход данного этапа подается синтаксическая структура текста, представленная в виде деревьев разбора. На выходе формируется множество семантических структур, построенных в соответствии с принятой формальной нотацией (семантической моделью) (рис. 8.9).
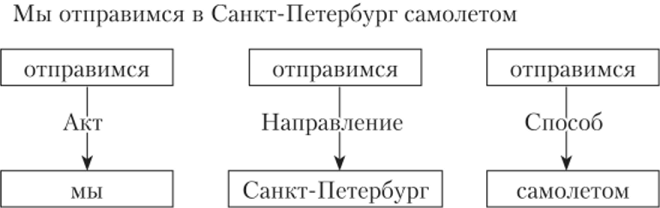
Рис. 8.9. Примеры семантических структур
Венцом машинного анализа текстов является прагматический анализ. Редкие системы доходят до этого этапа. На первый взгляд может показаться, что семантический и прагматический анализ — это одно и то же. На самом деле между ними существует принципиальная разница. Семантический анализ представляет собой процесс извлечения смысла текста на основе некоторой заданной модели знаний (например, онтологии предметной области). Прагматический анализ выходит за рамки моделей о предметной области и зачастую опирается на экстралингвистические факторы, такие как намерения автора, социальный контекст высказывания и т. д. Другими словами, семантический анализ производится в рамках явно заданной модели знаний, а прагматический анализ требует от машины способности анализировать неявные факторы и делать на их основе заключения, т. е. рассуждать.
Необязательно все этапы обработки будут реализованы. При разработке упрощенных прагматико-ориентированных систем обработки естественного языка, как правило, бывает достаточно реализации первых двух этапов. Однако чем больше этапов реализовано, тем сложнее и интеллектуальнее создаваемая система и тем меньше фрагментов неразрешенной многозначности оставляет она в текстах.
Разрешение многозначности естественного языка является одной из фундаментальных проблем его обработки. Существуют два основных типа многозначности: полисемия и омонимия. Полисемией называется языковое явление, при котором у одного и того же слова (или более крупной языковой единицы) имеется несколько связанных значений. Омонимией называется языковое явление, при котором у одного слова (или более крупной языковой единицы) имеется несколько несвязанных между собой значений.
Полисемия и омонимия возникают на всех уровнях представления текста: на морфологическом, лексическом, синтаксическом и т. д. В частности, можно выделить следующие варианты полисемии и омонимии:
- 1) лексическую омонимию. Сравните: прозрачный ключ; ключ в замке;
- 2) лексическую полисемию. Сравните: ключ в замке; ключ к решению;
- 3) лексико-морфологическую омонимию. Сравните: ели кашку; дремучие ели;
- 4) морфологическую омонимию. Сравните: милые березки (множественное число, именительный падеж); рядом ни березки (единственное число, родительный падеж);
- 5) синтаксическую омонимию. Сравните: мать купает дочь (мать купает маленькую дочь); мать купает дочь (старенькую маму купает дочь);
- 6) семантическую полисемию. Сравните: черно-бурая лиса; он — хитрая лиса;
- 7) прагматическую полисемию. Сравните: можешь приехать завтра? (просьба — приезжай завтра); можешь приехать завтра? (вопрос — сумеешь приехать завтра?).
Из школьного курса русского языка вы знаете, что омонимами называются слова, имеющие одинаковое звучание, но разные значения. Например, лук — растение и лук — орудие стрельбы. Подобное явление называется лексической омонимией. Однако омонимия присуща не только словам, но и предложениям. Такая омонимия называется синтаксической, и она обозначает явление, когда у одного и того же предложения существует несколько равноправных синтаксических структур.
Пример синтаксической омонимии дает нам предложение «Их шеф вернулся из командировки в Томск». Это предложение имеет две равноправные синтаксические структуры и, как следствие, два разных смысла (рис. 8.10). Первой структуре соответствует смысл: их шеф вернулся из Томска. Второй структуре соответствует смысл: их шеф вернулся в Томск. Таким образом, здесь мы наблюдаем разные виды зависимостей (разные конфигурации стрелок). Такая омонимия называется стрелочной.
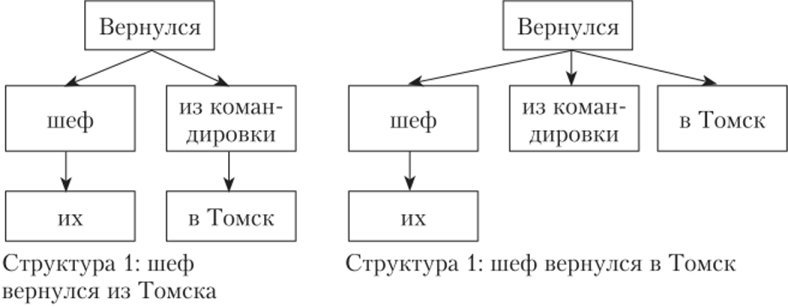
Рис. 8.10. Пример синтаксической омонимии.
Другой пример синтаксической омонимии дает нам предложение «Критика шефа была справедливой». Ей также соответствуют два разных смысла: критика, высказанная шефом, была справедливой; критика, которой подвергся шеф, была справедливой. Однако нетрудно заметить, что в отличие от предыдущего примера, здесь в обоих вариантах используется одна и та же синтаксическая структура, отличается только интерпретация этой структуры (разметка). Конкретно — интерпретация связи «критика шефа». В нервом случае связь субъектная (критикует шеф). Во втором случае связь объектная (критикуют шефа). Такая омонимия называется разметочной.
В одной работе по лингвистике[2] отмечается, что интерес к синтаксической омонимии особенно возрос с началом исследований, но машинному анализу текстов. Действительно, с точки зрения машинного анализа синтаксическая омонимия — это явление более сложного порядка, чем омонимия лексическая. Поясним сказанное на примере задачи, опубликованной в указанной работе. Автор задачи — Е. В. Муравеико.
Задача. Сколько различных смыслов имеет предложение «Соседа Виктора встретил вчера возвратившийся из поездки в Москву Олег»? Какие типы синтаксической омонимии представлены в этом предложении?
Решение. В тексте «Соседа Виктора встретил вчера возвратившийся из поездки в Москву Олег» имеется три фрагмента, каждый из которых допускает по две интерпретации (табл. 8.1). Как следует из таблицы, омонимия первого фрагмента разметочная, а второго и третьего фрагментов — стрелочная. Текст имеет 2−22 = 8 смыслов.
Таблица 8.1
Омонимичные фрагменты текста, приведенного в примере
№. | Фрагмент. | Первое понимание. | Второе понимание. |
…соседа Виктора… | соседа (чьего?) Виктора. | соседа по имени Виктор | |
…встретил вчера возвратившийся… | встретил (когда?) вчера. | вчера (когда?) возвратившийся. | |
…возвратившийся из поездки в Москву… | возвратившийся (куда?) в Москву. | из поездки (куда?) в Москву. |
Функцию разрешения многозначности, т. е. выделения нужного значения многозначной текстовой единицы, выполняет контекст. Слово «контекст», как и слово «текст», происходит от латинского слова textus, обозначающего «сплетение», «соединение», «связь», но оно вдобавок усилено приставкой сопкоторая переводится с латинского языка как «вместе», «совместно», «с». Таким образом, контекст — это связь связанного, связь в квадрате. В общепринятом определении контекст — это законченный отрывок речи (текста), общий смысл которого позволяет уточнить значение входящих в него отдельных языковых единиц (слов, предложений и т. п.).
Как правило, различают ситуативный (экстралингвистический) и лингвистический контексты.
Лингвистический контекст можно охарактеризовать как сложное явление, представляющее собой совокупность лексико-грамматических условий, при которых однозначно определяется смысл какой-либо единицы текста. Например, в качестве лингвистического контекста можно рассматривать сочетание определяемого слова с предшествующим или последующим словом. Сравните, «ели кашку» (сказуемое + прямое дополнение) и «дремучие ели» (определение + подлежащее).
Экстралингвистический контекст включает в себя «обстановку, время и место, к которому относится высказывание, а также любые факты реальной действительности, знание которых помогает рецептору (и переводчику) правильно интерпретировать значения языковых единиц в высказывании»[3]. Экстралингвистический контекст чрезвычайно важен в организации машинного перевода.
Например, слово term в английском имеет значение «условие» и «слово», и если задать переводчику Google просто фразу «special terms» без указания контекста, то фраза будет переведена как специальные условия. Если же ввести более подробный текст, то из его контекста Google Переводчик уяснит, что речь идет о терминах. Например, в тексте «Note that there are spelling errors in the text, abbreviations, different date formats, and special terns specific to this organization or industry» выражение special terms будет переведено как специальные термины. Вот полный перевод: «Обратите внимание, что есть орфографические ошибки в тексте, аббревиатуры, различные форматы даты и специальные термины, специфические для данной организации или отрасли».
Таким образом, машинный анализ текстов — это сложный интеллектуальный процесс, который зачастую требует выхода за рамки лингвистических знаний. Он сопряжен с ситуативным анализом, с анализом фактов, логическим выводом и многими другими задачами искусственного интеллекта.
- [1] Дунаев Л. Л. Исследовательская система для анализа текстов на естественном языке // Проблемы интеллектуализации и качества систем информатики: сборник. Вып. 13. Новосибирск: Изд-во ИСИ СО РАН, 2006.
- [2] Муравеико Е. В. Что такое синтаксическая омонимия? // Лингвистикадля всех: летние лингвистические школы 2005 и 2006. М.: Изд-во МЦНМО, 2008.
- [3] Комиссаров В. Н. Общая теория перевода. М.: Высшая Школа, 1990.