Модели данных.
Экономическая информатика

Линейный список — последовательность элементов (записей) базы данных с заданным отношением строгого порядка. С каждым элементом линейного списка при хранении связан конкретный физический адрес. Элементы списка могут иметь структуру, т. е. состоять из отдельных полей. В роли вторичного ключа в нашем примере могут выступать поля Клиент, Товар, так как каждое из них определяет совокупность записей… Читать ещё >
Модели данных. Экономическая информатика (реферат, курсовая, диплом, контрольная)
Все возможные структуры данных подразделяются на несколько классов структур, представляющих собой структурные модели данных [7]. Часто, говоря о логическом проектировании, эти модели называют просто моделями данных.
Классической и наиболее широко используемой в настоящее время моделью данных является реляционная модель данных. Исторически ей предшествовали инвертированные списки, иерархическая и сетевая модели [4, 6].
Развитием реляционной модели является постреляционная модель. В настоящее время достаточно широкое применение нашли многомерные модели, развиваются объектно-ориентированные модели [11].
Все перечисленные модели данных рассматриваются в данном параграфе, за исключением многомерной модели, которая описывается в параграфе 3.5, посвященном многомерному анализу данных и системам поддержки принятия решений.
Инвертированные списки
Рассмотрим предварительно линейные списки.
Линейный список — последовательность элементов (записей) базы данных с заданным отношением строгого порядка. С каждым элементом линейного списка при хранении связан конкретный физический адрес. Элементы списка могут иметь структуру, т. е. состоять из отдельных полей.
Например, в таблице, содержащей информацию о заказах товаров, записи о каждом заказе вводятся в базу данных в порядке возрастания номера заказа и размещаются в физической памяти последовательно друг за другом (табл. 3.1).
Таблица 3.1. Пример записей по линейному списку.
№. | Заказ. | Клиент. | Товар | Количество. |
Иванов. | Н4567. | |||
Белов. | Н3452. | |||
Петров. | Н4567. | |||
Иванов. | Н5500. |
Поле, определяющее местонахождение элемента (или элементов) списка, называется ключевым полем или ключом. Ключевые поля применяются для выполнения всех операций с данными. Ключ может быть простым, если в его качестве выступает только одно поле, и составным, если в качестве ключа используются несколько полей.
Первичным ключом называется ключевое поле, которое определяет только один элемент в списке.
В нашем примере первичным ключом является Заказ (номер заказа), в предположении, что в каждом заказе может быть указан только один товар. Если же это не так, то первичным ключом будет составной ключ (Заказ, Товар).
Вторичным ключом называется ключевое поле, определяющее несколько элементов в списке.
В роли вторичного ключа в нашем примере могут выступать поля Клиент, Товар, так как каждое из них определяет совокупность записей: Клиент — все заказы, сделанные конкретным клиентом, Товар — все заказы, в которых фигурирует указанный товар.
Наиболее интересным с точки зрения практического использования линейного списка является вопрос организации доступа к его элементам. Доступ осуществляется по ключам с помощью запроса в виде.
.
Существует целый ряд методов организации доступа по первичному ключу (см. работы [2, 11, 13]), позволяющих эффективно осуществлять поиск нужной информации.
Для обеспечения быстрого поиска по вторичным ключам в большинстве случаев используются инвертированные списки.
В инвертированных списках основной список не изменяется. Дополнительно строятся индексные структуры по полям, для которых необходимо организовать быстрый поиск.
Под индексом понимается средство ускорения операции поиска записей в списке и, следовательно, других операций: извлечения, модификации, сортировки и т. д.
В индекс включаются все значения соответствующего вторичного ключа, а также все ссылки на элементы основного списка с данным значением вторичного ключа.
Для рассмотренной выше табл. 3.1 могут быть построены индексы по вторичным ключам Клиент и Товар (рис. 3.3).
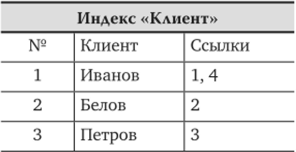
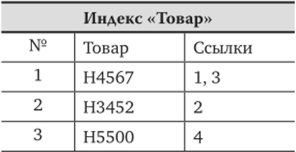
Рис. 3.3. Пример записи с индексами по вторичным ключам
Расположение всех ссылок для некоторого вторичного ключа в одном поле позволяет исключить перебор элементов в цепочке элементов при их поиске.
Рассмотрим пример операций над записями списка с использованием инвертированных списков.
Пример. Просмотр данных. * 1
Для просмотра всех заказов от клиента Иванова необходимо выполнить следующее.
По индексу «Клиент» для ключа Клиент находится соответствующий элемент: это элемент 1.
- 2. Выбираются ссылки для этого элемента: это множество {1; 4}.
- 3. В основном списке (табл. 3.1) выбираются последовательно элементы с номерами 1 и 4 и выводится содержимое поля Заказ для этих элементов. Результатом работы алгоритма является список (22 009, 22 012).
В заключение следует отметить, что организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, однако в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).