Нелинейные структуры данных

Прежде чем искать элемент в двоичном дереве поиска, необходимо такое дерево создать. Процесс создания сводится к считыванию неупорядоченных элементов данных и их индивидуальной вставке при соблюдении условия, что «растущее» при этом дерево является именно деревом поиска. Создание двоичного дерева поиска начинается от корневого узла, поэтому первый элемент данных необходимо поместить в корневой… Читать ещё >
Нелинейные структуры данных (реферат, курсовая, диплом, контрольная)
В тех случаях, когда существенны связи элементов данных между собой, в качестве структур данных используют графы. В зависимости от описываемых типов отношений используют графы типа дерево и сетка. Соответственно различают древовидные (иерархические) и сетевые структуры данных.
Древовидная структура, используется для описания отношения один-ко-многим. Она представляет собой иерархию элементов, называемых узлами (вершинами) (рис. 12.3). Дуги отражают отношения (связи) между элементами.
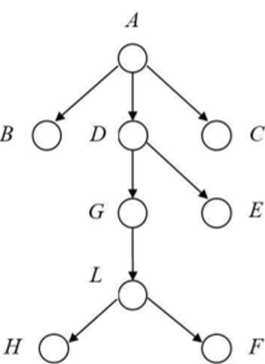
Рис. 12.3. Пример древовидной структуры.
Каждый узел, кроме одного, называемого корневым (корней), связан с одним узлом на более высоком уровне, называемым родительским для данного узла. Каждый узел может быть связан с одним или несколькими узлами на более низком уровне. По отношению к родительскому узлы на более низком уровне называют потомками (порожденными, дочерними). Узлы, не имеющие потомков, называются листьями. Структура, выходящая из одного узла, называется поддерево.
Выделяют особую категорию древовидных структур, называемую двоичными деревьями. Двоичное дерево древовидная структура, в которой допускается не более двух дуг для одного узла. Рекурсивное определение двоичного дерева выглядит так: двоичное дерево либо является пустым (оно не содержит ни одного узла), либо в нем имеется узел, известный как корень, а также два независимых поддерева — левое поддерево и правое поддерево.
Независимое поддерево означает, что ни один узел не может принадлежать одновременно левому и правому поддеревьям, имеющим общий корневой узел. Для двоичных деревьев на рис. 12.4 узлы, содержащие значения FOX и 35, являются корневыми для своих деревьев. Узел со значением DOG представляет собой корень для левого поддерева — части дерева, корень которого узел FOX.
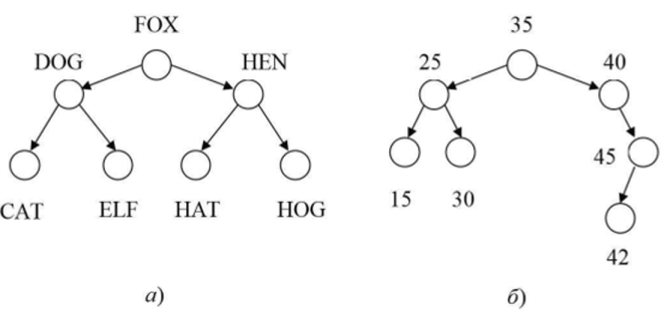
Рис. 12.4- Двоичные деревья Для хранения и поиска информации наиболее часто применяют так называемые двоичные деревья поиска. Двоичное дерево поиска это дерево, в котором корневой узел имеет большее значение, чем любой из узлов в левом поддереве, и меньшее, чем узлы в правом поддереве.
Деревья на рис. 12.4 являются примерами деревьев поиска. Для дерева на рис. 12.4, а строка, содержащаяся в каждом узле правого поддерева, представляет собой большее значение (согласно расположению, но алфавиту или, что-то же самое в данном случае, лексикографическому порядку, см. параграф 9.3), чем любая строка из узлов левого поддерева. Для дерева на рис. 12.4, б числа, содержащиеся в каждом узле правого поддерева, больше, чем любое число из узлов левого поддерева. Это свойство должно быть верно для любого узла двоичного дерева поиска, а не только для корневого. Например, число 40 должно быть меньше, чем оба числа, содержащиеся в его нравом поддереве.
Прежде чем искать элемент в двоичном дереве поиска, необходимо такое дерево создать. Процесс создания сводится к считыванию неупорядоченных элементов данных и их индивидуальной вставке при соблюдении условия, что «растущее» при этом дерево является именно деревом поиска. Создание двоичного дерева поиска начинается от корневого узла, поэтому первый элемент данных необходимо поместить в корневой узел. Для размещения в узлах дерева каждого последующего элемента данных, необходимо найти для него на дереве родительский узел, подсоединить к нему новый узел, а затем занести в этот новый узел новый элемент данных. Например, если значение нового элемента меньше ключевого значения родителя, то подсоединяется новый узел в качестве левого поддерева родительского узла и размещается новый элемент данных в только что созданном узле.
Построение дерева из списка значений 40, 20, 10, 50, 65, 45, 30 иллюстрирует рис. 12.5. Путь поиска при вставке каждого значения показан пунктиром.
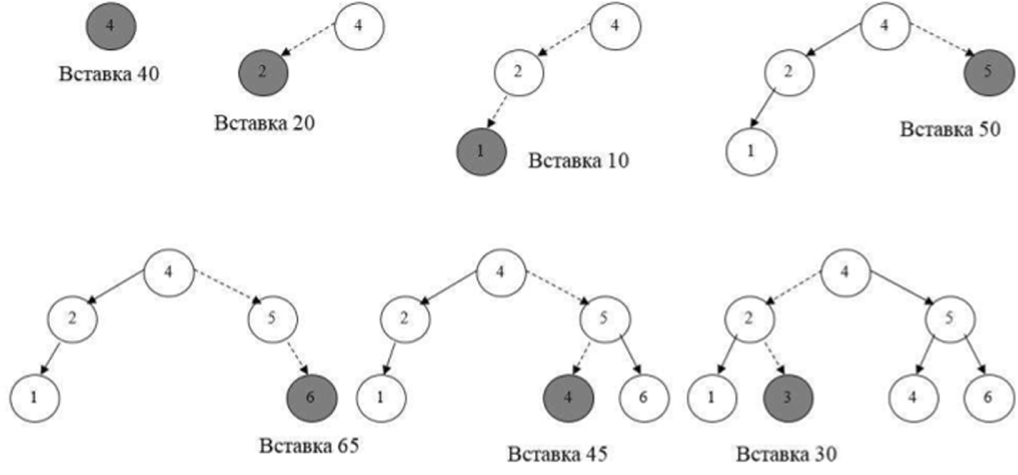
Рис. 12.5. Создание двоичного дерева поиска.
Сетевая структура данных является расширением древовидной: снимается ограничение на количество дуг дня одного узла. В сетевой структуре любой узел может быть связан с любым другим узлом (рис. 12.6). Сетевые структуры также используются дпя описания отношения многие-ко-многим.
Как и в случае древовидных структур, сетевую структуру можно описать с помощью исходных и порожденных узлов. Удобно представлять ее так, чтобы узлы-потомки располагались ниже родительских узлов. При рассмотрении некоторых сетевых структур естественно говорить об уровнях, так же как и в случае древовидных структур.
Поскольку обработка сетевых структур и их хранение сложнее аналогичных операций с деревьями, как правило, сетевые структуры преобразуют в совокупность деревьев.
Для представления древовидных и сетевых структур данных в памяти используется списковая структура. Список — это набор записей, расположенных в определенной последовательности. Различают два типа списков: непрерывный и связанный.
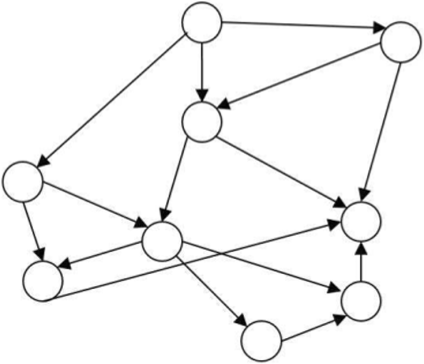
Рис. 12.6. Пример сетевой структуры.
Непрерывный список предполагает, что его элементы записаны один за другим в последовательные ячейки памяти. На рис. 12.7 приведен пример древовидной структуры, а на рис. 12.8 показано размещение данных в памяти в виде непрерывного списка. Последовательность элементов на рис. 12.8 иногда называют левосписковой структурой (последовательность типа «сверху вниз — слева направо»).
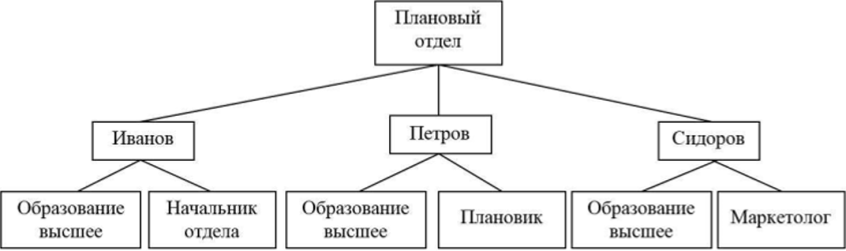
Рис. 12.7. Пример древовидной структуры.
Левосписковая структура строится следующим образом:
- 1. Начиная с вершины дерева, выбираются узлы сверху вниз по самой левой ветви дерева.
- 2. Когда выбран самый нижний узел этой ветви, выбираются подобные узлы слева направо.

Рис. 12.8. Размещение узлов древовидной структуры в памяти в виде непрерывного
списка.
3. Шаги 1 2 повторяются, причем уже выбранные узлы повторно в последовательность нс включаются.
Последовательные левосписковые структуры имеют один существенный недостаток: они нс позволяют осуществлять быстрый выбор элементов нижних уровней дерева, так как при этом требуется обращение ко всему списку. Кроме того, при удалении элемента из начала списка приходится перемещать последующие элементы к началу списка, чтобы сохранить существующий порядок. Еще более сложная проблема возникает при добавлении элемента, поскольку в этом случае требуется переместить список для освобождения блока ячеек, необходимого для расширения.
Связи в сетевых структурах также можно представить в виде непрерывного списка. Однако такое представление используется редко.
Связанный список предполагает, что его элементы могут быть расположены в памяти хаотическим образом. Каждый элемент связанного списка состоит из двух частей (рис. 12.9).
- 1. Содержательная (информационная) часть. Это, собственно, данные любого типа. Могут быть представлены в виде записи. Эта часть описывает одну из вершин дерева (сети).
- 2. Указующая (ссылочная) часть — указатель (указатели). Описывает связи дайной вершины.
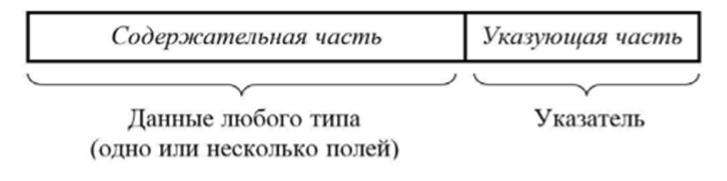
Рис. 12.9. Элемент связанного списка
Указатель — переменная, значение которой представляет собой адрес области памяти (первой ячейки памяти), где хранится информационная часть соседнего элемента списка.
Если в указующей части расположен адрес только одного соседнего элемента списка, то такой список называют односвязным или однонаправленным (рис. 12.10). Указующая часть последнего элемента, содержит специальный признак nil (пустой указатель, признак конца списка). Так как для каждого элемента односвязного списка, кроме последнего, можно однозначно указать следующий элемент, то такие списки иногда называют линейными. Для того, чтобы получить доступ к любому элементу списка, достаточно хранить в памяти только адрес начала списка.

Рис. 12.10. Структура линейного односвязного списка.
Если каждый элемент списка содержит более двух указателей (из вершины графа исходит более двух дуг), он называется многосвязным списком. Пример размещения в памяти древовидной структуры (см. рис. 12.3) в виде многосвязного списка приведен на рис. 12.11.

Рис. 12.11. Размещение узлов древовидной структуры в памяти в виде.
mi югосвязного списка Возможен вариант, когда в указующей части хранятся адреса двух элементов: предыдущего и следующего. В этом случае список называется двусвязным или двунаправленным (рис. 12.12). Такой список более универсален с точки зрения обработки и поиска данных, так как имеется возможность двигаться в двух направлениях: прямом и обратном. При этом для первого элемента списка в поле указателя предыдущего элемента находится признак пустого указателя (nil). Аналогично и для последнего элемента списка: в поле указателя следующего элемента также указан признак конца списка.

Рис. 12.12. Структура двусвязного списка.
Из односвязного и двусвязного списков можно получить кольцевой список, который вообще не содержит пустых указателей (рис. 12.13). Буфер клавиатуры персональных компьютеров, например, реализован именно как кольцевой список.

Рис. 12.13. Структура кольцевого списка.
Над линейными списками можно выполнять следующие типовые действия:
- — добавление нового узла непосредственно перед некоторым узлом;
- — удаление заданного узла;
- — объединение двух или более линейных списков в один единый список;
- — разбиение линейного списка на два или более отдельных списков;
- — создание копии списка;
- — сортировка узлов списка по возрастанию (убыванию) по некоторым полям в узлах;
- — поиск в списке узла с заданным значением в некотором поле.
Разновидностями линейных связанных списков являются стеки, очереди и деки.
Стек линейный список, в котором доступ к элементам выполняется только в одном конце списка — вершине стека. То же относится и к выполнению операций над элементами стека: удалить можно только вершину и добавить новый элемент только после вершины (новый элемент при этом сам становится вершиной). Такую организацию обработки элементов называют «последним пришел — первым вышел» (last in — first out, LIFO). Для иллюстрации стека подходит стопка бумаги: добавить и взять из такой стопки можно только верхний лист; после удаления листа сверху верхним становится лист, который был под ним.
На рис. 12.14, а приведен пример стека, содержащего символы «С», «Н-» и «2». Указатель Тор здесь ссылается только на вершину списка. Можно получить доступ только к символу «С». Чтобы получить доступ к символу «+», прежде необходимо удалить из стека элемент, содержащий символ «С». На рис. 12.14, б изображен тот же стек после того, как в него был занесен символ «*». Последний символ, который был занесен в стек, является первым, который оттуда можно извлечь.
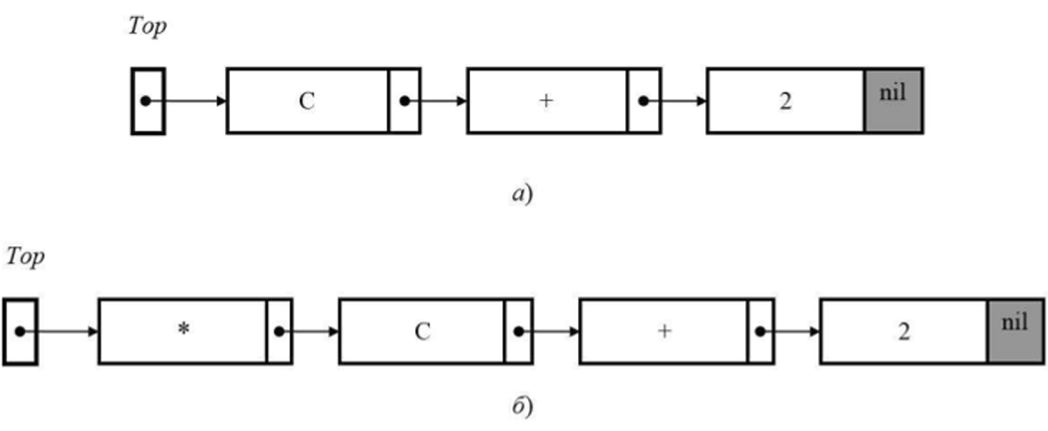
Рис. 12.14• Стек.
Именно благодаря стеку возможны такие приемы программирования, как вложенные подпрограммы и рекурсия.
Очередь — линейный список, в котором добавление элементов осуществляется на одном конце списка, а удаления выполняются на другом. Такую организацию обработки элементов называют «первым пришел — первым вышел» (first in — first, out, FIFO). Такая структура может быть использована для моделирования цепочки покупателей у или потока заданий печати, ожидающих вывод.
На рис. 12.15 приведен пример очереди из трех клиентов, ожидающих обслуживания в байке. Для удаления из очереди используется указатель Front (начало очереди), а для добавления нового элемента указатель Rear (конец очереди). После выполнения операций указатели будут переориентированы на новые элементы.
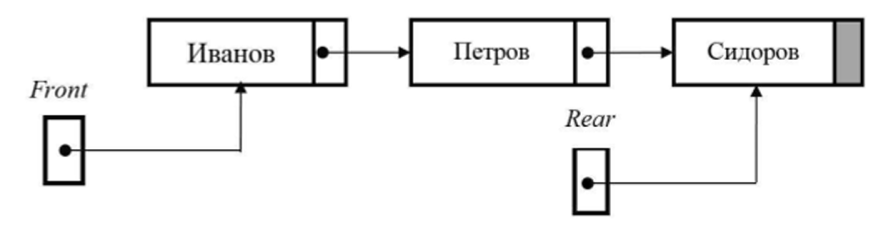
Рис. 12.15. Очередь.
Дек (очередь с двумя концами) — линейный список, в котором добавления и удаления элементов могут выполняются на обоих концах списка.
Наиболее фундаментальной структурой представления данных в оперативной памяти считаются массивы. Однако они имеют ряд недостатков, наиболее существенным из которых является выделение памяти под массив в полном объеме до начала выполнения программы. Несмотря на значительные возможности современных технических средств, размер памяти все же остается ограниченным, поэтому использование массивов дня обработки больших объемов данных нерационально.
Для решения указанной проблемы были предножены динамические структуры данных: связанные списки, стеки и очереди. Они обладают следующими особенностями:
- — память под отдельные элементы данных выделяется в тот момент, когда в них появляется необходимость (динамическое выделение памяти), в отличие от массивов, где выделяется целый блок памяти;
- — количество элементов данных динамической структуры заранее не известно и может изменяться в ходе выполнения программы; оно ограничивается объемом памяти и спецификой решаемой задачи;
- — элементы структуры нс занимают в памяти непрерывную область, а могут располагаться произвольным образом;
- — логическая последовательность элементов определяется явно с помощью одного или нескольких указателей, хранящихся в самих элементах.
Таким образом, связанные списки и массивы — две основные структуры представления данных в оперативной памяти. Сравним их между собой, выделив главные преимущества:
1. В случае связанных списков память используется более экономно по сравнению с массивами.
- 2. Еще одно преимущество списков — удобство вставки и удаления элементов. При использовании массивов для этих целей необходимо раздвигать или сдвигать элементы. В списке для выполнения этих операций достаточно поменять значения указующих полей соседних элементов.
- 3. Одним из важных достоинств массивов по сравнению со списками является простота их использования.
- 4. Более существенное преимущество массивов над списками представляет собой высокая скорость доступа к элементу массива (по индексу). В случае необходимости доступа к последнему элементу односвязного списка нужно последовательно обойти всю цепочку элементов, начиная с первого.
Из сказанного можно сделать вывод: при решении задач обработки данных во многих случаях выбор между массивом и списком является нетривиальной задачей. Необходимо тщательно взвесить все плюсы и минусы обоих вариантов, выбрав наиболее эффективную форму организации данных.