Системы на прямонаправленных нейронных сетях

Подавляющее большинство нрямонаправлснных НС выполнено в виде многослойных персептронов {МИТ). Они хороши тем, что для реализации можно использовать простые нейроускорители матричного типа. Это слоистые сети (до трех слоев). В общем виде они решают задачу аппроксимации, т. е. построения многомерного отображения, обобщающего набор примеров. В зависимости от типа выходных данных аппроксимация… Читать ещё >
Системы на прямонаправленных нейронных сетях (реферат, курсовая, диплом, контрольная)
Нейронные сети (НС) представляют знания в форме специальных отображений входов на выходы [7, 9, 12]. Такие отображения формируются в процессе обучения, при котором узловые элементы настраиваются в соответствии с запоминаемой информацией. Отображения запоминаются и активизируются ассоциативно. При обращении к НС путем задания входного кода на ее выходе формируется код, зависящий от настройки не одного элемента, как в обычной памяти, а множества элементов, образующих ассоциативную структуру.
Многочисленные варианты таких сетей используют узловые элементы типа формальных нейронов. В настоящее время развитие этого направления привело к созданию обширного семейства ассоциативных НС, которые могут обучаться и запоминать сложные образы, функции и отношения, а также принимать решения в сложных ситуациях.
НС наилучшим образом решают задачи классификации и аппроксимации. Ценным свойством является их способность к обобщению, т. е. решению задач при неполной информации на входах вследствие присущего им свойства ассоциативности. Теория и практика НС как обучаемых компонент интеллектуальных систем сейчас бурно развивается и в рамках коннективистского направления в искусственном интеллекте.
На практике НС реализуются в виде так называемых нейрокомпьютеров аппаратно на специализированных микросхемах цифрового или аналогового типа. Конструктивно они часто представляют собой нейросетевые модули, работающие под управлением главного процессора. Возможна также программная реализация НС на универсальных компьютерах. Однако наибольший интерес представляют самостоятельные нейрокомпьютеры, которые являются массивно-параллельными мелкозернистыми распределенными процессорными системами.
НС различаются по направлениям связей (с прямонаправленные и обратными связями), по структуре (полносвязные, слоистые, клеточные), по типу узловых элементов (логические, аналоговые), по методу обучения (с учителем — супервизорные, без учителя — несупервизорные и с подкреплением).
Подавляющее большинство нрямонаправлснных НС выполнено в виде многослойных персептронов {МИТ). Они хороши тем, что для реализации можно использовать простые нейроускорители матричного типа. Это слоистые сети (до трех слоев). В общем виде они решают задачу аппроксимации, т. е. построения многомерного отображения, обобщающего набор примеров. В зависимости от типа выходных данных аппроксимация принимает вид классификации (дискретные выходы) или регрессии (непрерывные выходы). Это дает возможность эффективно решать такие задачи, как распознавание образов, фильтрация шумов, предсказание временных серий и пр. Рассмотрим сначала возможности одного формального нейрона, а затем прямонаправленных НС, построенных на его базе.
Формальный нейрон вычисляет базовую функцию вида.
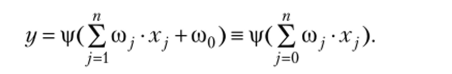
Такая функция имеет линейные дискриминантные свойства, т. е. способна разделять пространство входов. Сигмоидная функция активации |/(я) = -—— дает вероятность принадлежности к соответствующему классу. Линейный дискриминатор (один нейрон) классифицирует только линейно разделимые классы. В-мерном пространстве входов гиперплоскостью можно разделить произвольным образом лишь п + 1 точек. При большом количестве точек нужно несколько гиперплоскостей, для чего вводятся скрытые слои нейронов (II — Hidden). Тогда каждый нейрон будет получать на входы линейно разделимые множества. Заметим, что для решения многих задач достаточно одного скрытого слоя. Однако при большом числе обучающих примеров приходится увеличивать память НС путем добавления скрытых слоев. Практика применения МПТ показывает, что в этом случае число скрытых слоев не превышает 3, поскольку дальнейшее их добавление может привести к неоправданному увеличению времени обучения сети.
Исследование формальных нейронов и построенных на них НС позволяет сделать следующие выводы:
- • НС с одним //-слоем с п нейронами и ступенчатой функцией активации способна осуществить классификацию nD точек D-мерного пространства (классы nD примеров);
- • одного Я-слоя с сигмоидальной активацией достаточно для построения любой границы между классами с любой точностью;
- • одного Я-слоя с сигмоидальной активацией достаточно для аппроксимации любой функции с любой точностью;
- • точность аппроксимации возрастает с числом нейронов Я-слоев; при п нейронах ошибка имеет порядок 0(1 / п).
Рассмотрим подробнее две базовые модели прямопаправленных НС: персептроны и сети Кохонена.
Персентроны. В 1956 г. Ф. Розенблатт предложил первый вариант обучаемой НС, названный им персептропом [7]. Эта НС имела скрытый слой из нейронов с фиксированными случайными весами (ассоциативные элементы) и выходной слой с настраиваемыми весами. По числу слоев с настраиваемыми весами персептрон является однослойным.
Правило обучения иерсептрона по р-му примеру очень простое (правило Розенблатта):
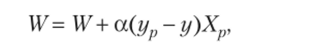
где W — вектор весов персептрона; а — параметр, регулирующий скорость обучения; ур, у — заданный и текущий выходы; Хр — заданный входной вектор.
Такие сети могли решать только простые задачи классификации в бинарном варианте входной и выходной информации. В дальнейшем персептроны были усложнены для работы с непрерывной информацией и отображения функций любой сложности. Это стало возможным только после разработки многослойных персептропов и эффективных алгоритмов их обучения [7, 12].
В МПТ все нейроны одного слоя контактируют со всеми нейронами соседнего слоя. Показано, что для решения сложных задач классификации достаточно трех слоев (считаются только те слои, где имеет место настройка весов). На рис. 9.1 приведена структура МПТ с тремя слоями. Соответствующее отображение входного вектора в выходной, формируемое таким МПТ, можно представить в матричной форме:
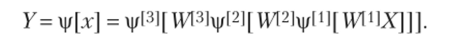
Заметим, что в каждом слое МПТ может быть разное число нейронов.
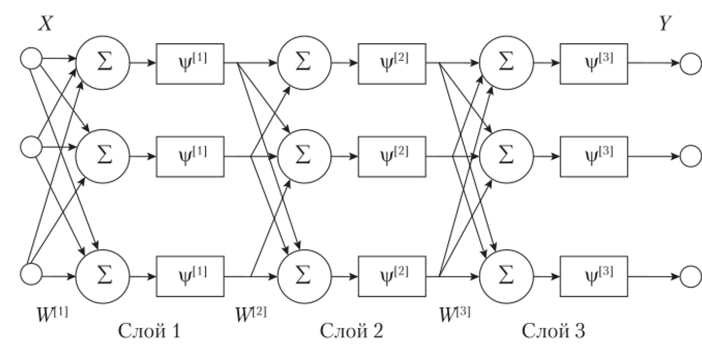
Рис. 9.1. Схема трехслойного персептрона.
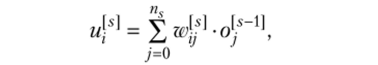
Вычисление линейного выхода (так называемого мембранного потенциала) /-го нейрона 5-го слоя производится по формуле, а выход нейрона после применения функции активации вычисляется как.
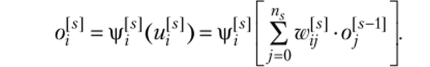
Для получения требуемого поведения веса должны быть надлежащим образом вычислены. В многослойном варианте правило Розенблатта для вычисления весов использовать нельзя. Основной вопрос при обучении МПТ состоит в том, как произвести коррекцию весов не в одном, а одновременно во всех слоях. Для этого требуется разделить общую ошибку на выходе сети пропорционально вкладу каждого слоя в отображение зависимости между входами и выходами сети, а затем вычислить новые значения весов для нейронов всех слоев.
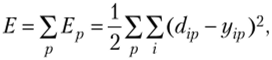
где dip, yip — желаемый и действующий выходы г-го нейрона для р-го примера.
Имеется два подхода для определения минимума Е:
1) последовательный подход (on-line) — предполагает, что для каждого примера, выбранного из выборки случайным образом, веса изменяются пропорционально отрицательному градиенту локальной ошибки Ер, т. е. для дискретного и непрерывного случаев соответственно:
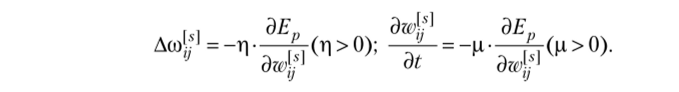
Показано, что если коэффициенты р и ц достаточно малы, то глобальная ошибка Е = ?? минимизируется; р
2) групповой подход (batch learning) — состоит в минимизации ошибки Е. Веса аккумулируются и усредняются из всех примеров перед их действительным изменением.
Основной алгоритм супервизорного обучения МПТ использует принцип обратного распространения ошибки и назван back propagation error (б/-1/:)-алгоритмом. ВРб-алгоритм позволяет обучить МПТ для выполнения специфичных нелинейных преобразований или решения ассоциативных задач (аппроксимации зависимостей, идентификации и классификации образов, диагностики и пр.), которые выражаются в терминах входных и выходных образов. Парные отношения между входами и выходами будем называть обучающими примерами. Обучение МПТ состоит в коррекции всех весов нейронов таким образом, чтобы разность между действительными и желаемыми выходами, усредненная по всем примерам, была бы как можно меньше. Фактически ВРР-алгоритм обеспечивает итерационное решение невыпуклой оптимизационной задачи для специально сконструированной функции ошибки (функции цены).
Лучше всего объяснить ВРЕ-алгоритм в его базисной форме, рассмотрев обучение однослойного персептрона. Выражение для выхода персептрона с гиперболически-тангенциальной функцией активации имеет вид.
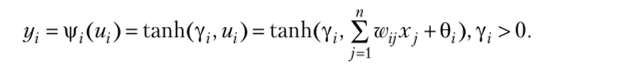
Цель обучения — минимизировать мгновенную квадратичную ошибку модификацией весов т. е. 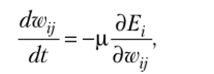
Задача обучения формулируется так: при заданном текущем наборе весов w, j и порогов 0, = ш,0 требуется определить, как увеличить или уменьшить эти параметры, чтобы локальная ошибка Е, стала минимальной.
Для решения используется правило пошагового градиентного спуска.
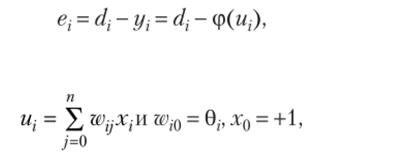
где р — положительный параметр обучения, определяющий скорость сходимости.
Учитывая, что мгновенная ошибка выражается как где 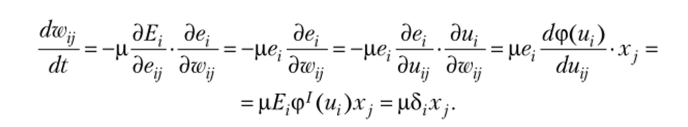
и применяя цепное правило пошагового градиентного спуска, получим.
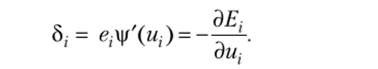
Здесь 5, — обучающий сигнал, или локальная ошибка, в виде.
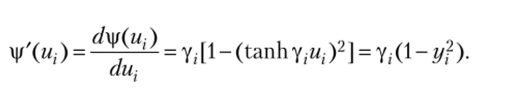
Если функция активации сигмоидальная, то производная выражается так 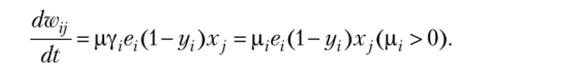
В этом случае.
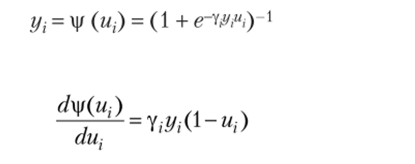
Заметим, что весовая коррекция стабилизирует, если г/, становится равной -1 или +1, так как частная производная dyi / dujt равная (1 — г/, —2)у, достигает максимума для г/, = 0 и минимума для у = 1.
При униполярной сигмоидной функции активации.
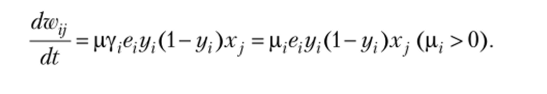
получим и, следовательно:
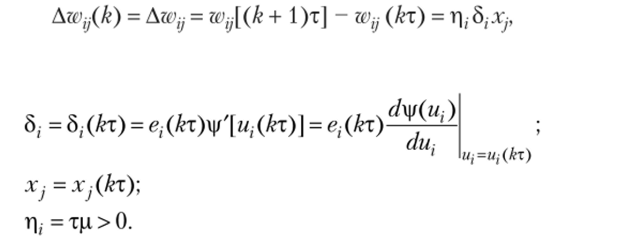
Здесь частная производная дух / ди} достигает максимума при yi = 0,5 и минимума при yt = 0,1.
Веса входов обычно изменяются итерационно, и нейрон постепенно получает набор весов, позволяющий решить задачу. Изменение веса wV) может определяться по формуле.
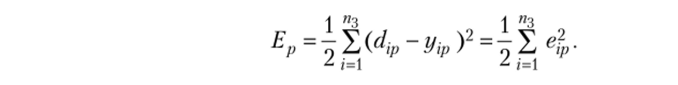
где Теперь рассмотрим стандартный В РЕ- алгоритм для МПТ.
Пусть МПТ состоит из трех слоев с щ, пъ щ количествами элементов в слоях соответственно и п0 входов в первый слой. Поведение сети должно быть определено на базисе набора обучающих примеров. Каждый обучающий пример составляется из п0 входных сигналов X: (j = 1, …, п0) и пъ соответствующих желаемых выходных сигналов d, (i — 1, …, п3). Обучение МПТ эквивалентно нахождению значений всех весов, таких, что желаемые выходы получаются при соответствующих входах. Более того, обучение МПТ состоит в регулировании всех весов, чтобы ошибка между dip и yip примера была бы усредненной и минимальной (по возможности близкой к нулю) по всем р примерам.
Стандартный ВРЕ-алгоритм использует пошаговый градиентный спуск для минимизации среднеквадратичной функции выхода.
Локальная функция ошибки (для p-то примера) имеет форму.
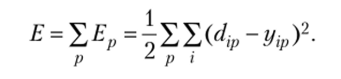
Глобальная функция ошибки является суммой локальных ошибок, т. е.
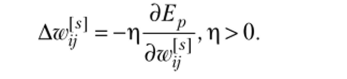
Рассмотрим применение подхода online для определения весов на входах нейронов разных слоев из условия достижения сетью минимума ошибки Е при отображении примеров.
Используем последовательно подаваемые на вход сети обучающие образы, выбираемые в случайном порядке. Для каждого примера веса (s = 1, 2, 3) изменяются добавлением Awj пропорционального градиенту Еру что может быть записано как.

Показано, что если параметр г| достаточно мал, эта процедура минимизирует глобальную ошибку Е = ??/г
Такие уравнения могут быть реализованы аппаратно — аналоговыми электронными цепями, или программно — в виде итерационных алгоритмов.
Рассмотрим теперь технику batch learning, в которой градиентный поиск проводится для минимизации локальной ошибки Ер. Заметим, что это не точный алгоритм градиентного спуска, а эвристический подход, увеличивающий скорость сходимости процесса обучения.
Сначала получим коррекции весов для нейронов третьего слоя МПТ.
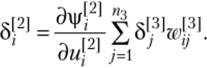
Таким образом, локальная ошибка во втором слое может быть вычислена по формуле.
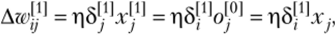
Аналогично выведем формулу для коррекции весов в первом слое:
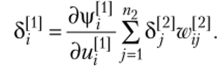
где локальная ошибка.
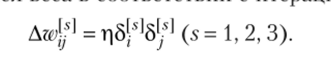
Итак, локальная ошибка внутренних (скрытых) слоев определяется на основе локальных ошибок верхних слоев. Стартуя от высшего наружного (выходного) слоя, можно вычислить 8-Ч затем распространить ее назад к более низкому слою.
Таким образом, стандартный ВРЕ-алгоритм может быть выполнен путем реализации следующих шагов.
Шаг 1. Инициализируются все веса wp малыми случайными значениями (обычно ±0,5 делится на число элементов, которые подсоединены к элементу).
Шаг 2. Вводится пример из класса обучающих примеров (входо-выходных пар) и вычисляются действительные выходы всех нейронов при дей;
ы ствующих значениях весов w-
Шаг 3. Определяется желаемый выход и оцениваются локальные ошибки 8[-А1 для всех слоев.
Шаг 4. Вычисляются неся в соответствии с итепа и ионной формулой.
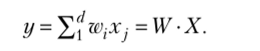
Шаг 5. Вводится следующий обучающий пример и продолжается обучение после возврата к шагу 2.
Все обучающие примеры реализуются циклически, пока веса не стабилизируются, т. е. пока все ошибки существующего набора не станут приемлемо низкими и сеть не стабилизируется. После обучения МПТ обычно приобретает свойство генерализации, т. е. способность давать надлежащий ответ на входные образы, не представленные в течение обучающего процесса. Способность к генерализации в МПТ может быть интерпретирована так. МПТ выполняет нелинейные преобразования (отображения) между входным и выходным пространствами. Обучение его может быть рассмотрено как синтез сети для аппроксимации многомерной функции. При этом выполняется гинеркубовая реконструкция функции в многомерном пространстве, но конечному набору данных точек (обучающих примеров). С этой точки зрения генерализция — не что иное, как интерполяция тестового набора на реконструированном гиперпространстве.
Стандартный ВРЕ-алгортм имеет недостатки. Во-первых, обучающий параметр г должен быть малым для минимизации тотальной оценки Е.
Но для малых Г| процесс обучения очень замедлен. Если Г) больше, то имеют место паразитные осцилляции, которые могут мешать сходимости к желаемому решению. Более того, если ошибка содержит много локальных минимумов, то сеть может попасть, как в ловушку, в некоторый локальный минимум или застрять на очень плоском «плато» функции ошибки.
Можно дать некоторые рекомендации по обучению МПТ с использованием ВРЕ-алгоритма. Так, метод online обычно более эффективен, чем batch learning, когда число обучающих примеров очень большое, поскольку последний требует памяти для аккумулирования локальных коррекций. Обычно метод online реализуется быстрее, чем batch learning для больших по размерности задач. Однако если требуется высокая точность отображения функции, следует выбирать batch learning, хотя он и приводит к применению более сложных оптимальных процедур вычисления весов при использовании ДРЕ-алгоритма.
Сети Кохонена. Обучение без учителя (несупервизорное) предполагает, что НС самостоятельно обрабатывает входную информацию с целью аппроксимации скрытых в ней зависимостей или классификации образов [7]. При этом предполагается наличие некоторой целевой установки, определяющей действия сети при обработке входной информации. Обычно сеть, работающая без учителя, может сжимать и кластеризовать информацию, выделять признаки, формировать систему классов образов, содержащихся во входной информации.
При обучении без учителя прямонаправлеппые НС самостоятельно формируют выходы в результате обработки информации и в результате адаптируются к поступающей на вход информации. При этом в процессе самообучения НС предполагается минимизация некоторого функционала. Исходная информация поступает в сеть в виде набора входных векторов Хр. Важно выделить имеющуюся в ней закономерность, отличающуюся от входного шума. НС находит компактное описание избыточных данных (обобщает их). Сжатие данных и уменьшение степени их избыточности могут облегчить последующую работу с ними и выделить существующие признаки. Поэтому самообучающиеся НС часто используют именно для предобработки «сырых» данных. Практически такие сети кодируют входную информацию компактным при заданных ограничениях кодом.
В простейшем случае нейрон с одним выходом и d входами обучается на наборе d-мерных данных {Хр, р = 1, 2,…, Р} и является индикатором.
Выход такого нейрона определяется выражением.
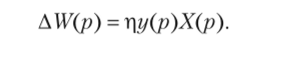
Амплитуда выхода у может служить индикатором принадлежности входной информации к заданной группе примеров.
В 1949 г. физиолог Д. Хебб эмпирически установил, что в естественных НС изменение весов у-го нейрона при предъявлении ему /;-го примера пропорционально его входам и выходу, т. е. в векторном виде эго соответвует правилу.
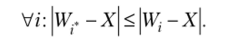
Если рассматривать обучение как оптимизацию, то согласно правилу Хебба нейрон стремится увеличить амплитуду своего выхода. Напротив, обучение с учителем, как известно, уменьшает ошибку воспроизведения примера (эталона). Если нет эталона, как в случае обучения без учителя, минимизация амплитуды у ведет к уменьшению чувствительности к входам, а максимизация у по правилу Хебба делает нейрон более чувствительным к различиям его входной информации, т. е. он становится полезным индикатором. Однако обучение в таком виде на практике неприменимо, поскольку приводит к неограниченному возрастанию весов.
Наиболее известным вариантом НС, обучающихся без учителя, являются сети Кохонена [7, 15]. Они относятся к прямонаправленным НС с соревновательным обучением, при котором ищутся нейроны-победители. Выходы сети Кохонена максимально коррелированны, и активность всех нейронов, кроме победителя, равна нулю. Победитель (г*) выбирается так, чтобы его вектор UC, определенный в «(-мерном пространстве, находился ближе к входному вектору X, чем у всех остальных:
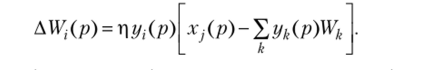
Если использовать правило обучения нейронов, обеспечивающее одинаковую нормировку всех весов |W]| = 1, то победителем будет нейрон, дающий максимальный отклик на входной стимул, т. е. !iW.X> WtX. Выход этого нейрона усиливается, а остальных подавляется до нуля.
Базовый алгоритм обучения соревновательного слоя нейронов строится по правилу:
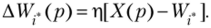
Это правило обучения требует специального способа кодирования выходной информации (здесь только г*-й нейрон имеет ненулевой (единичный) выход):
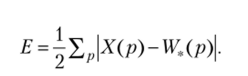
На практике избегают существования «мертвых» нейронов, которые некогда не выигрывают. Простой способ избегать этого — выбрать начальные значения весов как случайные значения входов в выборке обучения.
Обычно используется batch learning, веса изменяются только после прогонки всех примеров и их усреднения.
Записав правило соревновательного обучения в градиентном виде.
(ДМЛ = -Т1-—, можно убедиться в том, что оно минимизирует функцию ' ' oW
ошибки в виде Это означает, что сеть находит такие усредненные прототипы (кластеры), которые минимизируют ошибку огрубления данных. Заметим, что в этом случае число кластеров равно числу нейронов. В идеале можно сделать адаптивный подбор числа нейронов путем «деления» нейронов прототипов.
НС, понижающие размерность (d —" ?п), имеют сложность обучения, характеризуемую числом итераций, порядка ~PW2 (Р — число примеров, W — число весов). Для однослойной сети W ~ РсРт или с = P (dA / k2), где k = d / т, т. е. имеет место сжатие информации.
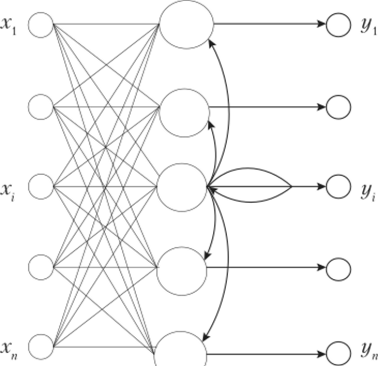
До сих пор рассматривались НС, в которых нейроны выходного слоя не были упорядочены по входному вектору X. Небольшой модификацией соревновательного обучения можно добиться корреляции положения нейрона в выходном слое и положения прототипов в многомерном пространстве входов X. Так строятся самообучающиеся карты Кохонена. Схема такой НС представлена на рис. 9.2. Обычно используются двумерные варианты однослойной сети Кохонена (отсюда название «карта»). В ней сочетаются квантование данных и понижение их размерности.
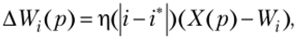
Рис. 9.2. Сеть Кохонена.
В соревновательное правило обучения такой сети вводится информация о расположении нейронов в выходном слое, т. е. нейроны помечаются векторным индексом i и вводится расстояние между нейронами i-j в слое сети. Такое правило обучения реализуется алгоритмом Кохонена, который вычисляет приращения весов, т. е.
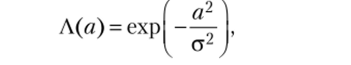
где i — векторный индекс нейрона в карте (одноили двумерной); i-j ~ расстояние между нейронами в слое.
Функция сходства Лш-Г) равна единице для нейрона-победителя с индексом I* и постепенно спадает с расстоянием по закону.
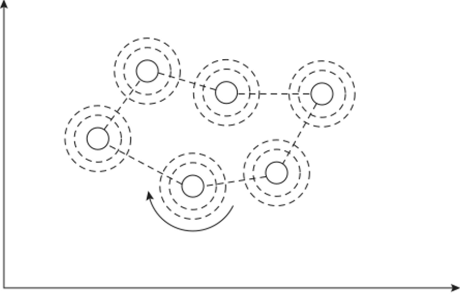
где, а — радиус взаимодействия нейронов.
Обучение по алгоритму Кохонена напоминает натягивание эластичной сети прототипов на массив данных обучающей выборки. Эластичность по мере обучения постепенно увеличивается (рис. 9.3).

Рис. 93. Кластеризация.
Получаемая топографическая карта дает наглядное представление о структуре данных в многомерном входном пространстве. Визуализация многомерной информации — главное применение карт Кохонена.
Итак, сущность алгоритма Кохонена состоит в следующем. В многомерное пространство данных погружается двумерная сетка. Она изменяет свою форму так, чтобы аппроксимировать область данных. Каждой точке данных ставится в соответствие ближний к ней узел сетки (точка данных получает координату на сетке). Распределение данных на двумерной сетке (карге) позволяет судить о локальной структуре многомерных данных. Веса входов нейронов в сети Кохонена являются координатами в исходном многомерном пространстве.
Диапазон применения сетей Кохонена достаточно широк. Наиболее часто они используются для кластеризации при обработке потоков данных. Они могут дать хороший эффект и при распознавании образов, особенно если границы образа размыты. При экономическом анализе сети Кохонена с раскраской позволяют выявлять тенденции в изменениях групп параметров и влияние на них различных экономических индикаторов.
Пример применения самообучающейся карты Кохонена
В одном из приложений карта Кохонена размерностью 20×20 (400 нейронов) использовалась для оценки группы российских банков с двумерным финансовым индикатором (рис. 9.4).

Рис. 9.4. Карта Кохонена
В ячейке карты собраны банки с одинаковым финансовым состоянием. Чем дальше на карге координаты банков, тем больше отличий у них в финансовом портрете. Достоинства таких карт проявляются после нанесения на них какой-либо графической информации. Например, на карте могут быть нанесены банки с отозванными лицензиями. Часть карты, где оказалось много банков с отозванной лицензией, можно считать зоной риска. Сравнивая положение остальных банков на карте, можно определить признаки неблагополучия в их финансовой политике.
Раскраска карт Кохонена позволяет выявить взаимосвязи разных факторов. Здесь прослеживается аналогия с географическими картами разных типов на одной сетке. Так, можно раскрасить карту финансового положения банков по i статьям баланса, отобразив эти статьи для всех банков. Раскрашенная карта может отображать размеры банков в логической шкале: например, клетки, отличающиеся на одну цветовую градацию, содержат банки с пятикратным отношением активов.
Банки разных размеров располагаются не хаотично, а регулярно. Это свидетельствует о значимости размера банка при выборе им финансовой стратегии. Можно также выделить группы банков по размерам.