Упражнения с пояснениями

В правом верхнем углу отображается количество наблюдений {Number of obs), R2 {R-squared), скорректированный R2 {Adj R-squared), напомним, об этом показателе будет сказано в гл. 5. О других показателях будет сказано в упражнении 4.4. Упражнение 3.1. Используя статистический пакет Excel, по данным из базы concrete оценим зависимость выпуска фирм, производящих бетон (переменная q) от количества… Читать ещё >
Упражнения с пояснениями (реферат, курсовая, диплом, контрольная)
Упражнение 3.1. Используя статистический пакет Excel, по данным из базы concrete оценим зависимость выпуска фирм, производящих бетон (переменная q) от количества рабочих на этих фирмах (переменная Г): qi = р() + р,/х + е,.
Найдем в полученных результатах оценки коэффициентов модели, количество наблюдений, RSS, TSSy ESS, R2.
Решение. Чтобы построить регрессионную модель в пакете Excel, необходимо во вкладке Данные выбрать опцию Анализ данных (Data Analysis, рис. 3.2).
Далее, нажав на кнопку Анализ данных, следует выбрать опцию Регрессия (рис. 3.3).
После того как вы нажмете на кнопку ОК, на экране появится новое окно с опциями регрессионного анализа (рис. 3.4).
В поле Входной интервал Y необходимо выбрать столбик, который будет отвечать за значения регрессанта (это может быть лишь один столбик). В графе Вход-

Рис. 3.2. Кнопка Анализ данных в Excel
1 Задача взята из работы [10, с. 66].
Рис. 3.3. Выбор регрессионного анализа в Excel
Рис. 3.4. Окно параметров регрессии в Excel
пой интервал X необходимо выбрать столбики, которые содержат значения регрессоров. Опция Метки, если активна, позволяет трактовать первую строку как названия переменных. Опция Константа — ноль позволяет строить модели без константы. Опция Уровень надежности позволяет установить значение 1 — а для данной модели (где, а — уровень значимости). В разделе Параметры вывода можно устанавливать, куда выводятся результаты регрессии (в данном случае мы выведем результаты на этот же лист, так как часто удобно держать данные и результаты оценки модели на одном листе).
С помощью опции Остатки модели можно получить ряд остатков модели. С помощью опции Стандартизированные остатки вы можете получить ряд остатков, деленных на свое стандартное отклонение. График остатков отражает зависимость значения остатков от значений каждого регрессора. График подбора показывает зависимость реальных значений регрессанта от каждого регрессора и зависимость предсказанных значений регрессанта от каждого регрессора. Таким образом, благодаря этому графику можно судить о качестве подгонки модели. При построении Графика нормальной вероятности по оси ординат откладываются значения регрессанта, а по оси абсцисс — процентили нормального распределения.
После того как мы разобрались со всеми опциями, давайте оценим нашу регрессию в Excel.
Для этого в качестве регрессанта выберем переменную q , а в качестве регрессора — / (рис. 3.5).
Далее, нажав на кнопку ОК, получаем результаты (рис. 3.6).
Теперь более подробно рассмотрим полученные результаты, переведя их в обычные таблицы (табл. 3.1).
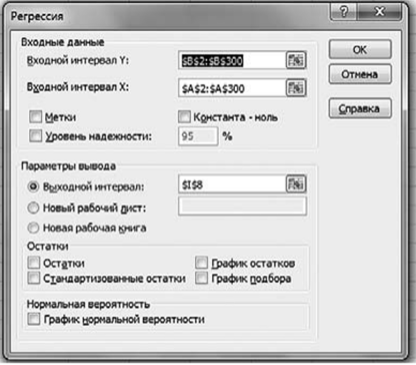
Рис. 35. Окно параметров регрессии с введенными значениями в Excel
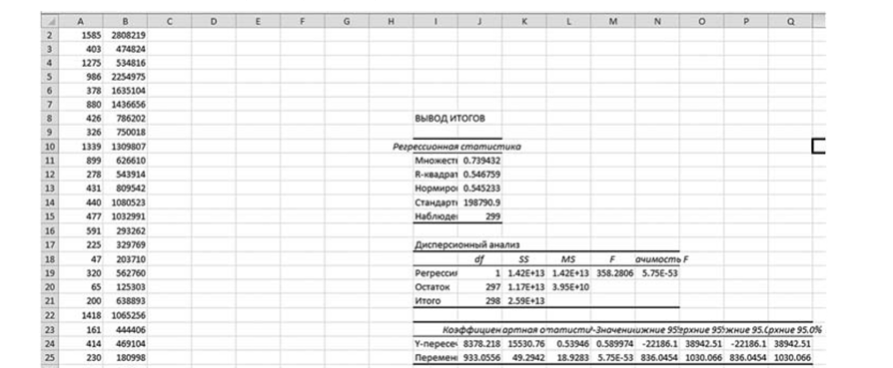
Рис. 3.6. Вывод результатов оценивания регрессии в Excel
Таблица 3.1
Табличная выдача из Excel
Регрессионная статистика | ||||||||||
Множественный R | 0,739 432. | |||||||||
R- квадрат. | 0,546 759. | |||||||||
Нормированный Д-квадрат. | 0,545 233. | |||||||||
Стандартная ошибка. | 198 790,9. | |||||||||
Наблюдения. | ||||||||||
Дисперсионный анализ | ||||||||||
Параметр | df | SS | MS | F | Значимость F | |||||
Регрессия. | 1,42?+13. | 1,42?+13. | 358,2806. | 5,75?-53. | ||||||
Остаток. | 1,17?+13. | 3,95?+10. | ||||||||
Итого. | 2,59?+13. | |||||||||
Коэффициенты. | Стандартная ошибка. | t-статистика. | Р-значение. | Нижние. 95%. | Верхние. 95%. | |||||
У-пересечение. | 8378,218. | 15 530,76. | 0,53 946. | 0,589 974. | — 22 186,1. | 38 942,51. | ||||
Переменная X,. | 933,0556. | 49,2942. | 18,9283. | 5,75?-53. | 836,0454. | 1030,066. | ||||
В полтаблице «Регрессионная статистика» Множественный R — это коэффициент корреляции между регрессантом и регрессором. Строкой ниже Excel выдает значение R2, равное 0,546 759. Еще чуть ниже вы можете обнаружить значение нормированного (или, по-другому, скорректированного {adjusted)) R2 (о данном показателе будет рассказано в гл. 5). В конце вам дано значение количества наблюдений. О стандартной ошибке регрессии (MSE) будет рассказано в следующей главе в упражнении 4.1.
Количество наблюдений равно 299. Оценка свободного члена равна 8378,218, оценка коэффициента наклона равна 933,0556.
В разделе «Дисперсионный анализ» в третьем столбике даны значения ESS, RSS и TSS (соответственно 1,42?+13, 1Д7Е+13 и 2,59?+13). Напомним, что, например, число 1,42?+13 следует читать как 1,42−1013.
О других показателях информация дана в упражнении 4.1.
Упражнение 3.2. Используя статистический пакет Stata, по данным из базы concrete оценим зависимость выпуска фирм, производящих бетон (переменная q) от количества рабочих на этих фирмах (переменная /): qi = Р0 + р,/у + г,. Найдем в полученных результатах оценки коэффициентов регрессии, количество наблюдений, RSS, TSS, ESS, R2.
Решение. Необходимую регрессию можно оценить с помощью команды.
II reg q !
Получим.
Source |. | SS. | df. | MS. | Number of obs F (1, 297). | =. |
|
Model I. | 1.4158e+13. | 1.4158e + 13. | Prob > F. | =. | 0.0000. | |
Residual I *. | 1.1737e+13. | 3.9518e+10. | R-squared Adj R-squared. | =. |
| |
Total I. | 2.5895e+13. | 8.6897e+10. | Root MSE. | =. | 2.0e+05. |
q 1. | Coef . | Std. Err. | t. | P> 111. | [957, Conf. | Interval]. |
1 1. _cons I. |
|
|
|
|
|
|
В правом верхнем углу отображается количество наблюдений {Number of obs), R2 {R-squared), скорректированный R2 {Adj R-squared), напомним, об этом показателе будет сказано в гл. 5. О других показателях будет сказано в упражнении 4.4.
В левом верхнем углу во втором столбике отображены ESS {Model), RSS {Residual), TSS {Total).
Оценка свободного члена равна 8378,218, оценка коэффициента наклона — 933,0556.
Об остальных показателях информация дана в упражнении 4.4.
Упражнение 3.3. Используя статистический пакет Stata, но данным базы concrete оценим зависимость выпуска фирм, производящих бетон (переменная q) от количества рабочих на этих фирмах (переменная /): q{ = р/. + s;. Найдем в полученных результатах оценки моделей количество наблюдений, RSS, TSS, ESS, R2.
Решение. Для оценки модели без константы нужно использовать опцию nocons: || reg q 1, nocons.
Получим.
Source. | ss. | df. | MS. | Number of obs F (1, 298) Prob > F R-squared Adj R-squared Root MSE. | = 299 = 680.78 = 0.0000 = 0.6955 = 0.6945 = 2.0e+05. | ||
Model. Residual. |
| 2.6839e+13 1.1748e+13. |
| 2.6839e + 13 3.9424e+10. | |||
Total. | 3.8587e+13. | 1.2905e + ll. | |||||
q. | Coef . | Std. | Err. t. | P> 111. | [957. Conf. | Interval]. | |
950.9349. | 36.44 573 26.09. | 0.000. | 879.2113. | 1022.658. | |||
Можно заметить, что коэффициент наклона изменился, так как константа была убрана из модели. Значение R2 теперь не поддается интерпретации.
Упражнение 3.4. Используя статистический пакет R, по данным базы concrete оценим модель вида qi = (30 + Р/ + ?,• Найдем в полученных результатах оценки коэффициентов моделей, R2.
Решение. В статистическом пакете R для построения регрессий можно воспользоваться командой 1 т. Оценим модель вида Yt = ро + Р, Х- + Чтобы просмотреть полученные результаты, достаточно просто еще раз ввести в командную строку имя модели, для которой были сохранены результаты оценки регрессии (в этом упражнении она называется reg):
data <- read. csv («concrete.csv», header = TRUE, sep = «;»).
reg <- lm (q ~ 1, data = data).
reg.
Получим.
Call:
lm (formula = q — 1, data = data).
Coefficients:
- (Intercept) 1
- 8378.2 933.1
Под названиями переменных {Intercept — это свободный член) даны оценки коэффициентов. Оценка свободного члена равна 8378,2, оценка коэффициента наклона-933,1.
Чтобы получить более полную информацию об оцененной регрессии, необходимо воспользоваться командой.
|| summary (reg).
В результате ее выполнения получим.
Call:
lm (formula = q ~ 1, data = data).
Residuals:
Min IQ Median 3Q Max.
— 727 143 -45 526 -11 347 27 583 1 326 604.
Coef f icients:
PrOltl).
0.59.
<2e-16 ***.
0.05 '.' 0.1 ' ' 1.
Estimate Std. Error t value.
- (Intercept) 8378.22 15 530.76 0.539
- 1 933.06 49.29 18.928
Signif. codes: 0 '***' 0.001 '**' 0.01.
Residual standard error: 198 800 on 297 degrees of freedom Multiple R-squared: 0.5468, Adjusted R-squared: 0.5452 F-statistic: 358.3 on 1 and 297 DF, p-value: < 2.2e-16.
В подтаблице Residuals дана информация о полученных остатках модели: минимум (Min), значение первого квантиля (1Q), медианы (Median), третьего квантиля (3Q), максимум (Мах). Вторая подтаблица подробно рассмотрена в упражнении 4.4.
Показатель Multiple R-squared обозначает значение R2 для данной модели, Adjusted R-squared — значение скорректированного R2. Остальные показатели описаны в упражнении 4.4.