Методы быстрого поиска в базах данных

В результате работы алгоритма получается набор локальных выравниваний, которые затем комбинируются с учетом штрафов за пропуски для получения оптимального локального выравнивания с пропусками. Такие выравнивания строятся для каждой отмеченной в ходе первоначального поиска последовательности. Для всех выравниваний производится статистическая оценка значимости (см. подпараграф 3.1.3), и наиболее… Читать ещё >
Методы быстрого поиска в базах данных (реферат, курсовая, диплом, контрольная)
Хотя для проведения парных выравниваний были разработаны эффективные алгоритмы, позволяющие получать оптимальные выравнивания за время, пропорциональное квадрату длин выравниваемых последовательностей, для проведения быстрого поиска в больших базах данных последовательностей, содержащих, например, более 400 000 последовательностей, данные алгоритмы не подходят, так как подобный поиск может занимать несколько часов. Данная проблема была решена путем создания специализированных алгоритмов, позволяющих быстро получать выравнивания, близкие к оптимальным.
BLAST. Один из таких алгоритмов — BLAST (сокращение от Basic Local Alignment Search Tool — простой инструмент для поиска локальных выравниваний), получивший наибольшее распространение в задачах сравнительного моделирования.
Вместо того чтобы производить множество парных выравниваний исследуемой последовательности со всеми последовательностями из базы данных, BLAST разбивает исследуемую последовательность на множество перекрывающихся олигопептидов. В стандартной реализации алгоритма в качестве таких фрагментов принимаются триплеты аминокислот (рис. 3.8). После разделения последовательности полученные фрагменты используются для поиска совпадений. Важно отметить, что поиск находит как абсолютно идентичные совпадения, так и биологически значимые, например триплеты с заменой одного гидрофобного остатка на другой. После обнаружения совпадения алгоритм пытается расширять полученное выравнивание в обе стороны, оценивая после каждого шага расширения сумму пар, формирующих выравнивание согласно выбранной матрице замещения, и решая, стоит ли продолжать расширение дальше.
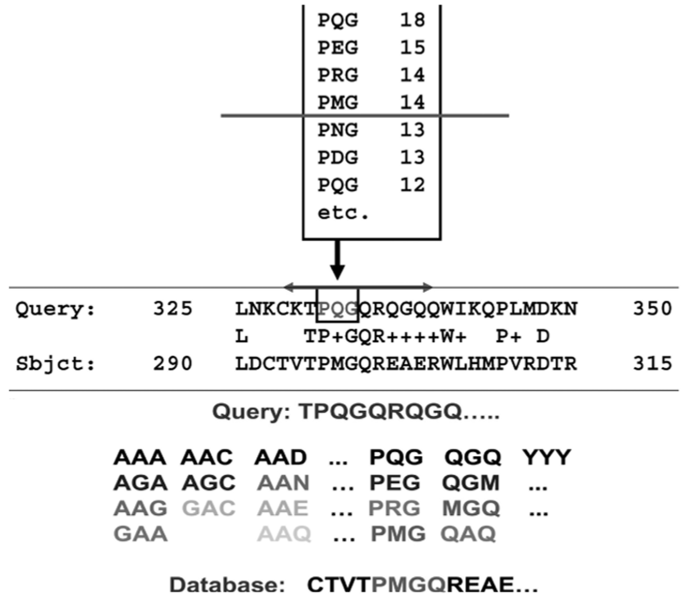
Рис. 3.8. Поиск первичного соответствия триплетов аминокислот в исследуемой последовательности (Query) и последовательности из базы
данных (Sbjct) (я); пример расширения обнаруженного соответствия
на одну позицию вправо (Query — исследуемая последовательность, Database — последовательность из базы данных) (б)
В результате работы алгоритма получается набор локальных выравниваний, которые затем комбинируются с учетом штрафов за пропуски для получения оптимального локального выравнивания с пропусками. Такие выравнивания строятся для каждой отмеченной в ходе первоначального поиска последовательности. Для всех выравниваний производится статистическая оценка значимости (см. подпараграф 3.1.3), и наиболее значимые выравнивания составляют результат поиска.
FASTA. FASTA, как и BLAST, является эвристическим алгоритмом для быстрого поиска похожих последовательностей в больших базах данных. Стратегия алгоритма основана на поиске наиболее значимой диагонали на матрице выравнивания. Атгоритм состоит из четырех фаз:
- 1) хеширование,
- 2) первая оценка,
- 3) вторая оценка,
- 4) выравнивание.
Цель хеширования — определить места точных совпадений сравниваемых последовательностей длинной более k элементов. Для каждого из отмеченных совпадений запоминается номер диагонали, к которой принадлежит совпадение. Номер диагонали определяется по разнице индексов формирующих ее элементов (/ — j), т. е. центральная диагональ имеет индекс 0, диагонали выше центральной обладают положительными индексами, ниже — отрицательными. Серия совпадений, располагающихся на одной диагонали, соответствует выравниванию без пропусков. Таким образом, используя матрицу замещения и штрафуя за пропуски, мы можем оценить значимость каждой из диагоналей выравнивания. В результате хеширования отбираются 10 лучших диагоналей.
На втором этапе для каждого из отобранных фрагментов строится локальное выравнивание, и лучшее из них возвращается пользователю как результат initl.
Третий этап пытается сформировать оптимальное выравнивание из нескольких выравниваний второго этапа. Результат возвращается пользователю с названием initn.
Наконец, последний этап строит выравнивание по алгоритму SW, ограничивая его окном из восьми диагоналей, отсчитывая их от результата initl. Данное выравнивание именуется opt.
Эти четыре этапа повторяются для каждой последовательности из базы данных, после чего производится статистическая оценка значимости получаемых выравниваний.