Поиск информации в файлах данных

Ассоциативный массив с точки зрения интерфейса удобно рассматривать как обычный массив, в котором в качестве индексов можно использовать не только целые числа, но и значения других типов — например, строки. В паре значение называется значением, ассоциированным с ключом. Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться. Чем больше текст, тем… Читать ещё >
Поиск информации в файлах данных (реферат, курсовая, диплом, контрольная)
Постановка задачи
- 1. Создать файл данных, описывающий данную предметную область. Выбрать одно из полей как ключ поиска.
- 1. На основе файла создать словарь, состоящий из пар: КЛЮЧ- № записи.
- 2. Упорядочить словарь по возрастанию ключей.
- 3. Реализовать поиск данных в файле по ключу с использованием словаря, используя прямой доступ к записям файла
- 4. Сравнить времена поиска со словарем и без словаря (графики и таблицы)
- 2. Исследовать эффективность алгоритмов поиска всех вхождений образцов в тексте, для различных образцов, используя КМПалгоритм.
Краткое теоретическое описание
Ассоциативный массив (словарь) — абстрактный тип данных (интерфейс к хранилищу данных), позволяющий хранить пары вида «(ключ, значение)» и поддерживающий операции добавления пары, а также поиска и удаления пары по ключу:
- · INSERT (ключ, значение)
- · FIND (ключ)
- · REMOVE (ключ)
Предполагается, что ассоциативный массив не может хранить две пары с одинаковыми ключами.
В паре значение называется значением, ассоциированным с ключом. Семантика и названия вышеупомянутых операций в разных реализациях ассоциативного массива могут отличаться.
Операция FIND (ключ) возвращает значение, ассоциированное с заданным ключом, или некоторый специальный объект UNDEF, означающий, что значения, ассоциированного с заданным ключом, нет. Две другие операции ничего не возвращают (за исключением, возможно, информации о том, успешно ли была выполнена данная операция).
Ассоциативный массив с точки зрения интерфейса удобно рассматривать как обычный массив, в котором в качестве индексов можно использовать не только целые числа, но и значения других типов — например, строки.
Существует множество различных реализаций ассоциативного массива.
Самая простая реализация может быть основана на обычном массиве, элементами которого являются пары (ключ, значение). Для ускорения операции поиска можно упорядочить элементы этого массива по ключу и осуществлять нахождение методом бинарного поиска. Но это увеличит время выполнения операции добавления новой пары, так как необходимо будет «раздвигать» элементы массива, чтобы в образовавшуюся пустую ячейку поместить новую запись.
Поиск — нахождение какой-либо конкретной информации в большом объеме ранее собранных данных.
Данные делятся на записи, и каждая запись имеет хотя бы один ключ. Ключ используется для того, чтобы отличить одну запись от другой.
Целью поиска является нахождение всех записей подходящих к заданному ключу поиска.
Алгоритм Кнута-Морриса-Пратта КМР осуществляется сдвиг слова на каждом шаге алгоритма на некоторое переменное количество символов. Таким образом, перед тем как осуществлять очередной сдвиг, необходимо определить величину сдвига. Для повышения эффективности алгоритма необходимо, чтобы сдвиг на каждом шаге был бы как можно большим.
Если j определяет позицию в слове-образце, содержащую первый несовпадающий символ то величина сдвига определяется как j-dj. Значения D — таблица сдвигов определяется как размер самой длинной последовательности символов слова, непосредственно предшествующих позиции j (суффикс), которая полностью совпадает с началом слова (префикс). D зависит только от слова и не зависит от текста. Для каждого j будет своя величина D, которую обозначим dj. Перед поиском осуществляется формирование D.
Алгоритм КМП результативно находит подстроку в строке. Поиск информации — одно из основных использований компьютера. Одна из простейших задач поиска информации — поиск точно заданной подстроки в строке. Тем не менее, эта задача чрезвычайно важна — она применяется в текстовых редакторах, СУБД, поисковых машинах…
Результаты работы программы
- 1) 2)
- 8540 символов 145 100 символов
Время поиска по ключу: 8 мс Время поиска по ключу: 26 мс Время поиска со словарем: 3 мс Время поиска со словарем: 18 мс.
· Чем больше текст, тем больше времени занимает поиск и с ключом, и со словарем. Но на протяжении всего эксперимента поиск по словарю происходит быстрее.
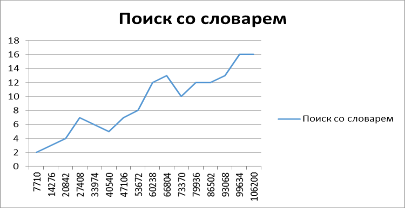
Рис. 2. Поиск с использованием словаря
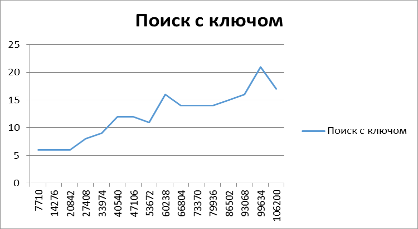
Рис. 3. Поиск с использование ключа
Таблица 1. Алгоритм Кнута-Морриса-Пратта.
Длина подстроки. | Время (мс). |