Обзор существующих методов

Weighted Slope One является отличным методом построения рекомендательных систем. Имея низкие требования к памяти и большую скорость работы, он показывает большую эффективность при наличии большого числа пользователей. Однако, очевидной проблемой подобного подхода является проблема холодного старта, которая, впрочем, относится ко всем предметно-ориентированным алгоритмам коллаборативной… Читать ещё >
Обзор существующих методов (реферат, курсовая, диплом, контрольная)
Для создания рекомендационных систем существует несколько методов, которые в основном базируются на коллаборативной фильтрации:
- · Фильтрация, основанная на схожести пользователей;
- · Фильтрация, основанная на схожести объектов (предметов);
- · Фильтрация, основанная на модели;
- o Модель Байеса;
- o Регрессионная модель;
- o Кластерная модель;
Также достаточно распространены методы, основанные на факторизации.
- · Неотрицательная матричная факторизация (NMF);
- · Сингулярное разложение (SVD);
Коллаборативная фильтрация
Коллаборативная фильтрация — это метод, позволяющий предсказать неизвестные предпочтения пользователя на основе известных оценок и/или поведения других пользователей (Segaran 2007).
Работа всех видов данного метода основывается на утверждении о том, что пользователи, одинаково оценившие предметы системы, имеют склонность одинаково оценить и другие предметы системы.
Также одним из допущений является тот факт, что пользователи дают оценку предмету системы по выборочной шкале, например, оценивая фильм от одной до десяти звезд на сайте imdb.com (рис. 1).
Данное допущение является достаточно важным, так как не во всех системах есть возможность явно собирать оценки пользователей. В таких случаях прибегают к неявному сбору информации и оценке поведения, например, записывая просмотренные ролики на YouTube и рекомендуя связанные с ними материалы.

Рисунок 1. Пример оценки фильма на сайте imdb.com.
Коллаборативная фильтрация традиционно делится на два подхода. Первым, и самый распространенным, является подход, основанный на соседстве (сходстве) пользователей. Его суть заключается в анализе предыдущих оценок или поведения пользователя, поиск других пользователей, имеющих схожую «историю» и вычисление прогноза для неизвестных оценок. 3.
В классическом случае строится матрица пользователей-предметов, значения в которой является оценками конкретного пользователя конкретного предмета. Те ячейки, в которых нет значений, являются неизвестными, то есть для данного предмета пользователь не выставил оценку, т. е. не пользовался (табл. 1).
Таблица 1. Пример матрицы пользователей-предметов.
«Даллаский клуб покупателей». | «Человек-паук». | «Волк с Уолл-стрит». | «12 лет рабства». | «Free-to-play». | |
Коля. | ; | ; | |||
Петя. | ; | ; | |||
Ипполит. | ; | ; |
Для определения соседства пользователей применяются несколько различных алгоритмов, таких как:
- · Манхэттонское расстояние;
- · Евклидово расстояние;
- · Коэффициент корреляции Пирсона;
Манхэттонское расстояние или расстояние городских кварталов является одним из базовых метод вычисления расстояния между двумя точками (1):
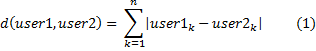
где.
user1, user2 — пользователи и их оценки;
n — количество предметов в матрице
Данное способ имеет недостаток в точности при малом заполнении матрицы, но также имеет простую реализацию и высокую скорость выполнения.
Евклидово расстояние имеет геометрические корни (теорема Пифагора) и вычисляется при помощи следующей формулы (2):

где.
user1, user2 — пользователи и их оценки;
n — количество предметов в матрице
Как и расстояние городских кварталов, данный метод имеет проблемы при незаполненной матрицей, но прост в разработке и дешев в выполнении.
Более точный способ определения соседства основан на коэффициенте корреляции Пирсона (3):

где.
user1, user2 — пользователи и их оценки;
n — количество предметов в матрице;
Значение corr (user1, user2) может быть от -1 до 1, где -1 соответствует абсолютному несовпадению пользователей, а 1 — абсолютному совпадению.
Алгоритмы, основанные на сходстве пользователей, могут быть достаточно полезны — они интуитивно понятны и просты в реализации.
Weighted Slope One.
Одним из самых эффективных алгоритмов в предметно-ориентированной коллаборативной фильтрации является алгоритм Weighted Slope One. Его суть заключается в поиске различий оценок между парами элементов и использовании этих различий для вычисления предсказаний1. Вычисление различий между элементами выполняется с помощью следующей формулы (4):
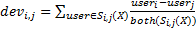
(4).
где
— число пользователей, оценивших и i-й, и j-й элемент;
user — оценки пользователя;
Само предсказание для оценки предмета вычисляется следующим образом (5):

(5).
где
— число пользователей, оценивших и i-й, и j-й элемент;
user — оценки пользователя;
Weighted Slope One является отличным методом построения рекомендательных систем. Имея низкие требования к памяти и большую скорость работы, он показывает большую эффективность при наличии большого числа пользователей. Однако, очевидной проблемой подобного подхода является проблема холодного старта, которая, впрочем, относится ко всем предметно-ориентированным алгоритмам коллаборативной фильтрации. Семейство алгоритмов Scope One используется в некоторых известных сервисах, таких как hitflip, сайт рекомендаций DVD и Value Investing News, новостной сайт фондовых бирж.
Вторым крупным видом коллаборативной фильтрации является фильтрация, основанная на модели. Рассмотрим некоторые из них.
Модель Байеса Одним из самых известных классификаторов является наивный байесовский классификатор. С его помощью делают рекомендации на категории каких-либо объектов. В его основе лежит вероятностная модель теоремы Байеса 6. Для работы этого алгоритмов необходимо создать модель Байеса для каждого пользователя, который оценивал какие-либо объекты, на основе содержания этих объектов (Для фильмов это могут быть актеры или жанры, для новостей — ключевые слова и категории). Для нахождения наиболее вероятной категории необходимо вычислить условные вероятности принадлежности какого-либо предмета к каждой категории и выбрать категорию, имеющую наибольшую вероятность (6):
Кластерная модель Одним из самых известных алгоритмов в кластерном анализе является метод k-means или k-средних. Он основан на разделении объектов или пользователей на группы — кластеры, которые создаются по некоторым общим признакам, а количество которых задается заранее. Суть алгоритма состоит в случайном выборе k центров кластера и уменьшении суммарного квадратичного отклонения пользователей или объектов от центра кластера. Формально это вычисляется с помощью следующей формулы (7):
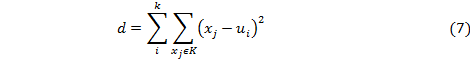
где.
k — количество векторов,
u — центр масс векторов из множества кластеров K