Результаты моделирования.
Модель формирования адаптивного поведения автономных агентов

В упрощенных версиях модели анализировалась возможность формирования цепочек действий одним самообучающимся агентом. Рассматривалось два варианта формирования цепочек. В первом варианте агент мог выполнять только 4 действия: питаться, двигаться вперед и поворачиваться направо либо налево. Считалось, что имелась только одна расположенная в определенной клетке порция пищи. Агенту необходимо было… Читать ещё >
Результаты моделирования. Модель формирования адаптивного поведения автономных агентов (реферат, курсовая, диплом, контрольная)
Моделирование проводилось в рамках полной описанной модели и в рамках упрощенной версии. В последнем случае изучалось обучение одного агента.
В случае полной версии модели рассматривалась популяция, состоящая из n =50 агентов, помещенная в мир из 100 клеток (Nx = Ny = 10), в котором в половине клеток была случайно распределена пища. В этом случае агент определял наличие/отсутствие пищи в 4-х клетках поля зрения и наличие/отсутствие другого агента в 3-х клетках поля зрения (впереди, справа, слева), т. е. каждая ситуация S (t) характеризовалась бинарным вектором, имеющим семь компонент. Следовательно, всего было 128 возможных ситуаций и 7 возможных действий; итого, имелось 896 возможных правил. Было продемонстрировано, что в полной модели в процессе эволюции и обучения агентов формировалось естественное их поведение: агенты преимущественно питались и часто отнимали ресурс друг у друга, изредка они выполняли и другие действия.
Пример расчета по полной модели иллюстрируется на рис. 1, 2. Приведем параметры расчета. Порция пищи расположена в 50 клетках, прирост ресурса агента при съедании пищи был равен 1 (считаем ресурс безразмерным). Расход ресурса на каждое из действий, кроме удара, был равен 0.01, расход на удар составлял 0.02, при ударе ударяющий агент отнимал у ударяемого ресурс, равный 0.05. Параметры обучения с подкреплением были следующими: б = 0.1, г = 0.9. Применялся метод отжига: при t = 0 полагалось е = 1, со временем величина е по экспоненте уменьшалась до нуля, характерное время уменьшения е составляло 1000 тактов времени. Интенсивность мутаций была равна 0. Исходный ресурс агента (при t = 0) составлял R = 1. Минимальный ресурса агента Rmin (при R < Rmin агент умирал) был равен 0: Rmin = 0.
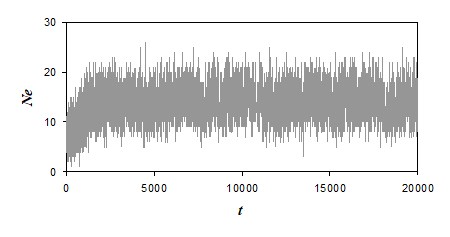
Рис. 2 Зависимость числа агентов Ne, выполняющих действие «питание», от номера такта времени t
На рис. 1 представлена зависимость среднего по популяции ресурса агента от номера такта времени t. Видно, что сначала (t < 2000) скорость роста мала, так как логические правила еще не сформированы, и веса имеющихся правил еще не настроены. При t > 5000 скорость роста практически постоянна; стохастичность на этом участке обусловлена случайным перемещением агентов по клеткам мира, а также случайным размещением новых порций пищи в ячейках мира при съедании части пищи агентами.
Видно, что при больших значениях t примерно 30% агентов (из общего числа агентов популяции, равного 50) выполняет каждый такт это действие. Наблюдаются сильные стохастические колебания числа Ne во времени. Примерно такая же зависимость от времени наблюдается и для числа агентов, выполняющих действие «нанесение удара»; число таких агентов при больших t равно примерно 15−20. При больших t число агентов, выполняющих действие «деление», мало и составляет около 1, а число агентов, выполняющих каждое из остальных действий (движение вперед, повороты направо/налево, отдых), равно примерно 3−5.
Таким образом, в изложенной модели агенты обучились выполнять преимущественно действия «питание» и «нанесение удара», которые приводили к увеличению ресурса агента, и избегать действие «деление», которое приводило к уменьшению ресурса (ресурс делящегося агента уменьшался в 2 раза). Каждое из остальных действий выполнялось с небольшой частотой.
В упрощенных версиях модели анализировалась возможность формирования цепочек действий одним самообучающимся агентом. Рассматривалось два варианта формирования цепочек. В первом варианте агент мог выполнять только 4 действия: питаться, двигаться вперед и поворачиваться направо либо налево. Считалось, что имелась только одна расположенная в определенной клетке порция пищи. Агенту необходимо было сформировать заданную цепочку из одного, двух или трех действий. Например, трехзвенная цепочка включала следующие действия: 1) «поворот направо», 2) «перемещение вперед», 3) «питание»; при этом порция пищи исходно располагалась в клетке справа от той клетки, в которую исходно помещался агент. Основные параметры расчета были такими же, как и для полной модели. Метод отжига в этом варианте не использовался. Величина е, регулирующая случайный выбор действия агентом, была постоянной и составляла е = 0.2. Расчеты показали, что простые одно-, двух-, трехзвенные цепочки действий достаточно легко формировались в процессе самообучения агента.
Во втором варианте упрощенной версии к указанным 4-м действиям добавлялось еще действие «отдых». В этом случае было возможным формирование цепочек действий в мире, в котором, как и в полной модели, в половине клеток была случайно распределена пища. Применялся метод отжига: в начальный момент времени полагалось е = 1, со временем величина е по экспоненте уменьшалась до нуля, характерное время уменьшения составляло 1000 тактов. Как и в первом варианте, основные параметры расчета были такими же, как в полной модели. Расчеты показали, что в этом варианте формировались заранее неизвестные цепочки действий из нескольких звеньев, приводящие к нахождению пищи. Пример зависимости ресурса R агента от времени для данного случая показан на рис. 3.
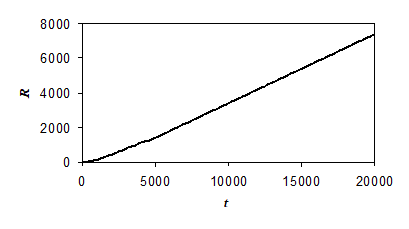
Рис. 3 Зависимость ресурса R самообучающегося агента от номера такта времени t
Результаты моделирования для второго варианта оказались интересными, остановимся на них подробней. Так как агент был один, то каждая ситуация S (t) определялась только наличием/отсутствием пищи в 4-х клетках поля зрения и характеризовалась бинарным вектором, имеющим 4 компоненты. Всего было 16 возможных ситуаций и 5 возможных действий; итого, имелось 80 возможных правил. Интересно, во всех расчетах общее число правил, сформированных каждым агентом, было равно 80, То есть, в начале расчета, когда вероятность случайного выбора действия была высока, агент путем случайного поиска формировал все возможные правила. Однако веса этих правил менялись в процессе обучения, и к концу расчета, как изложено ниже, преимущественно использовались только 16 правил из 80 возможных.
В конце расчета были выделены логические правила, имеющие достаточно большой вес (превышающий 1). Оказалось, что для типичного расчета число таких выделенных правил с большими весами было равно 16, каждое из правил соответствовало одной из возможных ситуаций и выполняемому в этой ситуации действию. Именно эти правила применялись агентом. Этот набор правил можно рассматривать как обобщающие эвристики, формируемые агентом в процессе самообучения. Эти эвристики сводятся к следующему: 1) если порция пищи расположена в той же клетке, в которой находится агент, то нужно выполнить действие «питание» (таких правил было 8); 2) если порции пищи нет в той клетке, в которой находится агент, и есть пища в клетке впереди или справа/слева от агента, то нужно выполнить действие «перемещение вперед» или «поворот направо/налево», соответственно; если вообще не было пищи в поле зрения агента, то агент предпочитал действие «перемещение вперед». Перемещение вперед имело предпочтение перед поворотами, это можно объяснить тем, что при наличии порции пищи впереди, эта порция съедалась после двухзвенной цепочки действий, а при использовании поворотов порция могла съедаться только после трехзвенной цепочки действий. Интересно, что когда агент попадал в ситуацию «буриданова осла», т. е. видел пищу в двух клетках, справа и слева, то в одних расчетах он предпочитал поворачиваться направо, а в других — налево. Отметим, что действие «отдых» игнорировалось во всех ситуациях. В некоторых расчетах было небольшое число и других правил с весами, большими 1, тем не менее, свойства применяемых правил только изредка незначительно отличались от вышеописанных. Представленная на рис. 3 зависимость R (t) соответствовала 16 выделенным правилам с большими весами: для каждой из возможных 16 ситуаций было свое правило, характер этих правил изложен выше. Следовательно, в процессе обучения агент самостоятельно формировал вполне естественные правила, определяющие «разумную» стратегию поведения.