Технология управления разнородными знаниями

Характерной тенденцией, оказывающая сильное влияние на архитектуру современных информационных систем (ИС), является бурное развитие глобальной сети Интернет, где информация содержится, как правило, в плохо структурированном виде. Очевидно, что это отражает особенность человека, который привык выражать свои мысли и делиться своими знаниями в виде текстов. Преобразование этих знаний в форму хорошо… Читать ещё >
Технология управления разнородными знаниями (реферат, курсовая, диплом, контрольная)
Для современных информационных систем характерно постоянное усложнение решаемых задач, стремительный рост хранимых и обрабатываемых данных, а также их разнородность. В связи с этим возникает необходимость сочетать различные модели данных и методы для их анализа.
Потребность в сложных аналитических операций над разнородными данными приводит к тому, что традиционные для направления Data Mining методы агрегирования данных становятся недостаточными и требуется решать задачи извлечения и хранения знаний.
Для сложных проектов, например, атомных станций, актуальна задача управления жизненным циклом (ЖЦ) такого проекта. На разных его этапах применяются различные информационные системы, как правило, содержащие большие объемы данных, справочной информации, знаний в некоторой предметной области. Поэтому перед системой управления ЖЦ (PLM) стоит задача их интеграции. Для этого обычно используют нейтральную модель интеграции стандарта ISO 15 926 или некоторую ее упрощенную модификацию. Решается задача онтологического мэппинга разнородных баз знаний, что было более подробно описано в работе [1].
Характерной тенденцией, оказывающая сильное влияние на архитектуру современных информационных систем (ИС), является бурное развитие глобальной сети Интернет, где информация содержится, как правило, в плохо структурированном виде. Очевидно, что это отражает особенность человека, который привык выражать свои мысли и делиться своими знаниями в виде текстов. Преобразование этих знаний в форму хорошо структурированных данных фактографических баз данных или же перевод их на языки формальных онтологий, например, в соответствии с требованиями пула стандартов Semantic WEB [2], представляется весьма проблематичным и пока реализовано в очень узких областях. Кроме этого существуют большое число документальных систем, в которых информация традиционно представлена в слабоструктурированном виде. С развитием сети Интернет появляется возможность подключаться к ним и получать необходимую информацию.
Отмеченные особенности определяют требования к архитектуре современной ИС, способной эффективно решать задачи управления знаниями: она должна быть способной манипулировать информацией в текстовой форме, причем эти тексты могут иметь различные наборы знаков и объединять в себе различные модели данных и знаний. Созданию такой технологии управления знаниями и проработке архитектуры такого рода гибридной ИС, содержащей элементы искусственного интеллекта, посвящена настоящая работы.
Технология управления разнородными знаниями призвана объединить в единое целое средства решения более частных задач, которые были решены нами ранее.
Она основывается на следующих предпосылках:
- · знания содержатся в электронных документах, имеющих разные форматы и наборы метаданных, включая тексты и таблицы;
- · документы распределены по различным разнородным источникам (открытым — Интернет-ресурсы и ограниченного доступа);
- · имеются эксперты, которые могут определить интересующие источники информации, сформулировать темы, подлежащие мониторингу и определить принципы систематизации знаний.
Предлагаемая технология охватывает все основные этапы жизненного цикла работы со знаниями современных интеллектуальных информационных систем, среди которых можно выделить следующие:
- 1. автоматический сбор информации из разнородных источников, включая публикации в сети Интернет, документальные базы данных, табличные данные, реляционные СУБД;
- 2. очистка данных, исправление ошибок и устранение противоречий;
- 3. извлечение структурированной информации из текстов и формирование баз знаний;
- 4. организация хранения данных и знаний;
- 5. выполнение различных видов анализа над хранилищами данных и знаний, включая аннотирование, кластеризацию, рубрикацию, полнотекстовый и семантический поиск, выявление трендов и прогноз развития ситуаций, географическая привязка информации;
- 6. интеграция разнородных знаний, относящихся к разным предметным областям при помощи операции онтологического мэппинга с использованием нейтральной модели стандарта ISO 15 926;
- 7. организация обмена данными и знаниями между информационными системами различного назначения.
Проработаны все технические вопросы взаимодействия между основными технологическими блоками, созданы программные средства для их администрирования и пользовательские приложения.
Обобщенная структура системы, реализующая предлагаемую технологию управления разнородными знаниями, приведена на рис. 1. На нем представлены только основные структурные элементы и связи, непосредственно связанные с жизненным циклом знаний, а все вспомогательные обслуживающие этот процесс системы и модули опущены.
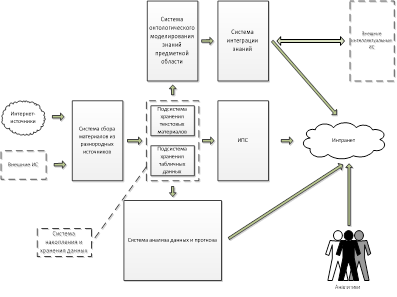
Рис. 1 Обобщенная структура системы управления знаниями
Многие из систем, показанные на рис. 1 весьма сложны по своей структуре и часто используют различные модели и представления данных и знаний, а также большой набор методов их обработки и анализа. Поэтому на таком уровне обобщения возникает гибридная ИС, которая объединяет в себе другие гибридные ИС с элементами искусственного интеллекта (ГИИС).
Рассмотрим более подробно отдельные системы, входящие в состав обобщенной структуры, представленной на рис. 1.
Система накопления и хранения данных выполняет функцию хранения разнородных данных с использованием различных СУБД.
Для хранения текстовых документов используется объектная СУБД ODB-Jupiter [3] и ее приложение, обеспечивающее возможность работы с текстовыми документами — объектная информационно-поисковая система «ODB Text» [4], которая реализует и основные функции ИПС, изображенной на рис. 1.
Информация, извлекаемая из сети Интернет, а также от некоторых специализированных ИС может содержать большое число цифровых данных, представленных в различных форматах, причем эти форматы могут быть разными даже у одного источника информации. В таких случаях выполняется извлечение цифровых данных из исходных форматов и хранение их в реляционных СУБД. Были проработаны различные варианты такого хранения, наиболее востребованным оказался вариант хранения в СУБД Microsoft SQL Server. При этом исходные оригинальные форматы документов также сохраняются, но в объектной СУБД ODB-Jupiter. Это дает возможность иметь доступ к оригиналам документов, а также осуществлять полнотекстовый поиск по названиям строк, столбцов и самих таблиц.
При хранении цифровых данных в реляционной СУБД интерпретация их семантики возлагается на те аналитические системы, которые должны их анализировать. Сами данные имеют только информацию об их положении в исходной таблицы: идентификатор источника информации, идентификатор таблицы, номер строки и столбца. Такой подход весьма типичен для такого направления как NoSQL [5]. Он позволяет упростить реализацию хранилищ данных и достичь всех вытекающих отсюда преимуществ, но переносит основную работу на аналитика, который должен очень хорошо представлять данные с которыми он работает, чтобы написать правильные запросы. Так как в нашем случае подход NoSQL имитируется в реляционной СУБД, то аналитические запросы к числовым данным должны быть записаны на языке SQL. Здесь стоит отметить, что объектная СУБД ODB-Jupiter также имеет язык запросов, конструкции которого напоминают SQL, но с расширенными возможностями для полнотекстового поиска. Поэтому аналитик может писать запросы к хранилищам разнородных данных в едином стиле.
Системы сбора материалов из разнородных источников реализует все отмеченные выше особенности сбора данных, связанные с наличием как текстовых, так и табличных данных, которые должны храниться, а затем и анализироваться различным образом. При обработке входного потока документов из них извлекаются тексты и метаданные, состав которых определяется типом исходного документа.
При сборе данных решаются задачи контроля качества исходной информации. Для этого реализованы две подсистемы: Подсистема обнаружения сбоев и Подсистема удаления дубликатов. Подробное их рассмотрение выходит за рамки данной работы. Необходимо лишь отметить их необходимость и важность в рамках предлагаемой системы управления знаниями. Обе подсистемы используют единый подход для построения векторных моделей документов, основанный на выделении наборов содержательных и структурных признаков документов и последующим анализом их близости по определенным метрикам. Используется методы машинного обучения и, в частности, метод машин опорных векторов (SVM).
В результате работы системы сбора возможно обнаружить сбои в источниках информации, сделать крайне маловероятной загрузку искаженной информации, исключить дублирующие документы, а также, уже на этапе сбора информации определить тематическую и структурную близость документов и использовать эти результаты на этапе ее анализа.
Система анализа данных и прогноза выполняет важнейшие функции работы с накапливаемыми данными. Состав ее основных элементов может сильно варьироваться в зависимости от выбранной предметной области и специфики решаемых задач.
Были проработаны и реализованы основные способы анализа текстовых документов, такие как полнотекстовый поиск, автоматическая кластеризация и рубрикация, квазиреферирование, выделение понятий. Наиболее интересной функцией, которая в настоящее время активно прорабатывается нами, является анализ и прогноз развития событий, процессов или ситуаций на основе текстовой информации. Используя информации о времени публикации текстовых сообщений и распределение определенных терминов в их текстах можно перейти к графической форме представления результатов анализа коллекций документов и использовать методы обработки дискретных сигналов.
Архитектура системы анализа данных и прогноза позволяет подключение нескольких сервисов построение прогноза, реализующие разные методы. Сервис анализа и визуализации данных позволяет собирать результаты прогноза, поступающие от различных сервисов и отображать их в Веб-клиенте пользователя-аналитика.
В настоящее время для решения задачи прогнозирования развития событий по текстовым сообщениям нами активно исследуются и реализуются различные модели прогноза, такие как авторегрессионная, регрессионная, искусственные нейронные сети, модели на основе нечетких временных рядов. Также предусмотрена возможность выполнять прогноз и отображать его результаты средствами внешних аналитических систем. Для оценки достоверности, прогноз строился за определенный период в прошлом, и его результаты сравнивались с реальной информацией. Совершенствование методов прогноза для текстовых коллекций является предметов дальнейших исследований. управление знание информационный интеллектуальный В системе анализа данных и прогноза реализованы различные способы представления результатов. Это — различные аналитические отчеты, структура которых настраивается пользователями, а также графики реального и прогнозируемого развития ситуации. В идеале данная система должна сама выбирать или рекомендовать аналитику оптимальный метод прогноза, т. е. мы должны получить ГИИС с адаптивной гибридизацией. Это является целью наших дальнейших исследований.
Наличие в системе как числовых, так и текстовых данных, относящихся к одному объекту или событию, открывает возможности для их совместного использования для анализа и прогнозирования. Пока анализ текстовой и числовой информации выполняется независимыми аналитическими системами. Предполагается их последующая интеграция в рамках единой ИС на основе сервис-ориентированной архитектуры, что позволит решать задачи анализа разнородной информации. Одной из таких задач, требующих своего решения, является, например, прогнозирование последствий принятия законопроектов [6].
Для решения целого ряда аналитических задач бывает важным учитывать географическую привязку интересующей информации. Для этого предусмотрен сервис гео-привязки, который выполняет извлечение географической информации из текстов, построение распределения документов по географическому принципу и визуализацию результатов извлечения. В качестве простейшей гео-информационной системы, в которой выполняется отображение информации на трехмерной карте, используется программа Google Earth. Наличие в этой программе средства отображать динамические изменения информации дает возможность объединить результаты анализа текстов во времени и по территориальному признаку.
В качестве дальнейшего развития технологии гео-привязки предполагается создание «интеллектуальных» карт, которые будут содержать не только картографическую информацию, но и семантику некоторой предметной области, а также правила логического вывода. В результате появится возможность в среде ГИС задавать вопросы на языке близком к естественному или на некотором диалекте языка SPARQL и получать ответы в виде новых объектов на карте, формируемых в ходе выполнения семантического анализа.
Система онтологического моделирования знаний предметной области включает в свой состав средства автоматического извлечения из текстов нужных характеристик, основанные на методах Data Extraction [7], средства для создания и автоматического пополнения словарей понятий для текстовых коллекций, модули морфологического и синтаксического анализа [8].
Для решения задачи построения онтологических справочников предусмотрен этап создания каталожных описаний и их автоматическое преобразование к виду формальных онтологий консорциума W3C, для редактирования которых используется редактор онтологий Protйgй. Хранение онтологий в виде RDF-триплетов возможно в различных СУБД с использованием системы Jena, доступ к ним осуществляется на языке SPARQL. Решены вопросы повышения скорости выполнения SPARQL-запросов путем их эффективного кэширования.
С помощью специальной программы управления онтологией осуществляется создание и наполнение онтологии, которая хранится на сервере базы данных. Так как в данной системе выполняется онтологическое моделирование знаний, поступающих из различных источников, создается локальная, поименованная область онтологии, связанная с каждым типом источника информации. Программой создаётся схема онтологии (т.е. описание классов и свойств области онтологии) и осуществляется загрузка информационных объектов. В итоге на сервере базы данных формируется заполненная онтология, содержащая несколько поименованных областей (по количеству типов источников данных).
В рамках системы онтологического моделирования знаний также решается задача семантического контроля текстовых документов, которая заключается в обнаружении и исправлении семантических ошибок. Для этого извлекаемая из слабоструктурированных источников данных информация проверяется на соответствие некоторым эталонным знаниям, представленным в виде формальных онтологий. Семантические проверки обычно весьма специфичны и возможны для конкретных предметных областей. В качестве примеров реализации функции семантического контроля можно указать проверку почтовых адресов и стенограмм заседаний.
Система интеграции знаний обеспечивает выполнение операции онтологического мэппинга разнородных баз знаний, представленных в виде формальных онтологий в соответствии с рекомендациями пула стандартов Semantic WEB консорциума W3C. В результате чего появляется возможность получить доступ к данным и знаниям из различных внешних интеллектуальные ИС, изображенных пунктиром на рис. 1, и решать задачи управления ЖЦ сложных проектов, как это предложено в работе [1].
Проведенное выше описание обобщенной системы управления разнородными знаниями и ее основных структурных элементов позволяет сделать вывод о том, что она обладает основными свойствами семиотической системы, основные принципы и теоретические основы которых были проработаны в работах российских ученых Поспелова Д. А., Осипова Г. С., Клыкова Ю. И. и других авторов. Основные информационные единицы, с которыми оперирует, рассмотренная выше система управления разнородными знаниями, обладают такими свойствами как, именованность, структурированность, иерархичность, связность, активность и рефлексивность, поддерживаются различные связи и отношения между этими информационными единицами, имеются механизмы динамического изменения этих информационных единиц и их отношений, а также используются различные модели для их представления и отношения между этими моделями.
Таким образом, для реализации технологии управления разнородными знаниями была создана ГИИС, манипулирующая знаниями семиотического типа. Основным носителями знаний являются текстовые документы, их метаданные и формальные онтологии, построенные на основании этих метаданных, а также извлекаемых из текстов понятия и отношений между ними.
В заключении можно указать некоторые области применения предлагаемой технологии управления разнородными знаниями:
выявление тенденций и перспективных направлений в развитии науки и техники, поиск перспективных инновационных проектов;
выявление перспективных и лучших разработок ВПК страны;
выявление угроз безопасности, прогнозирование развития кризисных ситуаций;
управление ядерными знаниями;
анализ и прогнозирование социально-экономических, политических и экологических процессов и тенденций;
прогнозирование последствий принятия законопроектов;
поддержка принятия решений на уровне предприятий, отраслей и государства в целом.
Очевидно, что в зависимости от конкретной области ее применения состав технологических блоков может меняться, а сами структурные элементы подлежат настройке для выполнения определенных задач.
ф- 1. Березкин Д. В. Построение онтологического справочника отраслевого уровня с учетом рекомендаций стандарта ISO 15 926// Гибридные и синергетические интеллектуальные системы: теория и практика. Сборник научных трудов 1-го Международного симпозиума (г. Светлогорск, 29 июня — 2 июля 2012 г.). В 2-х томах. Т 2. — М.: Физматлит, 2012. — С. 245 — 254.
- 2. W3C. http://www.w3.org/2001/sw/.
- 3. Андреев А. М., Березкин Д. В., Самарев Р. С. Распределенная ОСУБД ODB-Jupiter 4.0 // Современные информационные технологии: Юбилейный сборник трудов кафедры, 20 ноября 2001 г. — М.: Изд. МГТУ им. Н. Э. Баумана. — 2002. — С.155 — 158.
- 4. Страница, посвященная ИПС ODB Text. http://www.inteltec.ru/odbtext/odbtext.shtml.
- 5. Cattell R. Scalable SQL and NoSQL Data Stores. http://cattell.net/datastores/Datastores.pdf
- 6. Аналитическая обработка текстовой информации в задачах мониторинга последствий принятия законов и автоматизации лингвистической экспертизы законопроектов / А. М. Андреев, Д. В. Березкин, К. В. Симаков и др. // Аналитический вестник Аналитического управления Аппарата Совета Федерации, № 27 (439), 2011 г. — С. 46 — 64.
- 7. Андреев А. М., Березкин Д. В., Симаков К. В. Модель извлечения знаний из естественно-языковых текстов.// Информационные технологии. — 2007. — № 12, С. 57 -62.
- 8. Использование статистических методов для создания лингвистического обеспечения информационно-поисковой системы / А. М. Андреев, Д. В. Березкин, А. В. Брик, Ю. М. Смирнов // Вестник МГТУ. Сер. Приборостроение. — 2001. — № 2. — С.13 — 24.