Средства автоматизации алгоритма прямой классификации

Этап 1. Генерация выборки. Для изучения влияния характера исходных данных на результат классификации используется генерация псевдослучайных величин средствами EXCEL. Нажать кнопку ОК. Если указанный на рабочем листе диапазон содержит другие данные, появится окно сообщения, где необходимо будет подтвердить замену данных. Вторая половина выборки сгенерирована случайным образом из нормального… Читать ещё >
Средства автоматизации алгоритма прямой классификации (реферат, курсовая, диплом, контрольная)
Разработанные средства автоматизации алгоритма прямой классификации предназначены для использования в процессе изучения студентами азов теории классификации. Они ориентированы на выработку у студентов интуиции о влиянии характера исходных данных, а также способов измерения близости между объектами и типе нормировки на результат классификации.
Диалог с пользователем осуществляется при помощи пользовательской формы. При нажатии на соответствующие кнопки формы, происходит выполнение необходимых вычислений. Действия, которые производят разработанные макросы для кнопок, разбиты на 5 этапов.
Этап 1. Генерация выборки. Для изучения влияния характера исходных данных на результат классификации используется генерация псевдослучайных величин средствами EXCEL.
С помощью генератора случайных чисел можно построить последовательности с нормальным распределением. Очень многие модели, построенные с помощью этого распределения, хорошо соответствуют действительности. Чтобы построить последовательность значений нормально распределенной случайной величины, необходимо задать математическое ожидание и дисперсию.
Чтобы сгенерировать последовательность, необходимо воспользоваться функцией из встроенного пакета анализа данных:
Выбрать команду Сервис, Анализ данных (Tools, DataAnalysis). Появляется диалоговое окно Анализ данных Выбрать пункт Генерация случайных чисел (Random Number Generation).
Появляется диалоговое окно Генерация случайных чисел.
Выбрать Нормальное распределение в списке Распредеение (Distribution).
Ввести число 3 в поле Число переменных (Number of Variables), что означает число столбцов, которые заполнены последовательностью.
Ввести число 20 в поле Число случайных чисел (Number Random Numbers), т. е. последовательность занимает 20 строк.
Нажать кнопку ОК. Если указанный на рабочем листе диапазон содержит другие данные, появится окно сообщения, где необходимо будет подтвердить замену данных.
EXCEL создаст последовательность.
Первая половина выборки в разработанном макросе сгенерирована случайным образом из нормального распределения с параметрами математическое ожидание 0 и дисперсия 1 (м = 0, у = 1).
Вторая половина выборки сгенерирована случайным образом из нормального распределения с параметрами математическое ожидание 2 и дисперсия 1 (м = 2, у = 1).
Замечание. Для изменения исходных параметров в теле макроса делаются корректировки. Например, для математического ожидания со значением 0 дисперсии со значением 1 данный фрагмент реализации в макросе выглядит следующим образом:
For i = 1 To m Randomize.
Cells (i + 1, 1) = RndN (0, 1) Next i.
For i = 1 To m Randomize.
Cells (i + 1, 2) = RndN (0, 1) Next i.
For i = 1 To m Randomize.
Cells (i + 1, 3) = RndN (0, 1) Next i.
Этап 2. Рабочие расчеты. Для классификации необходимо провести дополнительные рабочие расчеты, как-то: вычисление максимальных и средних элементов выборки, нормировка выборки.
Первоначально каждый объект заданной совокупности описан тремя признаками по двадцать элементов каждый.
Для каждых членов исходных рядов в ячейки D4, E4, F4 заносятся значения, соответствующие средним значениям.
Для каждых членов исходных рядов в ячейки D7, E7, F7 заносятся значения, соответствующие максимальным значениям.
В процессе исследования в качестве нормировок были выбраны две.
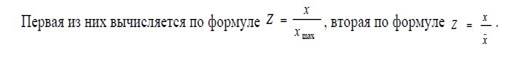
Этап 3 Расчет матриц расстояний. В качестве определения расстояния между объектами выбраны линейное и евклидово расстояния.
Этап 4 Выделение 2 классов, вывод промежуточных результатов. На этом этапе производится выделение двух классов для построенных на первом этапе исходных данных. Начальное разбиение выборки задается двумя способами. Первый способ заключается в том, что первая половина элементов выборки принимается за первый класс, а вторая — за второй. Второй способ разбиения заключается в том, что в первый класс будут входить нечетные элементы выборки, а во второй — четные. На рабочем листе при помощи макроса реализованы следующие действия: отображено первоначальное разбиение выборки на 2 класса, промежуточные результаты по работе макроса, будет отображение конечного результата разбиения выборки на два класса. По полученным разбиениям построены графики, наглядно изображающие два класса.
Этап 5 Очищение ячеек. Начальные данные, вводимые для исследования, всегда различны. Поэтому на пользовательской форме предусмотрена кнопка, выполняющая полную очистку ячеек с ранее полученными результатами.