Результаты экспериментальных исследований и испытаний

Основным средством организации параллельных вычислений в многопроцессорных системах с общей памятью являются потоки (threads). Основными методами работы с потоками являются: создание, удаление, приостановка, запуск на выполнение. Если оформить процедуру оценки особи в виде потокового класса, то приведённый выше фрагмент будет выглядеть следующим образом. Процесс автоматизации в подавляющем… Читать ещё >
Результаты экспериментальных исследований и испытаний (реферат, курсовая, диплом, контрольная)
Процесс автоматизации в подавляющем большинстве случаев нацелен на контроль действий оператора и минимизацию ошибок. Мощные многопроцессорные вычислители позволяют ставить вопрос об автоматическом решении задачи, но для этого необходимо решить алгоритмические проблемы, связанные с распределением вычислений между узлами системы.
Параллельные вычисления в решении задач составления расписания
Основным средством организации параллельных вычислений в многопроцессорных системах с общей памятью являются потоки (threads). Основными методами работы с потоками являются: создание, удаление, приостановка, запуск на выполнение. Если оформить процедуру оценки особи в виде потокового класса, то приведённый выше фрагмент будет выглядеть следующим образом.
ОценитьПопуляцию (Популяция, ЧислоОсобей).
{.
for (i=0; i<�ЧислоОсобей; i++).
{.
ОценитьОсобь->СоздатьПоток (Популяция[i], Последовательность);
ОценитьОсобь->Выполнить ();
ОценитьОсобь->ЖдатьЗавершения ();
ОценитьОсобь->УдалитьПоток ();
}.
}.
Организация такого процесса будет состоять в том, чтобы создать одновременно несколько экземпляров потокового класса «ОценитьОсобь», запустить их на выполнение, передав индивидуальные входные параметры, и далее ожидать окончания выполнения для каждого экземпляра класса. Число особей в реализации параллельного генетического алгоритма по такой схеме обычно гораздо больше числа вычислительных процессоров в системе (4−6 в текущих маркетинговых процессорах Intel, до 64 в специализированных системах). Поскольку мы предполагаем, что один вычислительный поток будет загружать один процессор (одно ядро) в системе, то необходимо одновременно выполнять такое число потоков, которое равно числу процессоров. Таким образом, в коде выше появится дополнительный вложенный цикл. Псевдокод параллельной реализации в терминах потоков приведён ниже.
ОценитьПопуляцию (Популяция, ЧислоОсобей).
{.
for (int i=0; i<�ЧислоОсобей/ЧислоПотоков; i++).
{.
j=i*ЧислоПотоков;
выполнять_параллельно_для j, j+1, …, j+ЧислоПотоков-1.
{.
ОценитьОсобь->СоздатьПоток (Популяция[j], Последовательность);
ОценитьОсобь->Выполнить ();
}.
ЖдатьОкончанияПотоков j, j+1, …, j+ЧислоПотоков-1;
УдалитьПотоки ();
}.
}.
Здесь переменная «ЧислоПотоков» показывает, сколько вычислительных потоков будет выполняться одновременно. Обычно для многоядерных систем рекомендуется выбирать число потоков равное числу вычислительных ядер системы.
Как было отмечено ранее, процесс составления расписания последователен. На каждом новом шаге решения задачи необходимо знать результаты всех предыдущих шагов, т. е. знать, какие ресурсы уже заблокированы. В противном случае для выполнения условия не конфликтности, на каждом шаге необходимо будет проверять, совместимость решений, принимаемых в этот же момент времени другими узлами. Если обнаружен конфликт, то расчеты оказались напрасны, и на их проведение и на рассылку данных было затрачено лишнее время. К тому же от результатов каждой итерации будет зависеть значение штрафной функции для следующей итерации. Таким образом, на каждом шаге выполнения программы, возможна установка только одного занятия. Если после какого-то шага это невозможно, то оставшиеся занятия переводятся в ранг не расставленных, и вычисления заканчиваются.
Так как, заранее неизвестно, на каком узле окажутся наиболее критичные занятия, может возникнуть ситуация, при которой часть узлов уже расставит все свои занятия и будет простаивать. Чтобы сбалансировать нагрузку узлов, необходимо повторять процесс распределения занятий между ними через некоторое число итераций.
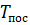
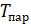
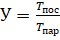
Испытания распределенного приложения на основе описанного алгоритма были проведены на двухъядерном процессоре с частотой 1,9 ГГц и 4 Гб оперативной памяти. Распараллеливание велось по количеству особей популяции. Время выполнения последовательного алгоритма —. Время выполнения параллельного алгоритма —. Ускорение — определялось по формуле:. Выигрыш —, [1]. Результаты вычислительных экспериментов по исследованию параллельного алгоритма представлены в таблице 1.
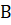
Параллельная программа написана на языке С++ с использованием библиотеки MPI. В ней широко используются коллективные операции обмена, которые позволяют отправить сообщение сразу всем узлам, и при этом даже выполнить некоторую обработку предаваемых данных Основная цель проводимых исследований заключается в том, чтобы проанализировать возможность эффективного использования параллельных вычислительных систем с распределенной памятью для решения оптимизационной задачи минимизации.
Некоторые результаты исследований приведены на рисунках ниже:
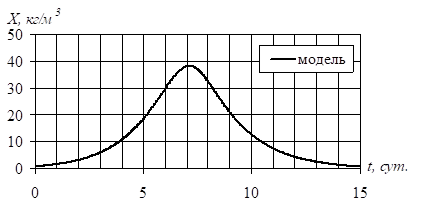
Рисунок 3.1 — Динамика концентрации бактерий.
Рисунок 3.2 — Динамика концентрации питательных веществ в субстрате.
Из графиков видно, в зависимости от количества ядер компьютера масштабируемость алгоритма изменяется с увеличением ядер. Ускорение алгоритма практически не изменяется, теоретически существует тенденция к увеличению ускорения с увеличением количества ядер.
Результаты показывают, что время вычислений обратно пропорционально числу вычислительных ядер. Это позволяет сделать вывод о приемлемой масштабируемости алгоритма. При запуске последовательного приложения на 4-ех ядерной машине загруженность процессора составляла величину порядка 12%.
Алгоритм неэффективно работает при небольших размерностях задачи. Однако для больших размерностей получается значительный выигрыш.