Кластеризация.
Кластеризация языковых выражений в корпусе текстов на основе стохастического ранжирования

Мы воспользовались порталом Ruposters, на котором разработчиками сайта уже произведена разметка: каждый документ, относящийся к серьезным и несерьезным новостям, размечен соответственно либо как news, либо как life. Эту классификацию будем считать эталонной и проверим, какие методы кластеризации при каких параметрах показывают лучшие результаты. Тем самым, при работе с другими порталами можно… Читать ещё >
Кластеризация. Кластеризация языковых выражений в корпусе текстов на основе стохастического ранжирования (реферат, курсовая, диплом, контрольная)
Основная цель данного эксперимента.
Мы воспользовались порталом Ruposters, на котором разработчиками сайта уже произведена разметка: каждый документ, относящийся к серьезным и несерьезным новостям, размечен соответственно либо как news, либо как life. Эту классификацию будем считать эталонной и проверим, какие методы кластеризации при каких параметрах показывают лучшие результаты. Тем самым, при работе с другими порталами можно использовать оптимизированный алгоритм.
Итак, задача этого раздела отделить серьезные новости от несерьезных, приблизив параметры алгоритма к эталонным.
Корпус Представим ниже типичные заголовки обоих классов.
Раздел life
- · Пользователи Сети нашли серьезное нарушение Джамалой правил «Евровидения» ;
- · Звезда реалити-шоу «Дом-2» попала в психиатрическую больницу;
- · Звезда «Дома-2» Ольга Бузова полностью обнажилась, шокировав своих поклонников;
- · В Москве установят павильоны «Куку-вата» ;
- · 10 самых откровенных нарядов Каннского кинофестиваля.
Раздел news
- · Красноярские чиновники «погуляли» в командировках почти на 6 млн бюджетных рублей;
- · Кудрин заявил о «последнем рубеже», которого достигла российская экономика;
- · Глава Азербайджана объявил о ядерной угрозе со стороны Армении;
- · Эрдоган захотел реформировать Совбез ООН;
- · «Газпром» продал свои 37% в эстонской AS Eesti Gaas.
Входные данные В первую очередь, с помощью модуля Pymorphy2 производится предобработка корпуса, которая заключается в следующем:
- 1) Графематическая обработка, разделение слов и знаков препинания;
- 2) Приведение каждого слова к нормальному виду;
- 3) Выставление частеречных меток, отделенных от слова знаком `_';
Тем самым, каждый документ представлен в следующем виде:
речь_NOUN идти_INFN о_PREP хмель_NOUN ,_PNCT который_ADJF придавать_INFN алкогольный_ADJF напиток_NOUN характерный_ADJF горьковатый_ADJF вкус_NOUN._PNCT он_NPRO оказывать_INFN благотворный_ADJF воздействие_NOUN на_PREP организм_NOUN ,_PNCT благодаря_PREP свой_ADJF способность_NOUN останавливать_INFN рост_NOUN бактерия_NOUN и_CONJ развитие_NOUN болезнь_NOUN ._PNCT.
Векторизация документов Для кластеризации каждый документ представляется в векторном виде. При этом используется модель «мешка слов», то есть не учитывается порядок появления слов в документе. На данном этапе такое допущение вполне корректно — порядок слов будет учитываться при выделении конструкций.
Вектор документа имеет размерность, равную количеству уникальных слов в корпусе. Таким образом, каждому слову для данного документа соответствует некоторое число. Это стандартная в таких задачах модель представления в виде матрицы «слова на документы».
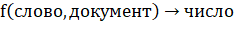
Функцию определим двумя способами:
1) — частота слова в документе ;
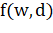
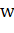
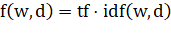
2) — метрика TF-IDF.
Метод кластеризации Мы выбрали наиболее эффективные методы кластеризации, позволяющие задать фиксированное число кластеров.
- · Метод k средних;
- · Спектральный метод
- · Иерархические методы
Метрики оценки качества Качество кластеризации оценивается стандартными критериями, описанными в первой главе:
- · Несмещенный индекс Ранда
- · Несмещенная взаимная информация
- · Точность
- · Полнота
- · V-мера
- · Коэффициент силуэта
Выходные данные Модуль строит 4 текстовых документа:
- · Объединенные в один файл документы, попавшие в первый кластер;
- · Объединенные в один файл документы, попавшие во второй кластер;
- · Файл с ошибочными документами первого класса, попавшие во второй кластер;
- · Файл с ошибочными документами второго класса, попавшие в первый кластер.
Первые два файла необходимы для дальнейшей работы программы, тогда как другие два вспомогательные и позволяют проанализировать ошибки алгоритма.
Результат кластеризации Результат помещен в двух таблицах — в первой даны значения метрик для частотной матрицы «слова на документы», а во второй — TF-IDF матрицы.
Рисунок 1. Меню первого файла программы: опции позволяют настроить кластеризацию.
Таблица 1. Результаты кластеризации с использованием частотной матрицы «слова на документы».
Rand. | MI. | h. | c. | v. | s. | ||
k-mean. | 0.838. | 0.757. | 0.757. | 0.779. | 0.768. | 0.013. | |
Spectral. | 0.787. | 0.69. | 0.69. | 0.713. | 0.702. | 0.013. | |
Agglomerative. | 0.698. | 0.58. | 0.58. | 0.596. | 0.588. | 0.01. | |
Таблица 2. Результаты кластеризации с использованием метрики TF-IDF в матрице «слова на документы».
Rand. | MI. | h. | c. | v. | S. | ||
k-mean. | 0.972. | 0.938. | 0.938. | 0.939. | 0.939. | 0.009. | |
Spectral. | 0.754. | 0.681. | 0.681. | 0.72. | 0.7. | 0.008. | |
Agglomerative. | 0.746. | 0.643. | 0.635. | 0.651. | 0.643. | 0.008. | |
Эксперимент показал, что использование метрики TF-IDF существенно повышает качество кластеризации, особенно в случае метода k средних, который чувствителен к шуму. TF-IDF существенно снижает шум — слова, равномерно распределенные по документам и имеющие высокую частоту (например, предлоги), в этом случае существенно на кластеризацию не влияют.
Высокий результат метода k средних косвенно подтверждает главный тезис: лексика серьезного и несерьезного классов существенно отличается.
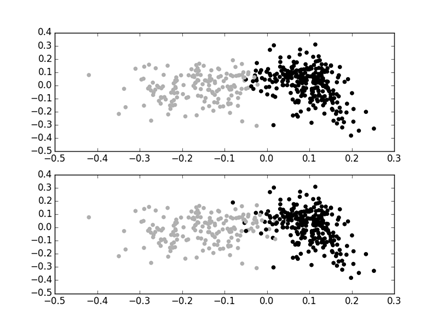
Рисунок 2. Распределение документов при частотной векторизации. Вверху кластеризация, внизу эталонная классификация. Черным цветом обозначены документы, помеченные как серьезные, серым цветом — как несерьезные.
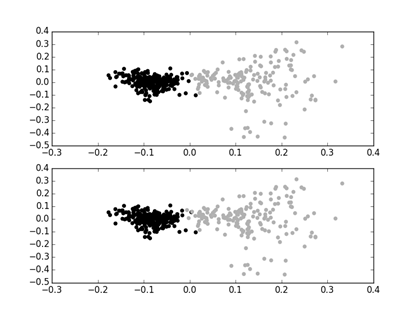
Рисунок 3. Распределение документов при TF-IDF векторизации. Вверху кластеризация, внизу эталонная классификация. Черным цветом обозначены документы, помеченные как серьезные, серым цветом — как несерьезные.
Заметно, что кластеры выпуклые и, при использовании TF-IDF, хорошо разделены. Это и объясняет полученный результат.
Анализ ошибок Ряд документов из пограничной области был неверно размечен методом k средних. Анализ их лексики показал, что в действительности эти документы можно отнести как к первой, так и ко второй группе. Продемонстрируем один из таких документов:
Иракские ополченцы, сражающиеся против террористов «Исламского государства», предложили своим подписчикам в Instagram самим решить судьбу пойманного ими боевика при помощи онлайн-голосования.
" Юг Мосула. Вы можете проголосовать: убить его или отпустить. На голосование отводится один час. Мы сообщим о его судьбе через час" , — написали авторы аккаунта @iraqiswat в Instagram, опубликовав фотографию пленного террориста.