Обзор форматов представления семантической сети

RDF тоже поддерживает семантику, но он базируется на формальной семантике, которая описывается средствами абстрактного синтаксиса, который задается модельное представление, а также способ логической интерпретации, а не конкретный вид конструкций и элементов отображаемого языка. Данный формат описывает логические утверждения в виде триплетов, которые образуют в итоге ориентированный граф… Читать ещё >
Обзор форматов представления семантической сети (реферат, курсовая, диплом, контрольная)
Первоначально необходимо определиться с форматом представления связей семантической сети, для этого вначале рассмотрим по отдельности форматы XML, RDF, JSON и ОА-подход. После этого произведем сравнение по критериям и выберем лучший формат.
XML.
XML — это язык разметки документов, производный от SGML, расшифровывается как Extensible Markup Language. Он позволяет структурировать информацию разных типов, при этом он использует инструкции произвольного набора [18].
XML создан для записи структурированных данных, это могут быть объекты типа адресных строк, электронных таблиц, технических чертежей и т. п. Обеспечивая однозначность структуры, он облегчает задачу создания данных и их чтения. Также XML помогает избежать распространенные ошибки при проектировании языков. Он независим от платформы, расширяем, включает поддержку локализации и интернационализации. Также он полностью совместим со стандартом кодирования Unicode. XML был создан только для структурирования, передачи и хранения информации, больше он ничего не делает.
Теперь рассмотрим физические и логические структуры данных.
С точки зрения физической структуры состав документа это сущности (обязательно что-то в себе содержат и у них всегда есть имя), где каждая сущность может отсылаться на другую сущность. Также есть документная сущность — это единственный корневой элемент. Сущности состоят из символов, которые разделены на два типа, на символьные данные и на разметки. В разметку входят теги, которые обозначают границы элементов, ссылки на сущности, объявления, инструкции обработки, и их атрибуты и комментарии. Часть документа, которая не принадлежит к разметке, составляет символьные данные.
С точки зрения логической структуры, документ состоит из объявлений, комментариев, элементов, ссылок на сущности, а также инструкций обработки. В документе все структурируется разметкой.
В корневой элемент и пролог обобщаются все составляющие части документа, где корневой элемент является обязательной частью документа, а пролог в некоторых случаях может отсутствовать. Элементы, вложенные в корневой элемент, могут включать элементы, вложенные в них, а также комментарии и символьные данные и т. д. В состав пролога может входить объявления, комментарии и инструкции обработки.
Главное, чтобы элементы документы были верно вложены, т. е. если элемент начался внутри другого элемента, то он должен там же и закончиться, иначе будет ошибка. Символьные данные также могут встречаться в секциях «CDATA» .
Главное преимущество XML в том, что в данном языке нет предопределенных тегов, программист сам определяет свои теги и структуру документа, нежеле в HTML, где можно использовать только те теги, которые определены в стандартах (например,.
и т. д.). В XML можно выделять фрагменты внутри документа, а не только разделять его на абзацы и заголовки. Для эффективности можно определять перечень всех своих элементов в описании типа документа или в схеме и придерживаться его.
В XML вначале обязательно вводить объявление, в котором должны указываться версия и кодировка (стандартом является Unicode), например: .
Имена в документе в обязательном порядке могут начинаться только с буквы, либо нижнего подчеркивания, либо двоеточия, продолжение имени могут содержаться буквы (входящие в Unicode), арабские цифры, знаки препинания (дефис, подчеркивание, двоеточие и точки). Все имена, начинающиеся с этих символов, зарезервированы консорциумом W3C для их использования, также регистр имен может быть любой. И так как нет никаких ограничений по ASCII, то в именах можно писать слова родного языка.
= RDF.
Resource Description Framework (RDF) — это язык для описания ресурсов, знаний, который был разработан консорциумом W3C [19].
В RDF можно выделить три правила:
- 1. Факты, похожие на простое предложение в естественном языке, выражаются в виде тройки: подлежащее, сказуемое и дополнение.
- 2. Данная тройка — это имена конкретных или абстрактных сущностей реального времени. Имя может быть глобальным и локальным. Если имя глобальное, то оно ссылается во всех RDF документах на одну и ту же сущность, где оно используется. Во втором случае, на сущность нельзя ссылается из-за пределов документа, только на ту сущность, на которую может ссылаться это имя.
- 3. Литералы — это дополнения, которые текстовые строки.
RDF содержит тройки данных: объект-предикат-субъект, которые называется триплетом (рис. 1.). Например, утверждение «вода прозрачного цвета» будет иметь следующий вид: субъект — вода, предикат — имеет цвет, объект — прозрачный. RDF использует URI для описания субъектов, объектов и отношений.
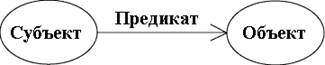
Рис. 1. " Триплет RDF"
Ориентированный граф, где вершины — это субъекты и объекты, а ребра показывают отношения, образует множество RDF утверждений.
RDF является абстрактной моделью данных, он описывает способы обработки, предполагаемую структуру и интерпретации данных, а не формат файла. Существует ряд форматов записи для передачи и хранения информации, которая уложена в модель RDF.
Для наглядности ниже приведен простой пример кода на языке RDF, где говорится, что у Марии есть мать, которую зовут Екатерина, отец Александр и у Александра есть сестра по имени Линда:
@prefix: .
:john a: Maria .
:john :hasMother :Ekaterina.
:john :hasFather :Alexander.
:Alexander :hasSister :Linda.
Благодаря @prefix мы используем глобальное имена сущностей, в данном случае это: john, hasMother, hasFather, hasSister. Данные имена имеют один и тот же смысл во всех документах со значением @prefix.
RDF не затрагивает семантики описываемого, он предоставляет средства, чтобы построить информационную модель. Граф, взятый в отдельности, можно воспринимать в RDF только как граф. Формат способен разъяснять отдельные URI, структуру графа и строковые литералы, и только по ним потом интерпретировать семантику данных и остальные URI.
Для семантики используются словари (собрание терминов, которые имеются во всех во всех словарях с одинаковым смыслом), таксономии (словарь терминов, которые организованы иерархическим способом) и онтологии (используется зарезервированный словарь, где термины определяют концепции и отношения между ними для определенной предметной области), а также наличие связей между ними в рассматриваемом графе [20]. Для обозначения семантики, их взаимоотношений, а также контекстов использования можно применять онтологии.
JSON.
JSON (JavaScript Object Notation) — это простой формат для обмена данными, он удобен для чтения, а также для написания и человеку, и компьютеру. JSON основан от языка программирования JavaScript, это текстовый формат, который использует соглашения Си подобных языков программирования, например Си, Си#, Си++, Python, JavaScript и т. п. [ 21].
JSON может использовать две универсальные структуры (в закодированном виде), они легли в основу языка, потому что JSON используется для обмена данными между разными языками программирования:
ѕ Коллекция пар ключ-значение, данная концепция реализована с помощью объекта, структуры, записи, кэш-таблицы, словаря, ассоциативного массива или именованного списка. В роли ключа может быть строка (регистр букв важен), значением может быть любая форма.
ѕ Упорядоченный набор значений, реализовано с помощью массива, вектора, списка иди последовательности.
В JSON в качестве значений могут быть использованы следующие определения:
ѕ Объект — неупорядоченное множество пар ключ-значение, которое заключено в фигурные скобки и пары разделяются между собой запятыми. Ключ можно описать строкой, между строкой и значением ставится символ двоеточие.
ѕ Одномерные массив — упорядоченное множество значений, который заключен в квадратные скобки, а значения разделяются с помощью запятых.
ѕ Литералы могут принимать три значения: true, false или null.
ѕ Число, используется только десятичный формат данных.
ѕ Строка — упорядоченное множество из символов Unicode, заключается в двойные кавычки. Она похожа на тот одноименный тип данных, который используется в C и Java.
Ниже приведен наглядный пример, описывающий данные человека, имя, фамилия, адрес проживания и номер телефона, в данном примере значение представляет из себя вложенную структуру [22]:
{.
" firstName": «Евгения» ,.
" lastName": «Сидорова» ,.
" address": {.
" city": «Москва» ,.
" streetAddress": «Лубянский проезд, дом 1» ,.
},.
" phoneNumbers": [.
" 8 915 123 45 67″ ,.
" 8 495 987 65 43″ .
].
}.
JSON имеет множество разных расширений и на его основе были созданы новые языки, о главных будет описано ниже:
ѕ JSON5 — разрешение, поддерживаемое синтаксис ECMAScript 5. Формат JSON5 поддерживает однострочные и многострочные комментарии (// и /*…*/), для удобного копирования, списки и объекты могут иметь запятую только после последнего элемента, если ключи объекта являются валидными идентификаторами синтаксиса ECMAScript 5, то они могут писаться без кавычек, заключаться строки могут и в одинарные кавычки, и в двойные. Числа могут включать в себя Infinity, -Infinity, NaN иNaN, также они могут быть в шестнадцатеричном виде и начинаться со знака плюс (+). Некоторые языки программирования имеют парсеры JSON5.
ѕ JSON Schema — это язык описания структуры JSON документа, который использует синтаксис JSON. Данный язык базируется на следующих концепциях: XML Schema, Kwalify, RelaxNG. Это самоописательный язык, если его использовать для описания и обработки данных, то могут использоваться одинаковые инструменты сериализации и десериализации.
ѕ JSON-LD разработал W3C, он используется для передачи связанных данных, при помощи формата JSON. При использовании JSON-LD, облегчается структурирование данных и распознавание понятий. Данные, которые размечены с помощью данного формата, легко распознаются поисковыми системами. Он структурирует информации, при этом не вмешиваясь в контент, который отображается пользователям. Разметка представлена в виде мета-данных, которые упакованы в контейнере в тег. Формат JSON-LD поддерживает семантику.
ОА-подход Объектно-атрибутный подход был разработан авторами [1].
В основе подхода реализуется принцип управления вычислительным процессом с помощью потока данных (dataflow). Для объектного программирования и создания интеллектуальных систем, он обладает большими возможностями, нежели общепринятое в настоящее время объектно-ориентированное программирование (ООП).
В объектно-атрибутный (ОА) подход, авторами [1] были выделены следующие понятия:
" Информационная пара (ИП) (атрибутированные данные) — совокупность нагрузки (данных или ссылки на данные), и ярлыка/атрибута (уникального идентификатора), описывающего нагрузку.
Функциональное устройство (ФУ) — это виртуальное (реализованное программным способом) или реальное устройство, осуществляющее обработку данных. ФУ имеет внутренние регистры (набор регистров будем называть контекстом ФУ) и может исполнять некий набор милликоманд, описываемый алгоритмом функционирования этого устройства.
Милликоманда (мК) — это ИП, где ярлык указывает устройству (ФУ), каким образом следует обрабатывать прикрепленные к нему данные.
Капсула — это множество информационных пар, служащих для описания определенного объекта (с помощью капсулы и обеспечивается абстракция данных). Каждая ИП, входящая в капсулу, задаёт один из критериев описываемого объекта" .
В качестве нагрузки в ИП может выступать как константа, так и ссылка на переменную, на капсулу или другие информационную структуру. Благодаря этому появляется случай синтезировать смысловой граф, который состоит из множества капсул, которые связаны ссылками. Смысловой граф, в свою очередь, служит для описания объекта любой сложности. Это можно сравнить с объектно-ориентированном программировании (ООП).
Капсула может содержать в себе не только данные, но и программу, состоящую из последовательности милликоманд и помещенных в капсулу. Главным преимуществом данного подхода является гибкость, то есть благодаря капсулам и ссылкам в качестве нагрузок информационных пар, можно собирать любой информационный механизм в реальном времени.
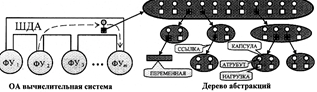
Рис. 2. " Работа вычислительной системы с ОА-деревом абстракций"
На рис. 2. указано ОА-дерево абстракций, также его называют смысловой граф, он немного напоминает структуру класса в объектно-ориентированном программировании (ООП), но здесь есть одно весьма значительное отличие. В основе ООП лежит фреймовая концепция, ОА-подходе — информационные структуры. В первом случае, в фреймовой модели появилась возможность добавлять ссылки на процедуры и функции, а не только на другие фреймы. Совокупность фреймов, которые связаны друг с другом ссылками, дает возможность описать любые абстрактные или реальные объекты, но данной модели не хватает гибкости, она не сможет изменить свою 75 структуру во время вычислительного процесса. В основном, фреймовая структура создается до начала выполнения программы и в дальнейшем не меняется. Во втором случае, как уже говорилось, используются информационные структуры, которые описывают объекты. Главное преимущество данного подхода в том, что они синтезируются во время работы вычислительной системы по заранее заложенным правилам: путем группировки информационных пар в капсулы, а также настройки ссылок между ними, формируются информационные структуры (на рис. 2. показан синтез дерева абстракций).
ФУ занимается синтезом ОА-Графа и анализом, далее через шину данных-атрибута (далее будет использоваться сокращение ШДА), осуществляется обмен информацией между ФУ, после по ШДА передается милликоманда с константой или ссылкой на информационную конструкцию (нагрузку). ФУ идентифицирует данные по атрибуту милликоманды, которые пришли по ШДА, и в зависимости от атрибута, она принимает решение, как следует их обработать. Для хранения промежуточных данных используется набор внутренних регистров.
Преимуществом данной архитектуры является удобный способ абстракции данных, а также легкий программный код, который используется как для описания, так и для распознания объектов. Гибкость вычислительного процесса, о котором говорилось ранее, позволяет ОА-системе наделить себя полноценным интеллектом, она сможет описывать и распознавать неизвестные для себя объекты и самостоятельно изменить системные правила синтеза информационных конструкций. В ОА-архитектуре синтез информационных конструкций осуществляется от легкого к сложному, то есть ОА-система разделяется на несколько уровней абстракции. Процесс начинается с элементарных абстракций (неразложимых), также их называют информационными атомами. Например, для систем, которые распознают изображения, в качестве атомов будет использоваться описание отдельных пикселей изображения, а для автоматизации в роли атомов будут использоваться сигналы. При смысловом анализе текста лексический анализ (формирование слов из символов), происходит на первом уровне абстракции.
Для передачи на высокий уровень абстракций формированием информационных конструкций занимаются те ФУ, которые воплощают алгоритм первого уровня абстракций. После, выделенные слова, которые были оформлены в виде ОА-графа или информационной капсулы, передаются на следующий уровень абстракции, там совершается синтаксический анализ. Те информационные конструкции, которые были сформированы на данном уровне, передаются на следующий уровень, более высокий для смыслового анализа и так далее. Каждый последующий уровень абстракции становится все сложней и сложней предыдущего и их количество постоянно уменьшается, таким образом сложная абстракция представляет из себя достаточно большим смысловым графом. На последнем уровне абстракций находится заключительная, ключевая абстракция, которая полностью описывает распознаваемый объект. В случае, если необходимо произвести синтез наиболее простых абстракций, то будет применяться обратный способ, то есть синтез будет идти от сложного к простому.
Разработанная авторами [2] архитектура, полностью поддерживает принцип изоморфизма, так как любую процедуру можно реализовать с помощью ФУ. Модификация ФУ состоит из расширения набора милликоманд и изменения в количестве операндов и последовательности их передачи для ФУ влиять критически на ОА-программу не будет.
Минусом классических процедур и функций является то, что параметры передаются одновременно, и в случае, если интерфейс процедур и функций будет изменяться, то программисту придется изменять всю программу целиком. Но в данной архитектуре ФУ можно очень легко заменить с помощью интерпретатора, который в свою очередь представляет из себя заглушку, способную переводить старые типы последовательности милликоманд в одну или несколько других, новых ФУ. Изоморфизм обеспечивается даже на уровне структур данных, то есть модификация ОА-графа состоит в добавлении новых ИП в информационные капсулы, благодаря этому алгоритмы поиска по графу не влияют на другие ФУ. Изоморфизм облегчает работу программиста, а также является одним из составляющих интеллектуальных систем, потому что в процессе понимания объектов программа существенно изменяет базу знаний и модификацию, которые не нарушают целостность вычислительных систем.
Для описания преобразования ОА-графа, которые применяются для вывода новых ПВ-отношений применяется нотация ОА-грамматики [23].
Основные обозначения нотации в АО-грамматике:
ѕ «>» или «>-» — замена одного фрагмента ОА-графа на другой, слева ОА-граф, который необходимо заменить на другой фрагмент ОА-графа, который справа;
ѕ «>+» — добавление ОА-графа, слева ОА-граф, который необходимо преобразовать, справа преобразованный ОА-граф, обычно используется при модификации семантического графа;
ѕ : — добавленная конструкция;
ѕ = - ИП, где слева находится мнемоника атрибута, а справа нагрузка;
ѕ {…} - ОА-капсула;
ѕ Point{…}, где oint — это указатель на капсулу, описанную после мнемоники Point;
ѕ Atr = Const/Point, где Const — константа, которая хранится в нагрузке ИП и может быть числовой, логической, символом или строкой символов, а Point — указатель, который хранится в ИП;
ѕ * - сцепление двух ИК (конкатенация);
ѕ Atr=*{} - конкатенация к ИК из нагрузки ИП;
ѕ #Point — копирование ИК, куда указывает Point;
ѕ F/L Point — первая/последняя ИП в капсуле по адресу Point;
ѕ 'Point — удаление из ИК первой ИП по адресу Point;
ѕ Point' - удаление из ИК последней ИП по адресу Point;
ѕ {…} {…} - операция перечисления;
ѕ | - показывает альтернативные варианты информационных конструкций, где в левой части обозначается одно из вариантов конструкции, а в правой синтез списка вариантов толкований;
ѕ () — знак старшинства операций (например операция альтернатив имеет меньший приоритет, чем перечисление ИП, и чтобы можно было изменить приоритет, используется знак (,));
ѕ […] - если в данных скобках описан ОА-граф, то он может не присутствовать в списке или только один раз присутствовать.
Сейчас, с помощью ОА-подхода, разработана методика поискового поиска. Пользователь отправляет запрос на естественном языке, он преобразуется в ОА-граф, потом в базе данных (БД) осуществляется поиск подграфа, который совпадает с графом запроса. Совпадение происходит, если топологии графа запроса и подграфа из БД идентичны, при этом множества ИП, которые расположены в узлах графа запроса, обязаны быть подмножествами подобающих множеств подграфа БД в узлах [23].
Сравнение форматов представления семантической сети Для сравнения форматов необходимо определиться с критериями, по которым будет проходить сравнение. Главным критерием для работы является возможность отражения семантики. Также важна структура, гибкость построения и модификации структуры сети. Помимо данных критериев, также будет рассматриваться простота описания семантической сети с помощью специализированного языка.
Первоначально рассмотрим структуры и гибкость построения таких форматов, как XML, RDF, JSON и ОА-язык.
У XML древовидная структура, содержащая родителя (корень) и дочерние элементы. Поиск информации (от англ. parsing — анализ, разбор) начинается с корня, и далее первую ветвь двигает вниз к элементу, принимая первую ветвь и т. д. к узлам листьев.
RDF имеет совершенно другую структуру, она состоит в наличии триплетов, которые в свою очередь, состоят из субъекта, объекта и предиката. RDF графы — это набор триплетов, где каждый триплет имеет вид связи узел-дуга-узел. Дуга всегда по направлению идет к объекту.
JSON может использовать две универсальные структуры, где первая — это коллекция пар ключ-значение. Данная концепция реализована с помощью объекта, структуры, записи, кэш-таблицы, словаря, ассоциативного массива или именованного списка. А вторая — это упорядоченный набор значений, реализован с помощью массива, вектора, списка иди последовательности.
В ОА-подходе реализуется принцип управления вычислительным процессом с помощью потока данных (dataflow). Синтез информационных конструкций осуществляется от легкого к сложному, то есть ОА-система разделяется на несколько уровней абстракции. Процесс начинается с элементарных абстракций и переходит к более высоким. Каждый последующий уровень абстракции становится все сложней и сложней предыдущего и их количество постоянно уменьшается, таким образом сложная абстракция представляет из себя достаточно большим смысловым графом. На последнем уровне абстракций находится заключительная, ключевая абстракция, которая полностью описывает распознаваемый объект. В случае, если необходимо произвести синтез наиболее простых абстракций, то будет применяться обратный способ, то есть синтез будет идти от сложного к простому.
Если сравнивать данные форматы на простоту описания и объемность кода, то XML проигрывает сразу в двух критериях, его код имеет существенно больший размер по сравнению с остальными форматами и достаточно трудно воспринимается. RDF имеет меньший размер кода и легче воспринимается, но тоже проигрывает форматам JSON и ОА-языку.
Далее рассмотрим форматы на возможность отражения семантики.
XML поддерживает семантику, способную расширяться, данный язык позволяет вводить новые синтаксические элементы в свои конструкции, которые, в свою очередь, могут изменяться произвольным образом. Иными словами, XML можно рассматривать как способ транспортировки для семантической информации для других программ, которые способны интерпретировать ее. Таким образом, XML является только посредником для передачи семантической информации.
RDF тоже поддерживает семантику, но он базируется на формальной семантике, которая описывается средствами абстрактного синтаксиса, который задается модельное представление, а также способ логической интерпретации, а не конкретный вид конструкций и элементов отображаемого языка. Данный формат описывает логические утверждения в виде триплетов, которые образуют в итоге ориентированный граф. Абстрактный синтаксис ориентирован именно на описание модели данных, т. е. данного графа. Граф представляется как формальная семантическая модель естественного языка. После данная семантическая модель может быть выражена разными способами, например, как графическая модель. Минусом данного языка является неоднородность информационной структуры, она сложна для модификации и довольно громоздка для описания семантических связях, которые будут описывать более двух сущностей.
JSON является наиболее близким к ОА-языку. Текстовый формат языка облегчает обмен между языками программирования структурированными данными.
Такая структура как пара имя/значение весьма схожа с информационной парой в ОА формате. Также JSON поддерживает упорядоченные списки значений, благодаря этому язык может осуществлять построение сложных структур, например структуру дерево.
Главным минусов JSON является отсутствие прямой поддержки циклических графов, что существенно снижает возможность описания сложных онтологий. Таким образом, JSON не предоставляет средства для модификации структур данных в отличие от ОА-подхода.
Несмотря на плюсы и минусы осмотренных форматов, в данной работе более выгодно применять ОА архитектуру вычислительных систем, которая является новым подходом к построению объектных систем. Данный подход обладает наиболее большими возможностями для объектного программирования и создания интеллектуальных систем, чем общепринятое в настоящее время объектно-ориентированное программирование (ООП). Подход реализует с помощью потока данных (dataflow) принцип управления вычислительным процессом. Предложенная архитектура также позволяет легко создавать распределенные объектные системы (ООП же изначально предназначено для систем с общей оперативной памятью).
Также, в завершение, можно отметить еще несколько положительных сторон ОА-архитектуры. Она имеет удобную структуру не только данных, но и программы, имеет изоморфизм, легко реализуется программно и аппаратно. При реализации программной части, ее можно легко перенести с одной платформы на другую, также АО-архитектура обладает хорошей масштабируемостью на обоих уровнях и облегчает процесс написания программы.