Распознавание изображений.
Разработка прототипа настольной автоматизированной программы, реализующей распознавание изображений пыльцевых зерен с помощью комбинаций функций OpenCV и метода голосования

Так как для классификации будет использоваться метод голосования основывающий на сравнении признаков, то необходимо сформировать набор признаков и формулы для их вычисления. Объект может быть отнесен к классу, которому соответствует такая оценка, что отношение ее к сумме оценок для всех остальных классов будет не меньше значения порога и т. д. Объект может быть отнесен к классу, которому… Читать ещё >
Распознавание изображений. Разработка прототипа настольной автоматизированной программы, реализующей распознавание изображений пыльцевых зерен с помощью комбинаций функций OpenCV и метода голосования (реферат, курсовая, диплом, контрольная)
После того как пыльцевые зерна были успешно сегментированы на изображении можно приступать к их распознаванию. Для этого необходимо вычислить значения признаков (характеристик) каждого объекта, на основании чего алгоритм классификации сможет спрогнозировать класс объекта.
Итак, далее более подробно рассмотрим отбор характеристик и алгоритм классификации объектов (пыльцевых зерен).
Так как для классификации будет использоваться метод голосования основывающий на сравнении признаков, то необходимо сформировать набор признаков и формулы для их вычисления.
Для классификации пыльцевых зерен были отобраны 12 признаков (табл. 2.1).
Хотя данные 12 признаков были выбраны после полного изучения литературы, зачастую имеются неуместные особенности и бесполезная информация, которые ухудшают производительность моделей как в скорости, из-за высокой размерности, так и в точности из-за ненужной информации. Выбор признаков имеет цель выбора наименьшего возможного подмножество признаков P необходимых для описания проблемы с начальным набором N признаков, где P =< N. Другими словами, выбор признаков может быть определен как процесс поиска для удаления неуместных и/или избыточных признаков для получения более простой системы классификации. В некоторых задачах отбор признаков необходим не только для более высокой производительности, но и для более точной классификации.
Конкретная цель состоит в том, чтобы попытаться уменьшить первоначальный пул из 12 признаков только в самые необходимые, не оказывая влияния на общую производительность модели классификации. Для достижения этой цели необходимо вычислить значимость каждого конкретного признака для данной модели распознавания и исключить наименее значимые. Для вычисления значимости можно провести корреляционный анализ. Более подробно данную задачу мы рассмотрим в разделе реализации и тестировании системы, а также при анализе результатов.
Таблица 2.1. Признаки пыльцевых зерен.
№. | Название признака. | Пояснение. | Формула вычисления. | |
Area (A). | Область. | Количество пикселей, представляющих область пыльцевых зерен. | ||
Perimeter (P). | Периметр | Количество пикселей, которые образуют границу пыльцевых зерен. | ||
Compactness ©. | Компактность. | |||
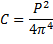 | Diameter (D). | Диаметр | Наибольшее расстояние между любыми двумя точками границы. | |
Rmax. | Максимальный радиус. | Максимальное расстояние между центром зерна пыльцы и любой точкой на ее границе. | ||
Rmin. | Минимальный радиус. | Минимальное расстояние между центром зерна пыльцы и любой точкой на ее границе. | ||
Rd. | Дисперсия радиуса. | Изменчивость расстояний между центром и всех граничных точек пыльцевых зерен. | ||
R (среднее). | Средний радиус. | Среднее расстояние между центром зерна и всеми точками границы зерна пыльцы. | ||
Rmax/Rmin. | Отношение между Rmax и Rmin. | Соотношение между максимальным и минимальным расстоянием граничных точек зерна и центра. | ||
Rmax/R (среднее). | Отношение между Rmax и R (среднее). | Соотношение между максимальным и средним расстоянием граничных точек зерна и центра. | ||
Rmin/R (среднее). | Отношение между Rmin и R (среднее). | Соотношение между минимальным и средним расстоянием граничных точек зерна и центра. | ||
Eccentricity (E). | Эксцентриситет. | |||
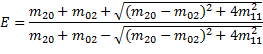
Классификации сегментированных пыльцевых зерен будет выполняться методом голосования. Данный метод предложен Ю. И. Журавлевым и иначе его еще называют алгоритм вычисления оценок.
Пусть множество объектов w подразделено на классы U[i], i=1.m, и для описания объектов используются признаки x[j], j=1.N. Все объекты одном и тем же набором признаков. Каждый из признаков может принимать значения из различных множеств (алфавитов), например:
- 1. 0,1, где 0 — признак не выражен; 1 -выражен;
- 2. 0,1,X, где X — информация о признаке отсутствует;
- 3. 0,1,., c — степень выраженности признака имеет различные градации;
- 4. [a, b] - признак принимает значение из числового отрезка;
- 5. f[i](x1,., xn) — задана условная плотность распределения значений признаков.
Априорная (исходная) информация формируется в виде таблицы, содержащей значения признаков x1,.xn всех объектов, принадлежащих различным классам.
Под распознаваемым объектом будем понимать вектор признаков, компонентами которого являются конкретные значения:
w' = b[1], b[2],. b[N]. (6).
Суть данного метода заключается в том, что он оперирует не отдельными признаками, а различными сочетаниями признаков (ансамблями признаков).
Сочетания признаков иначе называют систему опорных множеств метода голосования.
Так как не всегда известно наиболее информативные сочетания признаков, входящих в опорные множества, то степень похожести объектов вычисляется сопоставлением всех возможных (или каких-то определенных) опорных множеств признаков, входящих в описание объекта.
Рассмотрим полный набор признаков X=x1,x2,., xn и выделим систему опорных множеств признаков S1, S2,., SL.
В качестве системы опорных множеств чаще всего рассматривают:
- 1. Либо все подмножества множества признаков фиксированной длины k, где k принимает значения из множества 2,., N-1.
- 2. Либо вообще все подмножества множества признаков.
Рассмотрим процедуру вычисления оценок по подмножеству S1. Вычисление оценок для остальных подмножеств выполняется аналогично.
В таблице выделяются столбцы, соответствующие признакам, входящим в S1. Проверяется близость строки S1w~' со строками S1w~[1], …, S1w~[r[1]], соответствующим объектам класса U1.
Число строк этого класса, близких по выбранному критерию классифицируемой строке S1w~', обозначается через Г[S1](w', U1) — оценка строки w' для класса U1 по опорному множеству S1. Аналогично вычисляются оценки для остальных классов Г[S1](w', U2),…, Г[S1](w', Um) по опорному множеству S1.
Применение подобной процедуры ко всем остальным опорным множествам алгоритма позволяет получить систему оценок:
Г[S2](w', U1), …, Г[S2](w', Um), …, Г[SL](w', U1), …, Г[SL](w', Um). (7).
На основании анализа данной системы оценок принимается решение либо об отнесении объекта к одному из классов U[i], i=1.m, либо об отказе от его распознавания.
Решающее правило может принимать следующие формы:
- 1. Объект может быть отнесен к классу, которому соответствует максимальная оценка.
- 2. Объект может быть отнесен к классу, которому соответствует оценка, превышающая оценки всех остальных классов не меньше чем на определенную пороговую величину.
- 3. Объект может быть отнесен к классу, которому соответствует такая оценка, что отношение ее к сумме оценок для всех остальных классов будет не меньше значения порога и т. д.
Итак, алгоритм распознавания методом голосования сравнивает описание распознаваемого объекта с описаниями всех объектов, содержащихся в таблице, и принимает решение о том, к какому классу отнести объект. Классификация основана на вычислении степени похожести (оценки) распознаваемого объекта на объекты, принадлежность которых к классам известна. Эта процедура включает в себя три этапа:
- 1. Вычисление оценок по опорным множествам для каждого объекта из таблицы.
- 2. Затем эти оценки используются для вычисление суммарных оценок для каждого из классов U[i].
- 3. Применение решающего правила для классификации объекта.
Решающее правило выбирает класс объекта с максимальной оценкой.