Многомерная модель данных

Хранимые классы объектов наследуются от системного класса % Library. Persistent и способны длительно храниться в памяти объекта. Экземпляры таких классов обладают однозначными объектными идентификаторами OID. Хранимый объект может использоваться и как свойство класса (столбец таблицы) другого объекта. Иными словами, возможна ссылка на этот объект, что соответствует связи I: М двух таблиц… Читать ещё >
Многомерная модель данных (реферат, курсовая, диплом, контрольная)
Вообще говоря, ММД может взаимодействовать и с реляционной БД, потому данный параграф уместен и в гл. 5. Однако взаимодействие с объектно-ориентированной моделью предпочтительнее, и потому рассмотрим ММД здесь.
Многомерная модель используется, как отмечалось ранее, в хранилищах данных. Имеются три разновидности ММД: MOLAP, ROLAP, HOLAP.
MOLAP предполагает формирование так называемого многомерного куба (гиперкуба). Трехмерный куб показан на рис. 7.4.
Каждая из координат куба называется измерением. Измерения реализуются с помощью индексов, которые, как известно, позволяют резко увеличить скорость доступа к данным. По разным оценкам, эта скорость в 10−100 раз выше, чем в реляционных моделях данных. Значение результата в многомерной модели помещается на пересечении (в ячейке) соответствующих значений измерений.

Рис. 7.4. Трехмерный куб Аналогом такой модели можно считать задание функции, например, Z = f(x, y). В ММД координаты х и у суть измерения, а Z — значение-результат. Как и в функции нескольких переменных, в ММД должна быть предусмотрена возможность «движения» как внутри одного измерения, так и перехода с одного измерения на другое (например, от «линии» к «плоскости»).
За увеличенную скорость доступа приходится платить увеличенным объемом памяти. Соотношение между полезным и потребным объемами памяти в многомерной модели данных в 5−10 раз больше, чем в реляционной модели данных. Кроме того, в ММД много пустых ячеек, и требуются специальные эффективные программы хранения значения NULL. Желательно удаление пустых ячеек. В многомерной модели выполняются четыре основные операции: агрегация (свертка) данных; дезагрегация (детализация) данных; сечение (при фиксированных значениях одного или нескольких измерений); вращение (для двумерного случая это аналог транспонирования матрицы).
В ROLAP используются реляционные «составляющие». Возможны две схемы структуры: «звезда» (рис. 7.5) и «снежинка» (рис. 7.6).
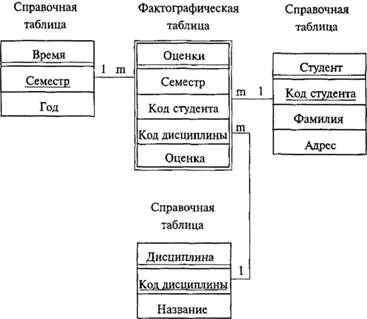
Рис. 7.5. Схема «Звезда» .
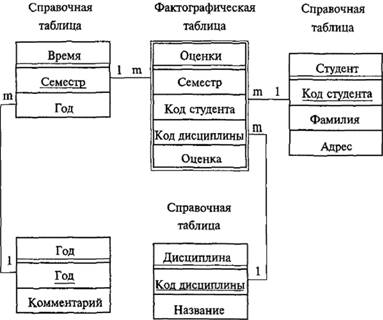
Рис. 7.6. Схема «Снежинка» .
В любой схеме выделяются одна фактологическая таблица, в которой, собственно, и хранятся данные, и несколько справочных таблиц, каждая из которых характеризует одну из размерностей куба. При использовании схемы «звезда» требуется проведение денормализации данных.
ROLAP позволяет дать характеристику размерности хранилища данных (табл. 7.3).
Таблица 7.3
Размерность хранилища данных
Размерность. | Предельный объем, Гбайт. | Число строк н фактологической таблице, млн. |
Маленькая. | 1−10. | |
Средняя. | 11−100. | |
Большая. | 101−999. | |
Сверхбольшая. | Более 200. | 1000 и более. |
Сравнение MOLAP и ROLAP дает следующие результаты:
- • MOLAP обладает высоким быстродействием, но возникают проблемы с хранением больших объемов данных;
- • ROLAP не имеет ограничений на объем данных, однако обладает гораздо меньшим быстродействием.
Отсюда возникает идея построения HOLAP, совмещающего достоинства MOLAP и ROLAP.
HOLAP. Дело в том, что все данные ХД одновременно никогда не требуются. Каждый раз используется лишь их часть. В связи с этим целесообразно данные разделить на предметные подобласти, которые называют киосками (магазинами, витринами) данных. Киоск данных [17] - специализированное тематическое хранилище, обслуживающее одно из направлений деятельности фирмы.
В этом случае центральное хранилище может быть реализовано с использованием реляционной БД, а основные данные хранятся в многочисленных киосках.
CACHE как система управления объектно-ориентированной базой данных
Покажем некоторые особенности построения объектно-ориентированной базы данных на примере СУБД CACHE.
Прежде всего обратим внимание на объектно-ориентированное (объектное) построение собственно БД в рамках СУБД CACHE, поскольку объектное построение интерфейса пользователя и алгоритма приложения подробно обсуждалось в гл. 1.
В СУБД CACHE используется «объектная» специфическая терминология, несколько отличная от системы определений объектноориентированного подхода.
Чтобы было ясно, о чем идет речь, сведем эту терминологию в таблицу (табл. 7.4), из которой видны особенности структуры ООБД (ООСУБД).
- 1. Ячейки таблиц, как и в расширенных ОРБД, неатомарны. В качестве ячеек могут выступать коллекции (списки, массивы), что соответствует спискам (List) и многомерным наборам (MULTISET) в расширенной объектно-реляционной БД.
- 2. Связи между классами устанавливаются через указатели (OID, OREF).
- 3. Общие подтаблицы нескольких таблиц формируются как встраиваемые объекты (аналог абстрактных классов ROW, и прежде всего — ROW TYPE объектно-реляционных БД).
- 4. Предусмотрена возможность хранения больших объектов.
Таблица 7.4
Сравнительная терминология
CACHE. | Реляционные БД. | Объектно-ориентированный подход. |
Класс. | Таблица. | Класс. |
Экземпляр класса (объект). | Строка. | ; |
Идентификатор OID. | Ключ. | ; |
Свойство. | Столбец, поле. | Свойство. |
Ссылка на хранимый объект. | Внешний ключ. | ; |
Встраиваемый объект. | Повторяющиеся поля, используемые в нескольких таблицах. | ; |
Метод класса. | Хранимая процедура. | Метод. |
Коллекциясписок. | Столбец с ячейкойсписком. | ; |
Коллекция-массив. | Подтаблица. | ; |
Запрос. | Хранимая процедура или вид. | ; |
Поток данных. | BLOB. | ; |
Рассмотрим построение собственно базы данных.
В соответствии с объектно-ориентированным подходом следует рассмотреть понятие «класс» и ассоциированные с ними термины (свойство, метод).
Понятие «класс» в СУБД CACHE достаточно многогранно (рис. 7.7). Прежде всего выделяют классы типов данных и классы самих данных (классы объектов, таблицы).
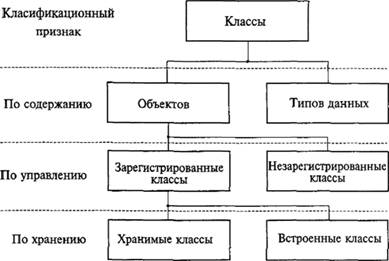
Рис. 7.7. Виды классов Термин «класс» в СУБД CACHE имеет два понимания: объект; множество (подмножество).
Классы типов данных (в том числе созданных пользователями) приписываются атрибутам (полям, свойствам) объектов (таблиц), получающим данные того или иного типа в качестве значений. Эти классы не могут содержать свойств и образовывать экземпляры, не имеют собственной идентификации (для ссылок), однако обладают методами. Каждый тип данных представляет собой класс. Классы типов данных могут создаваться и пользователями.
Имеются три формата типов данных: хранения в БД (storage), логический (logical) в памяти компьютера, отображения (display) на экране монитора. Форматы могут быть преобразованы друг в друга.
Методы классов типов данных предоставляются через интерфейс типов данных (с их параметрами). Перечислим основные типы данных (в логическом формате): %Library.String, %Library.Binary, %Library.Boolean, %%Library.List (формат списка), Library. Numeric, % Library. Integer, %Library.Float, %Library.Name (имя в формате «Фамилия Имя»), % Library. Date, % Library. Time, %Library.Currency (денежный).
Объектом называют экземпляр класса (строку) в отличие от реализации компонента в соответствующем контейнере (как, например, в программном продукте Delphi).
Класс объектов определяет структуру данных и поведение объектов одного типа. Класс объектов характеризуется именем класса, свойствами, методами.
В классах объектов по характеру процессов выделяют незарегистрированные и зарегистрированные классы.
Незарегистрированные классы не поддерживают полиморфизм и не обладают автоматическим управлением. Назначение идентификаторов (OID) и объектных ссылок (OREF) осуществляет пользователь.
Зарегистрированные классы поддерживают полиморфизм и управляются автоматически от системного класса % Library. RegisteredObject (аналог классу TObject в Delphi). Экземпляры этого класса существуют в памяти процесса временно (временные объекты).
С точки зрения хранения данных зарегистрированные и незарегистрированные классы делятся на хранимые и встраиваемые.
Хранимые классы объектов наследуются от системного класса % Library. Persistent и способны длительно храниться в памяти объекта. Экземпляры таких классов обладают однозначными объектными идентификаторами OID. Хранимый объект может использоваться и как свойство класса (столбец таблицы) другого объекта. Иными словами, возможна ссылка на этот объект, что соответствует связи I: М двух таблиц реляционной БД.
Встраиваемые классы объектов наследуют свое поведение от системного класса % Library. SerialObject и могут быть сохранены только в составе соответствующих хранимых объектов. Встроенный объект в памяти характеризуется объектной ссылкой, в базе данных хранится в последовательной форме (разновидность коллекции-массива) как часть хранимого объекта, при этом идентификатор OID отсутствует.
Построение классов объектов возможно в режиме диалога или с помощью языков программирования (командная строка, программа). В диалоговом режиме возможно использовать визуальный язык (аналог языка QBE для запросов) или сопровождающий его язык определения классов (CACHE Definition Language — CDL) — аналог языка SQL в реляционных БД.
В качестве свойств (рис. 7.8) выступают константы (независимо от класса типа), встроенные объекты, ссылки на объекты, потоки данных BLOB, коллекции, многомерные переменные, двунаправленные связи между хранимыми объектами.
Потоки данных BLOB имеют две разновидности для символьных (CHARACTERSTREAM) и двоичных (BINARYSTREAM) данных (аналогично CLOB и BLOB для гибридных ОРБД).
Коллекции могут быть списком (List Collection) и массивом (Array Collection). В их состав могут входить константы, встроенные объекты и ссылки, которые задаются соответственно % Library. ListOfDataTypes, %Library.ListOfObjects, %Library.ArrayOfDataTypes, %Library.ArrayOf Objects.

Рис. 7.8. Типы свойств В коллекции-массиве упорядочение ведется по полю, принятому в качестве ключа.
В коллекции-списке в качестве ключа выступает позиция элемента в списке.
Связь является двунаправленной — взаимные ссылки между таблицами. Они гарантируют ссылочную целостность.
Имеются временные (буферная память) и вычисляемые свойства.
Методы, как уже отмечалось, связаны с типом данных. По умолчанию принимается тип данных String.
Аргументы метода по умолчанию передаются по значению, а для передачи по ссылке аргументу должен предшествовать символ &. Методы, как и свойства, могут быть определены как public или private.
Выделяют методы класса и методы экземпляров класса (ссылка — ##this). Последние используются чаще.
В объектной модели выделяют:
- • метод-код (код программ на языке CACHE ObjectScript);
- • метод-выражение (одно выражение кода программы), в котором передача параметров проводится по ссылке, использование макросов, «встроенных» фрагментов SQL не допускается;
- • метод-вызов (подпрограмм);
- • генератор метода, используемый при компиляции программы и классов (чтобы классами можно было пользоваться).
Свойства характеризуются именем класса, именем свойства, типом данных, ключевыми словами, параметрами для типов данных. Свойства могут быть открытыми (public) и закрытыми (private).
Свойство связано с набором методов, который имеет два источника:
- 1) класс свойств (методы доступа Get () и Set ());
- 2) тип данных.
Для классов CACHE, наряду с такими понятиями, как «свойство», «метод», характерны специфические понятия «параметры класса», «запросы», «индексы» .
Параметры класса используются при компиляции.
Запрос — операции с множествами экземпляров классов. Результат запроса доступен через специальный интерфейс обработки результатов запросов ResultSet. Запросы могут иметь форму хранимых процедур.
Индекс — путь доступа к экземпляру класса. Он используется для повышения скорости выполнения запросов. Индекс создается на основе одного или нескольких свойств (полей).
Взаимодействие описанных составных частей СУБД (БД) обеспечивается языками программирования.
В CACHE существует три вида доступа (рис. 7.9).
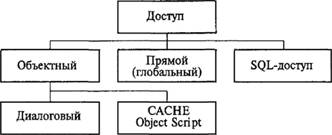
Рис. 7.9. Виды доступа в СУБД CACHE.
Объектный доступ осуществляется в диалоге или с помощью языка программирования CACHE ObjectScript.
В прямом доступе используется многомерная модель данных (ММД). Именно в многомерной структуре ядра БД хранятся данные.
Суть ММД фактически заключается в задании значений некоторой функции от множества координат.
Пусть координаты имеют текущие значения i, j, k, l соответственно, а значение «функции» в этой «точке» — А.кГ Тогда это значение можно определить многомерной матрицей или набором.
<i, j, k, l,Aijkl>.
В рамках СУБД CACHE этот факт записывается в виде A(i, j, k, l) = Аijkl.
Возникает вопрос реализации такой модели. Для этого используют B*-дерево — иерархическое В-дерево, в каждом узле которого имеется блок. В этом случае данные в узлах представляются «координатами» и значениями (рис. 7.10).
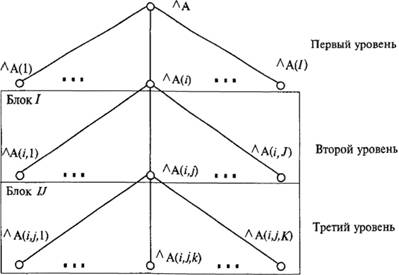
Рис. 7.10. В*-дерево В качестве «координат» удобно использовать индексы, а в рамках СУБД CACHE — глобальные переменные (глобалы).
ММД не рассматривается как инструмент реализации приложений, а служит основой хранения данных и используется при построении хранилищ данных (систем OLAP).
Особый интерес с позиций «перекачки» данных из реляционной СУБД в объектно-ориентированную представляет SQL-доступ. Основу SQL-доступа составляет язык программирования SQL2 (или SQL92). Этот язык предназначен для реляционных баз данных. СУБД CACHE, как показано в гл. 2, отличается по структуре от реляционных СУБД. Основные отличия связаны с неатомарностью ячеек БД. В таких ячейках может присутствовать встроенный класс (таблица) или коллекция.
К тому же необходимо реализовать процедуры наследования.
Таким образом, следует трансформировать язык SQL2, чтобы стало возможно оперировать с неатомарными ячейками и обеспечить процедуру наследования.
Именно по этому пути (а не по пути создания нового языка SQL3) пошли создатели СУБД CACHE.
Прежде всего следует отметить, что в рамках единой архитектуры CACHE каждый класс объектного представления является таблицей с тем же именем, а каждая таблица реляционной парадигмы — объектом. Соотношение объектов и реляционных аналогов приведено в табл. 7.4.
Заметим, что в реляционной БД нет точных аналогов методов и параметров классов и экземпляров классов, временных свойств. С другой стороны, в реляционном представлении имеют место триггеры, которые не нужны в объектной среде.
Экземплярам объектов соответствуют записи, идентифицируемые с помощью первичного ключа. Для хранимых объектов в качестве такого ключа возможно использовать идентификатор ID объекта (примерный аналог поля с типом данных «счетчик»).
Наследование в объектном представлении трансформируется в набор исходной и наследуемой таблиц.
По умолчанию имена объектного свойства и реляционного поля одинаковы. Переименование возможно с помощью ключевого слова SQLFIELDNAME в определении объектного свойства.
Объектные свойства-константы (атомарные ячейки) могут быть временными, многомерными и вычисляемыми. Вычисляемые свойства автоматически в таблицах не отображаются. В реляционной трактовке для этого следует предусмотреть вычисляемые поля. Последние могут быть трансформированы в вычисляемые свойства.
Удобнее вычисления размещать в методах класса, которые могут вызываться и из методов вычисления свойств, и как вычисляемые поля.
Ссылки на хранимые объекты осуществляются внешним ключом.
Встроенные объекты характеризуются составным именем поля с использованием символа подчеркивания (_), т. e. Addres_Ulica.
Коллекция-список отображается в виде отдельного поля, содержащего список значений.
Коллекция-массив представляется в виде отдельной подтаблицы, связанной с основной таблицей через внешний ключ. Имя подтаблицы то же составное: _.
Объектным запросам соответствуют хранимые процедуры и виды (View). Ключевые слова — SQLPROC, SQLVIEW, SQLVIEWNAME.
Методы класса могут быть отображены в коде в виде вычисляемых полей или в виде хранимых процедур. Могут использоваться и триггеры, определяемые в объектном представлении на языке CDL или в рамках CACHE Object Architect.
Выделяют вложенный и встроенный языки SQL. Структура языка SQL2 (интерфейсного и вложенного) отображена во многих источниках.
В связи с этим акцентируем внимание на отличиях языка SQL в СУБД CACHE (CACHE SQL) от языка SQL2. Расширение вложенного языка SQL2 имеет место в следующих направлениях:
- 1) дополнительные операторы;
- 2) объект CURSOR;
- 3) поля-списки;
- 4) соединения (ссылки, отношения зависимости).
- 1. Дополнительными операторами являются:
=* - внешнее соединение;
-> - неявное соединение;
_, # - конкатенация (имен) и целочисленный остаток от деления (модуль);
- ? — оператор проверки по шаблону;
- (- оператор вхождения;
& - оператор И;
! — оператор ИЛИ;
] - оператор следования за.
Возможно использование как одинарных, так и двойных кавычек; приставки not перед логическими операторами (not =, not).
2. В дополнение к таким объектам, как таблицы, виды, хранимые процедуры, индексы, ограничения, генераторы, триггеры, в рамках CACHE используют объект SQL2, получивший название CURSOR.
CURSOR — некоторый набор данных, формируемый чаще всего оператором select. Он содержит несколько записей и отличается от хранимых процедур, которые только вычисляют набор данных, и вида, вычисляемого каждый раз при запросе к нему. CURSOR вычисляется один раз и существует до момента его уничтожения.
Покажем процедуру создания курсора, снабдив ее соответствующими комментариями.
/*Создание курсора*/.
DECLARE PersCur CURSOR.
FOR SELECT Familia, DateRogd.
FROM Person.
WHERE Familia-Петров'.
/*для объявленного курсора возможно использовать предложения OPEN, FETCH, CLOSE*/.
OPEN PersCur.
/'считывание содержимого полей в локальные переменные, как в хранимых процедурах */.
FETCH PersCur INTO: Familia, :DateRogd.
/*следует отметить, что локальные переменные могли быть заданы и при определении курсора */.
DECLARE PersCur CURSOR.
FOR SELECT Familia, DateRogd INTO: Familia, :DateRogd.
FROM Person.
WHERE Familia='neTpoB'.
/*в этом случае оператор извлечения данных меняется */ FETCH PersCur.
/*не используемый курсор закрывается */.
CLOSE PersCur.
Результаты запроса могут считываться и в индексированные переменные.
FETCH PersCur INTO: а ('Результат запроса Т) в данном случае — в трехуровневую переменную; в объекты, например объект с OREF=provider.
FETCH PersCur INTO: Familia.
Set provider. Familia=Familia.
Данные могут быть вставлены в курсор (запрос оператором INSERT) из переменных и индексированных переменных (как параметров).
- 1. Обращение к полям-спискам рассматривалось ранее.
- 2. Соединения могут быть внешними и неявными.
Во внешнем соединении (в отличие от внутреннего) «соединяемые» поля первой таблицы отражаются даже в том случае, если для поля во второй таблице не найдены соответствующие строки.
Во внешнем соединении CACHE в предложении WHERE вместо символа = применяется символ =*.
Неявное соединение определяется не запросом пользователя, а поддерживается БД. В неявных соединениях выделяют ссылки и отношения зависимости.
В ссылке поле ссылающейся таблицы содержит первичный ключ ID записи таблицы (указатель), на которую она ссылается.
SELECT Name, Manufacturer -> Surname FROM Tovar.
WHERE Туре='инструмент',.
что соответствует.
SELECT Tovar.Name, Manufacturer. Surname FROM Tovar, Manufacturer.
WHERE Туре="инструмент" .
ANDTovar.Manufacturer=Manufacturer.lD.
Отношение зависимости — отношение 1: M от родительской к дочерней таблице. Каждая строка дочерней таблицы ссылается на какую-либо строку родительской таблицы (вариант внутреннего соединения). Это чаще всего относится к встроенным объектам: пусть родительская таблица имеет имя Invoice, дочерняя — Position, а ссылка на нее — Invoice Position.
Выделяют два типа зависимостей: от дочерней таблицы к родительской и от родительской к дочерней.
В первом случае оператор
SELECT lnvoice->Date.
FROM lnvoice_Position.
WHERE Price > 100 000.
аналогичен.
SELECT Invoice.Date.
FROM lnvoice_Position, Invoice.
WHERE Price >100 000.
AND lnvoice_Position.lnvoice=lnvoice.ID.
Во втором случае оператору.
SELECT 1nvoice_Position -> Price.
FROM Invoice WHERE Price > 100 000.
AND lnvoiceNumber= 1 003 274.
соответствует.
SELECT lnvoice_Position_>Price.
FROM Invoice, lnvoice_Position.
WHERE Invoice. lnvoiceNumber=1 003 274.
AND Invoice. ID=lnvoice_Position.Invoice.
Во встроенном языке SQL-операторы «встраиваются» в программу на языке CACHE ObjectScript с помощью препроцессорной функции &sql, например
&sql (SELECT ID INTO: ID.
FROM PERSON.
WHERE Familia=:Familia).
Quit .%Openld (ID).
В качестве SQL-оператора могут выступать операторы обновления, создания объекта (CREATE) и описанный ранее CURSOR.
SQL-данные могут иметь следующие форматы: Logical (по умолчанию), ODBC, Display (не относится к свойствам-константам и значениям переменных).
Во встроенном языке SQL могут использоваться и макровызовы, для которых приняты обозначения: # - препроцессор, ## или & - расширение программного кода, $$$ - макровызов по сделанному ранее макроопределению.
Например,.
#define TABLE Person.
#define FIELDS Familia, Telephon.
#define VARS: Familia, :Telephon.
#define COND Familia %STARTWITH «A».
&sql (SELECT $$$FIELDS.
INTO $$$VARS.
FROM $$$TABLE.
WHERE $$$COND).
С другой стороны, макроопределение может применяться для добавления &sql:
#define GETNEXT &sql (FETCH xcur INTO: a).
FOR $$$GETNEXT Quit: SQLCODE=100 Do abc,.
что эквивалентно.
FOR &sql (FETCH xcur INTO: a).
Quit :SQLCODE=100 Do abc.
Здесь SQLCODE — переменная, характеризующая выполнение &sql: 0 — успешно завершено; 100 — успешно завершено, но не найдено для заданных условий ни одной записи; менее нуля — имеется ошибка.
В заключение отметим, что наиболее удобно осуществлять SQL-доступ из внешних систем, что позволяет использовать такие реляционные объекты, как отчеты. Этот внешний реляционный доступ обеспечивается сервером CACHE SQL и интерфейсом ODBC.
Перспективы развития ООБД
По сравнению с реляционными БД ООБД обладают следующими преимуществами.
- 1. Лучшие возможности моделирования систем из блоков, обладающих произвольными связями.
- 2. Легкая расширяемость структуры за счет создания новых типов данных (свойств), наследования, установления новых связей и корректировки методов.
- 3. Возможность использования рекурсивных методов при навигационном методе доступа к большим объемам данных.
- 4. Повышение производительности в 10−30 раз.
- 5. Более широкая сфера применения (например, использование в мультимедийных системах).
Преимущества ООБД [3] приведут, видимо, к очень широкому их распространению. Однако прежде следует решить ряд задач по устранению недостатков ООБД: создать гибкую структуру БД; построить четкий язык программирования; отработать синтаксис разбора запросов, в том числе — вложенных; определить несколько методов доступа к данным; отработать вопросы одновременного доступа (разрешение конфликтов при множественном наследии); определить сложный перебор данных; отработать защиту и восстановление данных; уточнить семантику (действия) операторов при динамических изменениях; встроить изменение атрибутов дочерних объектов.
Однако и после устранения названных недостатков переход к ООБД будет носить, видимо, эволюционный характер, поскольку сразу отказаться от значительного количества действующих реляционных БД будет нельзя. Такой безболезненный переход будет возможен, если первоначально в ООСУБД будет присутствовать не только объектная, но и реляционная составляющая. Более того, в ООСУБД следует ввести и многомерную модель для формирования хранилищ данных, парадигма которых хорошо согласуется с парадигмой ООБД. Именно такой подход использован в ООСУБД CACHE [38, 40].