Идентификация нестационарности.
Методы социально-экономического прогнозирования. Т.2.

По рис. 8.11 уже видно, что взятие сезонных разностей привело ряд данных к стационарному виду — теперь он носит более случайный характер. При этом мы потеряли 12 значений исходного ряда данных в самом его начале. По ACF и PACF видно, что выбиваются коэффициенты на дальних лагах (большего, чем второй лаг), что косвенно может указывать на нестационарность. Чисто визуально по исходному ряду видно… Читать ещё >
Идентификация нестационарности. Методы социально-экономического прогнозирования. Т.2. (реферат, курсовая, диплом, контрольная)
Теперь, когда мы разобрались с тем, что такое стационарный процесс, и рассмотрели основные методы приведения нестационарных процессов к стационарному виду, выясним, как можно определить, является ли изучаемый процесс стационарным или нет.
Помимо очевидного графического анализа исходного ряда данных, можно предложить еще как минимум два метода, которые позволяют сделать более точные выводы о стационарности.
Первый метод заключается в изучении коррелограмм по исходному ряду данных (о коррелограммах мы уже упоминали в параграфе 5.1.3). Сигнализировать о нестационарности исходного ряда могут следующие черты коррелограмм:
- 1. Автокорреляционная (АКФ) или частная автокорреляционная (ЧАКФ) функция убывает медленно, что находит отражение в том, что несколько коэффициентов автокорреляции оказываются значимо отличными от нуля.
- 2. Несколько значений на лагах больше третьего в АКФ или ЧАКФ оказались значимо отличными от нуля.
- 3. АКФ или ЧАКФ изменяются гармонически, колеблясь около нуля. Это может сигнализировать о наличии сезонности в ряде данных и о том, что для приведения ряда к стационарному требуется взять сезонные разности.
Возьмем для примера ряд № 1999. С помощью функции «tsdisplay» статистического пакета «R» мы построили график исходного ряда и коррелограммы для ряда № 1999. Все они приведены на рис. 8.6.
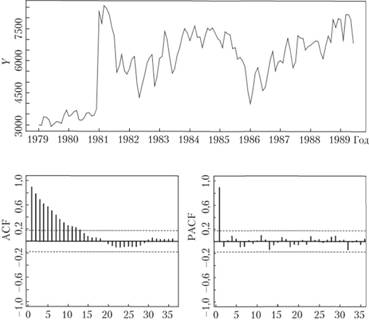
Рис. 8.6. Ряд № 1999, его АКФ и ЧАКФ.
Коррелограмма по коэффициентам автокорреляции, как видим, убывает достаточно медленно, из-за чего значимыми оказались коэффициенты автокорреляции еще вплоть до 12 лага. Это является показателем нестационарности исходного ряда данных. Кроме того, гармоническое поведение АКФ и ЧАКФ наводит на мысль о том, что в ряде данных есть сезонность, однако медленное убывание АКФ не позволяет точно определить это из-за нестационарное™ исходного ряда данных. Чтобы сделать какой-либо однозначный вывод, нужно рассмотреть ряд в разностях (рис. 8.7).
По полученным коррелограммам видно наличие сезонности — значимыми оказались лаги высокого порядка, кроме того, АКФ и ЧАКФ не убывают, а колеблются около нуля. Это сигнализирует о наличии сезонной нестационарности. Взятие сезонных разностей приводит нас к следующему (рис. 8.8).
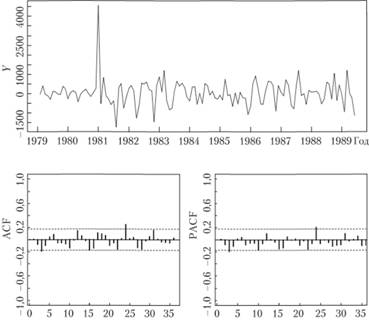
Рис. 8.8. Ряд № 1999 в разностях, его АКФ и ЧАКФ.
Теперь по коррслограммам видно, что коэффициенты автокорреляции и частной автокорреляции на 12-м лаге значительно выходят за рамки доверительного интервала. Все остальные коэффициенты (за исключением 36-го, который кратен 12-му, а значит, скорее всего, вызван все той же сезонной зависимостью) лежат внутри интервала, т. е. статистически незначимы.
В результате всего этого на основе только графического анализа можно заключить, что ряд данных нестационарен и в нем присутствует сезонность.
Однако, как видим, этот метод достаточно субъективен и требует, скорее, опыта работы с временны? ми рядами со стороны исследователя, нежели каких-то глубоких знаний.
Чтобы получить более объективную оценку стационарности, эконометристами были разработаны тесты, основанные на проверке статистических гипотез. Разновидностей этих тестов достаточно много, мы рассмотрим только две (наиболее популярные) из них.
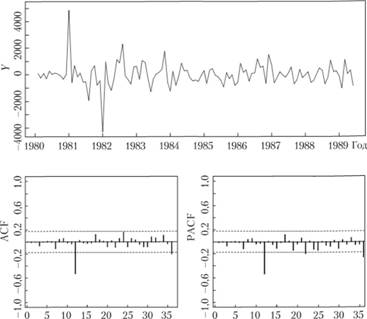
Рис. 8.9. Ряд № 1999 в первых и сезонных разностях, его АКФ и ЧАКФ.
Первый тест — это расширенный тест Дикки — Фулчера (известный за рубежом как «Augmented Dickey — Fuller test» — ADF). Чтобы уяснить суть этого теста, для начала надо познакомиться с базовым тестом Дикки — Фуллера.
В тесте предполагается построение простой авторегрессионной модели вида.
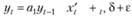 (8.49).
(8.49).
где? — вектор коэффициентов; 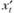 - вектор регрессионных элементов, который может включать в себя константу и трендовую составляющую (линейный тренд), а может и ничего не включать. В полном виде (с константой и трендом) модель (8.49) может быть записана:
- вектор регрессионных элементов, который может включать в себя константу и трендовую составляющую (линейный тренд), а может и ничего не включать. В полном виде (с константой и трендом) модель (8.49) может быть записана: 
Если в качестве регрессоров была включена только константа, она фактически берет на себя уровень ряда и позволяет авторегрессионный элемент «очистить» от его влияния. Таким образом, получается более достоверная оценка коэффициента а1 у в тех случаях, когда ряд не колеблется вокруг нуля.
Похожую функцию выполняет и составляющая линейного тренда: если в ряде данных на всем протяжении наблюдается тенденция к росту, тренд эту тенденцию возьмет на себя и значение а1 опять же будет более корректным.
Определение того, стоит ли включать эти элементы и если стоит, то какие, полностью ложится на плечи исследователя и зависит только от того, с каким рядом он имеет дело.
Далее идея теста Дикки — Фуллера достаточно проста: в случае, если коэффициент а1 оказывается равным либо больше единицы, полученный результат говорит о том, что ряд носит нестационарный характер. Проверка этого осуществляется посредством статистической гипотезы. Для начала, однако, из левой и правой частей (8.49) вычитают значение уt-1.
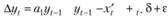 (8.50).
(8.50).
После этого заменяют коэффициент (а1 — 1) на ?:
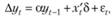 (8.51).
(8.51).
Теперь, если коэффициент исходной модели равен единице, то? = 0, если коэффициент больше 1, то? > 0, что удобно. Далее оценивается регрессия (8.51) и по полученным значениям проверяется следующая гипотеза:
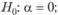
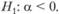
Как мы уже упоминали в параграфе 8.1, ситуации, когда а1 < 0, на практике встречаются крайне редко (а ситуации с условием а1 < -1 и вовсе не встречаются), поэтому альтернативная гипотеза фактически заключается в том, что а1 < 1, a это является индикатором того, что исходный ряд данных описывается стационарной моделью авторегрессии первого порядка.
Чтобы проверить такую гипотезу, достаточно рассчитать t-статистику: 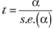 , которая будет распределена по Стьюденту с п — k степенями свободы в том случае, если ошибки полученной модели распределены нормально.
, которая будет распределена по Стьюденту с п — k степенями свободы в том случае, если ошибки полученной модели распределены нормально.
Очевидно, что построив модель (8.51) по ряду данных, исследователь не учитывает всей структуры временно? го ряда и получает очень неточное описание ряда. Это в итоге сказывается на оценке коэффициента a, a значит, и на финальном результате проверки гипотезы. Поэтому для того, чтобы учесть все элементы ряда, был предложен расширенный тест Дикки — Фуллера, отличающийся от первоначального теста только тем, что в (8.51) добавляются еще р значений предыдущих у в разностях (что в итоговой модели фактически соответствует авторегрессии р + 1 порядка):
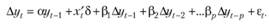 (8.52).
(8.52).
Весь последующий алгоритм оценки коэффициентов и проверки гипотезы идентичен описанному выше. Однако в данном случае уже косвенно оценивается, описывается ли данный временно? й ряд стационарной моделью AR (p + 1) или нестационарной.
Выбор порядка р опять же оказывается на совести исследователя. Как вариант автоматизации этого процесса можно построить р + 1 модель (8.52), выбрать из них модель с наименьшим значением информационного критерия (AIC, BIC и т. п.) и проверить предложенную гипотезу по ней.
Для получения более точной информации о ряде данных тест Дикки-Фуллера проводят еще и по первым, и по вторым разностям ряда, что позволяет сделать более точные выводы о стационарности. Причем, учитывая основные принципы проверки статистических гипотез, тест имеет смысл начинать с взятия вторых разностей. Логика здесь такова. Если исследователь, проведя тест по исходному ряду, получит значение, не отвергающее нулевую гипотезу, он не может однозначно говорить о том, что ряд нестационарен (возможно, у него слишком мало наблюдений либо выбрана некорректная модель). Если же вначале проводится тест по вторым разностям, затем по первым и только после этого по исходному ряду, сохраняется логика проверки гипотез: отвергнув гипотезу во вторых разностях, можно оценить, отвергается ли она в первых разностях, и т. п. Если же гипотеза не отвергается на каком-то из шагов, то это может сигнализировать о нестационарности на данном шаге (например, ряд нестационарен в первых разностях). Конечно же, все полученные результаты имеют смысл только в случае репрезентативности имеющейся выборки, чего достичь в реальных экономических условиях достаточно сложно из-за постоянной эволюции всех экономических систем.
После появления теста Дикки — Фуллера было проведено много исследований по различным рядам данных. В ходе некоторых из них выяснилось, что для многих (если не для всех) агрегированных экономических временны? х рядов нулевая гипотеза о нестационарности не отклонялась. Полученный результат, как это следует из принципов проверки статистических гипотез, вызван тем, как формируются нулевая и альтернативная гипотезы: для того, чтобы отклонить нулевую гипотезу, нужны более сильные доказательства, нежели в случае с ее неотклонением. Поэтому был предложен ряд тестов с другой нулевой и альтернативной гипотезами. Один из них — тест Kwiatkowski, Phillips, Schmidt: & Shin или сокращенно «KPSS» [1].
Тест KPSS базируется на более простой модели, нежели ADF-тест. Подразумевается, что исходный ряд данных может быть описан тремя компонентами:
- 1) детерминированным трендом ?t;
- 2) процессом случайного блуждания rt = rt-1 + иt, причем в качестве r0 обычно выбирается константа;
- 3) случайной стационарной ошибкой? t.
Причем как иt, так и? t i.i.d. (то есть идентично независимо распределенные величины), такие, что Объединяя три компоненты в единую модель, получаем Нулевая гипотеза в тесте заключается в том, что дисперсия иt равна нулю, что в таком случае будет указывать на то, что процесс описывается лишь трендовой компонентой.
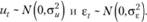 (8.53).
(8.53).
 (8.54).
(8.54).
и константой, т. е. в таком случае процесс становится стационарным относительно тренда. В качестве альтернативного варианта исследователь может убрать трендовую компоненту и проводить тест лишь с компонентой случайного блуждания и ошибкой. В таком случае оценивается стационарность относительно заданного уровня. Формулируются гипотезы соответственно:
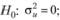
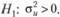
Проверяется этот тест LM-статистикой (тест множителей Лагранжа), рассчитанной по формуле.
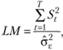 (8.55).
(8.55).
где 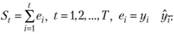
Суть теста заключается в следующем: если в процессе имеется случайное блуждание, то оно будет приводить к систематическим отклонениям от тренда в некоторых частях ряда. Например, на длительном промежутке наблюдается превышение фактических значений над расчетными, а после — занижение. Тогда накопленные остатки St будут расти по модулю. Так, в случае с систематическим завышением St будет положительным и далее будет все увеличиваться вплоть до получения негативных остатков, после которых начнет уменьшаться. В результате этого сумма квадратов St в числителе (8.55) будет достаточно большой (по сравнению с простой дисперсией остатков в знаменателе), а значит, и сама LM-статистика будет большой, что уже косвенно указывает на отклонение нулевой гипотезы.
На практике формула (8.55) применима лишь для случаев с большими выборками и выполнением предположений (8.53). В случае нарушения этих условий используется другая формула:
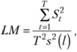 (8.56).
(8.56).
где 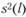 - оценка дисперсии с учетом автокорреляции остатков, произведенная на основе спектральной функции[2]
- оценка дисперсии с учетом автокорреляции остатков, произведенная на основе спектральной функции[2]
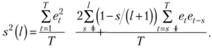 (8.57).
(8.57).
В случае отсутствия автокорреляции остатков вторая часть суммы в (8.57) обращается в нуль, и мы приходим к стандартной оценке дисперсии ошибок.
Процесс проверки гипотезы в тесте KPSS идентичен общепринятому: если расчетное значение, полученное по (8.56), оказывается меньше табличного, у исследователя нет оснований отклонить нулевую гипотезу о стационарности процесса. Так же, как и в случае с ADF, данный тест имеет смысл начинать со вторых разностей. Стоит, однако, заметить, что KPSS не является тестом, замещающим ADF, — он его дополняет, о чем указывали и его авторы.
Рассмотрим на примере, как можно идентифицировать нестационарный процесс и привести его к стационарному виду, используя стандартный общепринятый подход на основе ряда данных № 2568 из базы М3 (к которому мы уже обращались в гл. 6). Ряд выбран неслучайно: в нем даже визуально прослеживаются достаточно четкая сезонность и явная тенденция к росту (рис. 8.9).
Кроме того, по коррелограммам на рис. 8.9 видно, что ряд нестационарен (нет затухания ACF и PACF) и имеет сезонность (коэффициент автокорреляции на 12-м лаге сильно выбивается). Проведем тесты ADF (с константой и трендом) и KPSS (с константой и трендом). Сведем результаты тестов в табл. 8.1, где в столбце ADF будут выведены расчетные значения t-статистик, а в столбце KPSS — расчетные значения LM-статистик.
Таблица 8.1
Результаты тестов на стационарность ряда данных № 2568
Порядок разностей d | ADF. | KPSS. |
— 13,4094. | 0,0168. | |
— 9,6786. | 0,0187. | |
— 4,9528. | 0,0788. |
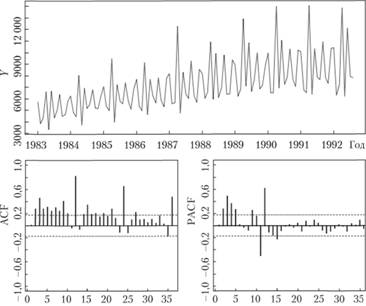
Рис. 8.9. Ряд № 2568 (наверху) и его коррелограммы.
Для интерпретации результатов теста возьмем критические значения для t-статистики и LM-статистики на 5%-ном уровне остаточной вероятности:
- 1) ?-статистика: -3,451 (округленное значение как для теста в разностях, так и для исходного ряда);
- 2) LМ-статистика: 0,146.
Как видим, гипотеза о нестационарности (с учетом тренда и константы) по тесту ADF оттеняется на 5%, как в случае с рядом в разностях, так и в случае с исходным рядом: расчетное значение в обоих случаях оказалось меньше табличного (значения попали в левый хвост распределения).
Результаты с той же интерпретацией получились и для KPSSтеста: на 5% у нас нет оснований отклонить гипотезу о стационарности (с учетом тренда и константы) как исходного, так и ряда в разностях: расчетные значения оказались меньше табличных (значения попали в доверительный интервал).
Все это указывает на то, что в ряде данных наблюдается постоянная тенденция к росту, описываемая трендовой компонентой, которую можно убрать, например, взятием первых разностей. Обращаем внимание на то, что тесты проводились с трендовыми составляющими, поэтому и получен такой вывод.
На рис. 8.9 также видно, что с ростом значения растет и дисперсия, что указывает нам на мультипликативную сезонность, которая с эконометрической точки зрения указывает на наличие гетероскедастичности. Чтобы избавиться от нее, прологарифмируем значения ряда. В итоге получим следующий ряд и коррелограммы (рис. 8.10).
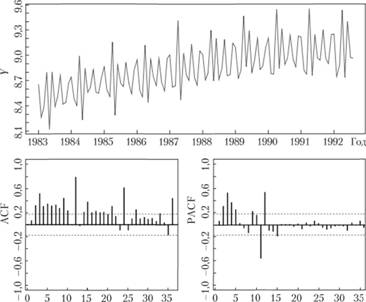
Рис. 8.10. Ряд № 2568 в логарифмах и его коррелограммы.
Как видим, логарифмирование сделало дисперсию по ряду более равномерной, при этом АКФ и ЧАКФ практически не изменились.
Для избавления от сезонности обратимся к сезонным разностям:
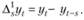
В целом сезонные разности можно рассматривать как оценку того, насколько изменился показатель за сезон (в нашем примере они характеризуют изменение за год).
В нашем случае с учетом взятия логарифмов и того, что ряд данных имеет явную сезонность с лагом s=12, эта формула примет вид.
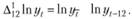 (8.58).
(8.58).
Рассчитаем такие разности и рассмотрим полученный ряд (рис. 8.11).
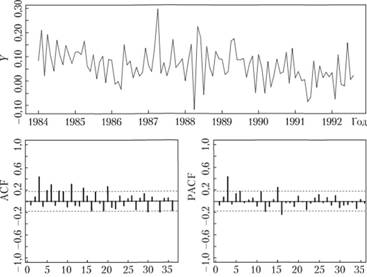
Рис. 8.11. Ряд № 2568 в сезонных разностях логарифмов и его коррелограммы.
По рис. 8.11 уже видно, что взятие сезонных разностей привело ряд данных к стационарному виду — теперь он носит более случайный характер. При этом мы потеряли 12 значений исходного ряда данных в самом его начале. По ACF и PACF видно, что выбиваются коэффициенты на дальних лагах (большего, чем второй лаг), что косвенно может указывать на нестационарность. Чисто визуально по исходному ряду видно, что ряд может все еще быть нестационарным. Проведем тесты для того, чтобы понять, нужно ли над ним работать и далее. В этот раз при проверке гипотез мы не будем включать трендовую составляющую, чтобы оценить стационарность относительно уровня ряда. Результаты тестов сведены в табл. 8.2.
Таблица 8.2
Результаты тестов на стационарность ряда данных № 2568 после логарифмирования и взятия сезонных разностей
Порядок разностей d | ADF. | KPSS. |
— 10,8863. | 0.0294. | |
— 7,8611. | 0,0277. | |
— 3,4817. | 0,4037. |
Критические значения для преобразованного ряда на 5%-ном уровне:
- 1. t-статистика: -2,891 (округленное значение как для теста в разностях, так и для исходного ряда);
- 2. LМ-статистика: 0,463.
Мы вновь приходим к тому, что по ADF-тесту есть основания отклонить нулевую гипотезу о нестационарности исходного ряда (как в разностях, так и исходного), а по KPSS-тесту у нас нет оснований отклонить нулевую гипотезу о стационарности ряда. При этом, учитывая, что мы проводили тесты без трендовой компоненты, в целом можно заключить, что ряд данных после логарифмирования и взятия сезонных разностей можно считать стационарным. Эти результаты, конечно же, не говорят о том, что мы имеем дело со стационарным рядом (ведь по ряду данных на рис. 8.10 видна незначительная тенденция к уменьшению). Скорее, они указывают на то, что имеющиеся тенденции в исследуемом ряде данных сами по себе носят слабый характер и могут быть признаны статистически незначимыми.
Для дальнейшего прогнозирования по полученному ряду данных можно воспользоваться моделью ARMA либо ее модификацией для сезонных рядов — SARIMA, либо простейшими методами прогнозирования. О том, как можно подобрать порядок модели ARMA, мы поговорим в следующем параграфе, поэтому пока дадим прогноз по достаточно простой модели — модели линейного тренда. Для этого рассчитаем ее коэффициенты по преобразованному ряду:
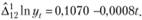 (8.59).
(8.59).
Графически ряд и модель тренда по нему представлены на рис. 8.12.

Рис. 8.12. Ряд № 2568 в сезонных разностях логарифмов и тренд по ряду.
Теперь, чтобы вернуться к исходным величинам, нам нужно восстановить данные. Для начала от сезонных разностей нужно вернуться к исходному ряду в логарифмах. Для этого вместо разностей в формуле (8.58) подставим расчетные значения по тренду (8.59) и из полученной формулы выразим ln уt:
 (8.60).
(8.60).
На участке прогноза вместо 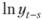 . будем подставлять
. будем подставлять 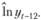 В результате получим следующий ряд данных и прогноз (рис. 8.13).
В результате получим следующий ряд данных и прогноз (рис. 8.13).
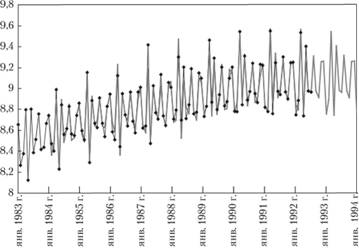
Рис. 8.13. Ряд № 2568 в логарифмах (сплошная линия с точками), расчетные значения и прогноз, но нему (сплошная линия).
Как видим, переход к исходному ряду привел к тому, что исходная сезонность, наблюдавшаяся в ряде данных № 2568, вернулась: прогнозные значения повторяют динамику исходного ряда.
Однако нам осталось еще одно действие — нам нужно перейти к первоначальным величинам. Л для этого надо проэкспонировать полученный ряд. В итоге придем к ряду расчетных значений, изображенному на рис. 8.14, и прогнозу по нему (рис. 8.15).
По рис. 8.14 видно, что итоговый ряд расчетных значений достаточно точно аппроксимировал исходный ряд: наблюдаются не только рост значений и сезонные колебания, но еще и рост дисперсии, т. е. все черты, присущие исходному ряду, повторяются в расчетных значениях. На себя обращает внимание потеря 12 первых значений, что может быть неприятно на малых выборках, по в нашем случае оказалось совершенно некритичным.
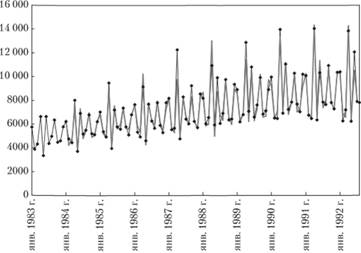
Рис. 8.14. Ряд № 2568 (сплошная линия с точками) и расчетные значения по ряду, полученные после всех преобразований (сплошная линия).
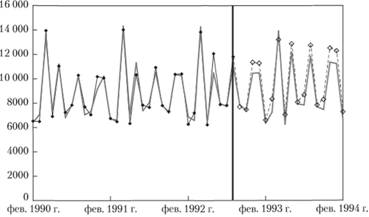
Рис. 8.15. Ряд № 2568 (сплошная линия с точками) и прогноз на 18 значений вперед (сплошная линия):
вертикальной линией показан момент времени, относительно которого делался прогноз Прогноз по полученной модели специально был вынесен на отдельный график, так как из-за большого числа наблюдений визуально отличить фактические значения от расчетных на рис. 8.15 было достаточно проблематично. Здесь мы видим, что примерно до июня 1993 г. прогноз был достаточно точным: повторяется как общая динамика, так и сезонные колебания. Однако уже после середины 1993 г. наблюдаются расхождения. Средняя относительная ошибка прогноза в результате этого оказалась равной sMAPE = 7,10%. Для сравнения, в М3 — Competitions точнее всего этот ряд смогла спрогнозировать модель ARARMA по десезонализированному ряду данных — для нее ошибка составила 4,29%. Модель Хольта — Уинтерса дала прогноз с ошибкой в 7,68%.
Стоит отметить, что из-за многочисленных преобразований ряда минимальные ошибки, допущенные на нижнем уровне (на уровне ряда в логарифмах и разностях), при переходе к исходному уровню могут значительно вырасти и привести к получению очень неточных прогнозов. Поэтому к таким процедурам стоит относиться осторожно.
В целом мы видим, что использование стандартной методики идентификации нестационарности и приведения процесса к стационарному виду сопряжено с рядом трудностей и требует подробного анализа ряда данных и получаемых результатов. Во многом все выполняемые исследователем действия зависят от его субъективной оценки — в каких-то случаях получаемые результаты могут приводить к совершенно разным выводам и решениям. Например, прологарифмировав ряд данных, можно попытаться привести его к стационарному виду путем взятия первых разностей и только потом пытаться избавиться от сезонности. Результаты в таком случае, скорее всего, были бы другими.
Можно заключить, что для получения более точных прогнозов с помощью этого подхода исследователь должен обладать большим опытом работы с временными рядами. Тем не менее предлагаемый стандартный подход в случае с нестационарными (обратимыми) процессами дает хорошие результаты и достаточно точные прогнозы.
- [1] Kwiatkowski Denis, Phillips Peter С. В., Schmidt Peter, Shin Yongcheol. Testing the null hypothesis of stationarity against the alternative of a unit root // Journal of Econometrics. 1992. Vol. 54. P. 159−178.
- [2] Kwiatkowski Denis, Phillips Peter С. В., Schmidt Peter, Shin Yongcheol. Testing the null hypothesis of stationarity against the alternative of a unit root //Journal of Econometrics. 1992. Vol. 54. P. 164.