Модели авторегрессии.
Методы социально-экономического прогнозирования. Т.2.

Конечно же, в таких условиях расчет весов? j для оценки дисперсии (9.39) на h шагов вперед — нетривиальная, хотя и выполнимая, задача. В наше время такие задачи могут автоматически выполнять различные статистические пакеты. Так, в пакете «forecast» статистической программы «R» реализованы все необходимые формулы для построения прогнозных интервалов. Единственной сложностью в нашем случае… Читать ещё >
Модели авторегрессии. Методы социально-экономического прогнозирования. Т.2. (реферат, курсовая, диплом, контрольная)
Принципы построения прогнозных интервалов для моделей авторегрессии аналогичны используемым в случае с моделями экспоненциального сглаживания. Здесь так же требуется оценить дисперсию модели, на основе которой далее строится интервальный прогноз. Покажем, как это делается, на простом примере модели AR (1), которая имеет вид 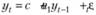
Если она лежит в основе генерирующего процесса, то и на наблюдении h прогноз по ней будет осуществляться следующим образом: 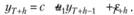
Выражая значение на наблюдении Т + h через предыдущие (в соответствии с выводами (8.16) в параграфе 8.1), получим.
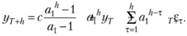 (9.30).
(9.30).
Сумма в правой части сформирована за счет учета всех ошибок на шагах между 1 и h, которая из-за рекурсивной формулы имеет вид.
 (9.31).
(9.31).
Оценим теперь дисперсию выражения (9.30). Поскольку первое слагаемое в правой части (9.30) представлено константами, его дисперсия будет равна нулю. В результате этого получим.
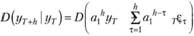 (9.32).
(9.32).
Первая составляющая в (9.32) не случайна, а задана конкретным значением, относительно которого мы строим прогноз. Поэтому дисперсия его будет равна нулю. В результате все, что нам нужно сделать, — это оценить дисперсию суммы (9.31):
 (9.33).
(9.33).
В связи с тем что после построения модели предполагается, что остатки не автокоррелируют, дисперсию суммы в (9.33) можно переписать как сумму дисперсий и заодно вынести коэффициенты за скобки:
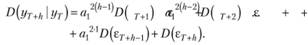 (9.34).
(9.34).
Учитывая предположение о том, что дисперсия в модели постоянна (т.е. в модели нет гетероскедастичности), мы можем дисперсии ошибок на разных шагах заменить общей дисперсией ошибки:
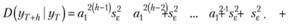
Теперь вынесем дисперсии за скобку, чтобы получить формулу оценки условной дисперсии у на h шагов вперед:
 (9.35).
(9.35).
Выражение в скобках можно переписать через формулу суммы элементов геометрической прогрессии:
 (9.36).
(9.36).
Дальнейшее построение прогнозных интервалов достаточно стандартно: предполагая, что остатки распределены нормально, мы строим интервал по формуле.
 (9.37).
(9.37).
Анализируя формулу (9.37), можно заметить, что в случае с построением нестационарной модели AR (1) (в которой а1? 1) доверительный интервал будет нелинейно увеличиваться, что не очень хорошо, так как в таком случае он будет излишне широким. Это одна из причин, почему модели ARMA должны быть стационарными.
В общем случае для того, чтобы оценить дисперсию произвольной модели ARMA, нам нужно ее представить в виде модели МА бесконечного порядка и оценить дисперсию ошибок с учетом коэффициентов. Мы уже обсуждали в параграфе 8.1, что любая модель AR может быть приведена к бесконечной МА. Именно такой переход от AR к М, А мы и проделали только что для модели AR (1). По аналогии с AR (1) можно выразить прогнозное значение yT+h в любой модели ARIMA в виде.
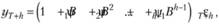 (9.38).
(9.38).
после чего рассчитать его условную дисперсию, которая с учетом введенных предположений относительно ошибок будет рассчитываться по формуле.
 (9.39).
(9.39).
Построим прогнозный интервал по модели ARIMA для ряда As 41. Результаты проведения теста на стационарность указывают на то, что исходный ряд данных нестационарен, а значит, нужно строить модель в разностях. Ряд в разностях и его коррелограммы приведены на рис. 9.9.
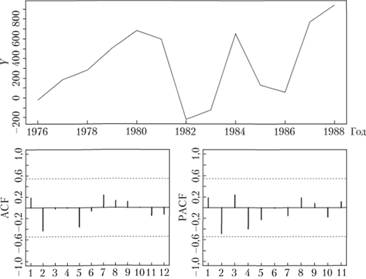
Рис. 9.9. Ряд данных № 41 в разностях (сверху) и его коррелограммы.
По коррелограммам видно, что в ряде в разностях значимых коэффициентов автокорреляции нет, а значит, описываться этот ряд будет просто константой, т. е. оптимальная модель ARIMA для этого ряда — модель ???(0,1,0) с дрейфом:
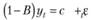 (9.40).
(9.40).
Если эту модель привести к линейному виду, получим.
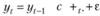
Прогноз по такой модели на h шагов получить достаточно просто:  , что, если обратить внимание, аналогично модели (5.26), рассмотренной нами в параграфе 5.2.
, что, если обратить внимание, аналогично модели (5.26), рассмотренной нами в параграфе 5.2.
Точечный и интервальный прогнозы по этой модели приведены на рис. 9.10.
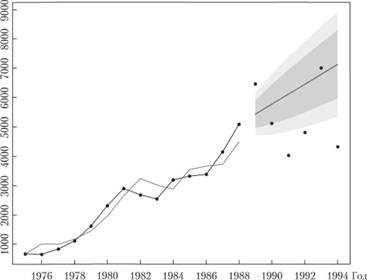
Рис. 9.10. Ряд данных № 41 (сплошная линия с точками), расчетные значения по модели (9.40) (сплошная линия), точечный и интервальный прогнозы по нему.
Как видим, из-за того, что тенденция на периоде прогнозирования сменилась, прогноз по модели ARIMA с дрейфом оказался неточным. Более того, в прогнозный интервал попало только два значения из шести.
Для моделей более высокого порядка методика построения прогнозных интервалов остается такой же, хотя и усложняется из-за расчета дисперсии на несколько шагов вперед.
Процесс построения интервалов для моделей SARIМА аналогичен описанному здесь для моделей ARIMA, но очевидно, что он еще сложнее, так как в этих моделях используется значительно больше коэффициентов, а значит, и выражения текущего значения через предыдущие становится более громоздким.
Построим прогнозный интервал для модели № 2568, идентификацией и оцениванием которой мы занимались в гл. 8. Напомним, что мы пришли к модели SARIMA (3,0,3)? (1,1,0)12:
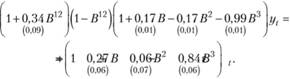 (9.41).
(9.41).
Если эту модель представить в линейном виде (т.е. раскрыть скобки и перегруппировать элементы), то она получается очень громоздкой и будет выглядеть следующим образом:
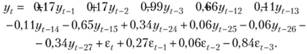
Конечно же, в таких условиях расчет весов? j для оценки дисперсии (9.39) на h шагов вперед — нетривиальная, хотя и выполнимая, задача. В наше время такие задачи могут автоматически выполнять различные статистические пакеты. Так, в пакете «forecast» статистической программы «R» реализованы все необходимые формулы для построения прогнозных интервалов. Единственной сложностью в нашем случае заключается перевод всех расчетных значений и интервалов в исходные величины (в связи с предварительным логарифмированием ряда данных). Данные по последним 1,5 годам и прогноз на 1,5 года вперед по модели (9.41) представлены на рис. 9.11.
На себя обращает внимание то, что, несмотря на не самую высокую точность точечного прогноза, в построенный прогнозный интервал попали практически все фактические значения (за исключением значения в январе 1994 г.). Можно заключить, что, поскольку модели.
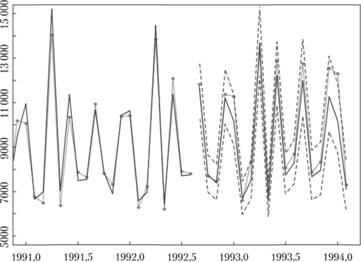
Рис. 9.11. Ряд данных № 2568 (сплошная линия с точками), точечный (сплошная линия) и интервальный (пунктирные линии) прогнозы по нему, полученные по модели SARIMA.
удалось в целом предугадать динамику ряда, прогнозный интервал оказался достаточно широким для того, чтобы в него попали практически все значения (17 / 18 — это около 94% всех прогнозных значений), но при этом и достаточно узким, чтобы сохранить смысл, хотя можно заметить, что нижнюю границу интервала можно было бы безболезненно поднять. Если обратиться к распределению остатков в модели, то мы увидим, что оно не только ненормально (что нарушает предпосылку для построения интервалов), но и имеет положительную асимметрию (рис. 9.12).
На рис. 9.12 на себя обращает внимание «выброс» после 0,20, исключение которого позволяет получить остатки ближе к нормальным (мы это уже обсуждали в параграфе 8.4). Наличие этого «выброса» так же вносит искажение в ширину прогнозного интервала. Однако если его убрать, то уменьшатся как нижняя, так и верхняя границы интервала, так как они рассчитываются по единой формуле, основанной на СКО, что в итоге не очень хорошо скажется на точности интервального прогноза.
Как видим, в данном случае учет «выброса» позволил получить достаточно точные прогнозные интервалы, что не вписывается в стандартную методологию и, возможно, стоит рассматривать как исключение из правил.
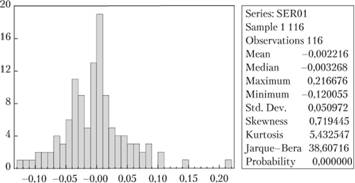
Рис. 9.12. Распределение остатков модели SARIMA для ряда № 2568 и основные его статистические характеристики.
Справа от графика остатков приведены основные статистические характеристики: Mean — средняя величина; Median — медиана; Maximum — максимальное значение; Minimum — минимальное значение; Std. Dev. - CKO; Skewness — асимметрия; Kurtosis — эксцесс. Последние два значения — это статистика теста Харке-Бера и соответствующая ей остаточная вероятность. Тест Харке-Бера проверяет гипотезу о нормальном распределении случайной величины по показателям эксцесса и асимметрии.
Отметим недостатки параметрических методов построения прогнозных интервалов:
1. при построении интервалов должны выполняться стандартные предположения относительно остатков:
a) математическое ожидание остатков должно быть равно нулю;
b) остатки должны быть распределены в соответствии с нормальным законом распределения;
c) остатки не должны автокоррелировать;
d) дисперсия остатков должна быть постоянной;
e) остатки не должны коррелировать с регрессорами.
- 2. Расчет дисперсии уt для построения прогнозных интервалов — нетривиальная процедура. В случае с более сложным моделями расчет дисперсии оказывается отдельной серьезной задачей.
- 3. Для получения точных прогнозных интервалов нужно получить точную оценку динамики ряда в будущем.
- 4. Для получения точных прогнозов в распоряжении исследователя должно быть много наблюдений.
Для решения некоторых из обозначенных недостатков можно обратиться к альтернативным методам построения прогнозных интервалов — к таким, как непараметрические и полупараметрические.