Принцип оптимальности и уравнения Веллмана

Управление Хк на k-м шаге, при котором достигается максимум в (11.8), обозначается X" k (sk ^) и называется условным оптимальным управлением на k-м шаге (в правую часть уравнения (11.8) следует вместо sk подставить выражение, найденное из уравнения состояния). Используя эти последовательности, можно найти решение задачи Д? при данных п и s0. По определению (см. параграф 11.1) — условный максимум… Читать ещё >
Принцип оптимальности и уравнения Веллмана (реферат, курсовая, диплом, контрольная)
Принцип оптимальности впервые был сформулирован Р. Веллманом в 1953 г. Каково бы ни было состояние истемы в результате какого-либо числа шагов, иа ближайшем шаге нужно выбирать управление так, чтобы оно в совокупности с оптимальным управлением на всех последующих шагах приводило к оптимальному выигрышу на всех оставшихся шагах, включая данный[1]. Беллманом четко были сформулированы и условия, при которых принцип верен. Основное требование — процесс управления должен быть без обратной связи, т. е. управление на данном шаге не должно оказывать влияния на предшествующие шаги.
Принцип оптимальности утверждает, что для любого процесса без обратной связи оптимальное управление таково, что оно является оптимальным для любого подпроцесса по отношению к исходному состоянию этого подпроцесса. Поэтому решение на каждом шаге оказывается наилучшим с точки зрения управления в целом. Если изобразить геометрически оптимальную траекторию в виде ломаной линии, то любая часть этой ломаной будет оптимальной траекторией относительно начала и конца.
Уравнения Веллмана. Вместо исходной задачи ДП (см. параграф 11.1) с фиксированным числом шагов п и начальным состоянием s0 рассмотрим последовательность задач, полагая последовательно п = 1,2,… при различных s — одношаговую, двухшаговую и т. д., — используя принцип оптимальности.
Введем ряд новых обозначений. Обозначения в ДП несут большую информационную нагрузку, поэтому очень важно их четко усвоить.
На каждом шаге любого состояния системы sk, решение Хк нужно выбирать «с оглядкой», так как этот выбор влияет на последующее состояние sk и дальнейший процесс управления, зависящий от sk. Это следует из принципа оптимальности.
Но есть один шаг — последний, который можно для любого состояния sn l планировать локально-оптимально, исходя только из соображений этого шага.
Рассмотрим п-й шаг: sn_, — состояние системы к началу и-го шага, sn=s- конечное состояние, Хп - управление на п-м шаге, а /и У") — целевая функция (выигрыш) и-ro шага.
Согласно принципу оптимальности Хп нужно выбирать так, чтобы для любых состояний sn, получить максимум[2] целевой функции на этом шаге.
Обозначим через 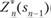 максимум целевой функции — показателя эффективности и-го шага при условии, что к началу последнего шага система S была в произвольном состоянии sn_, а на последнем шаге управление было оптимальным.
максимум целевой функции — показателя эффективности и-го шага при условии, что к началу последнего шага система S была в произвольном состоянии sn_, а на последнем шаге управление было оптимальным.
 называется условным максимумом целевой функции на п-м шаге. Очевидно, что.
называется условным максимумом целевой функции на п-м шаге. Очевидно, что.
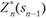 (11.5).
(11.5).
Максимизация ведется по всем допустимым управлениям хп.
Решение Хп, при котором достигается 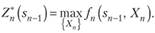 , также зависит от sn j и называется условным оптимальным управлением на п-м шаге. Оно обозначается через X*(swj).
, также зависит от sn j и называется условным оптимальным управлением на п-м шаге. Оно обозначается через X*(swj).
Решив одномерную задачу локальной оптимизации по уравнению (11.5), найдем для всех возможных состояний s, две функции: 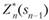
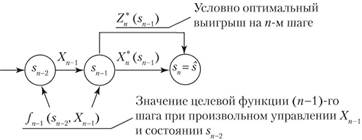
Рассмотрим теперь двухшаговую задачу: присоединим к п-му шагу (и-1)-й (рис. 11.2).
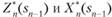
Рис. 11.2.
Для любых состояний sn 2, произвольных управлений Хп_ и оптимальном управлении па и-м шаге значение целевой функции на двух последних шагах равно.
 (11.6).
(11.6).
Согласно принципу оптимальности для любых sn2 решение нужно выбирать так, чтобы оно вместе с оптимальным управлением на последнем (и-м) шаге приводило бы к максимуму целевой функции на двух последних шагах. Следовательно, нужно найти максимум выражения (11.6) по всем допустимыми управлениям X? Максимум этой суммы зависит от s 2, обозначается через  и на зывается условным максимумом целевой функции при оптимальном управлении на двух последних шагах. Соответствующее управление Хп1 на (п — 1)-м шаге обозначается через
и на зывается условным максимумом целевой функции при оптимальном управлении на двух последних шагах. Соответствующее управление Хп1 на (п — 1)-м шаге обозначается через 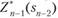 и называется условным оптимальным управлением на (п — 1)-м шаге.
и называется условным оптимальным управлением на (п — 1)-м шаге.
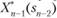 (11.7).
(11.7).
Следует обратить внимание на то, что выражение в фигурных скобках (11.7) зависит только от sn 2 и X"_v так как хи_, можно найти из уравнения состояний (11.2) при k = n-1
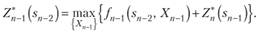
и подставить вместо хи_, в функцию 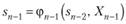
В результате максимизации только по одной переменной Хп_х согласно уравнению (11.7) вновь получаются две функции:
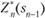
Далее рассматривается трехшаговая задача: к двум последним шагам присоединяется (п — 2)-й и т. д.
Обозначим через 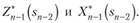 условный максимум целевой функции, полученный при оптимальном управлении на n-k + 1 шагах, начиная с k-го до конца, при условии, что к началу k-го шага система находилась в состоянии Фактически эта функция равна.
условный максимум целевой функции, полученный при оптимальном управлении на n-k + 1 шагах, начиная с k-го до конца, при условии, что к началу k-го шага система находилась в состоянии Фактически эта функция равна.

Тогда 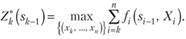
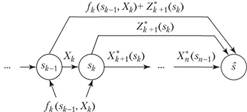
Целевая функция на п — к последних шагах (рис. 11.3) при произвольном управлении Хк на k-м шаге и оптимальном управлении на последующих п — k шагах равна 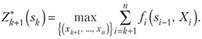
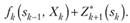
Рис. 11.3.
Согласно принципу оптимальности Хк выбирается из условия максимума этой суммы, т. е.
 (11.8)
(11.8)

Управление Хк на k-м шаге, при котором достигается максимум в (11.8), обозначается X" k(sk ^) и называется условным оптимальным управлением на k-м шаге (в правую часть уравнения (11.8) следует вместо sk подставить выражение 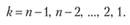 , найденное из уравнения состояния).
, найденное из уравнения состояния).
Уравнения (11.8) называют уравнениями Веллмана. Это рекуррентные соотношения, позволяющие найти предыдущее значение функции, зная последующие. Если из (11.5) найти 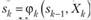 , то при к = п- из (11.8) можно определить, решив задачу максимизации для всех возможных значений sn_2, выражения для
, то при к = п- из (11.8) можно определить, решив задачу максимизации для всех возможных значений sn_2, выражения для 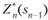 и соответствующее
и соответствующее 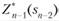
Далее, зная 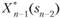 ?, находим, используя (11.8) и (11.2),.
?, находим, используя (11.8) и (11.2),.
уравнения состояний.
Процесс решения уравнений (11.5) и (11.8) называется условной оптимизацией[3].
В результате условной оптимизации получаются две последовательности:
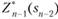
условные максимумы целевой функции на последнем, на двух последних, на … п-м шагах и.
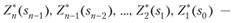
условные оптимальные управления на ?, п — 1,…, 1-м шагах.
Используя эти последовательности, можно найти решение задачи Д? при данных п и s0. По определению (см. параграф 11.1) 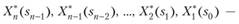 — условный максимум целевой функции за п шагов при условии, что к началу 1-го шага система была в состоянии s0, т. е.
— условный максимум целевой функции за п шагов при условии, что к началу 1-го шага система была в состоянии s0, т. е.
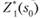 (11.9).
(11.9).
Далее следует использовать последовательность условных оптимальных управлений и уравнения состояний (11.2).
При фиксированном s0 получаем 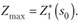 . Далее из уравнений (11.2) находим
. Далее из уравнений (11.2) находим 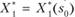 и подставляем это выражение в последовательность условных оптимальных управлений:
и подставляем это выражение в последовательность условных оптимальных управлений:
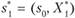 и т. д. по цепочке[4]:
и т. д. по цепочке[4]:
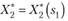
Получаем оптимальное решение задачи ДП:

(Стрелка > означает использование уравнений состояния, а стрелка => - последовательности условных оптимальных управлений.).
- [1] Формулировка принадлежит E. С. Вентцель [3] и немного отличается от предложенной Веллманом.
- [2] Ограничимся здесь задачей максимизации целевой функции.
- [3] Здесь описан способ решения задачи ДП, начинающийся с последнего шага («обратная схема»). Можно я-й и 1-й шаги поменять местами («прямая схема»).
- [4] Через s здесь обозначено состояние системы после А-го шага при условии, что на к-м шаге выбрано оптимальное управление.