Методы статистической обработки медико-биологических данных

Рис. 10.2. Варианты (а — в) выбора центров кластеров для одних и тех же данных, возникшие в результате изменения значения пороговой величины и положения исходной точки Простой алгоритм выявления кластеров обладает рядом недостатков, однако он позволяет просто и быстро получить приблизительные оценки основных характеристик заданного набора данных. Кроме того, этот алгоритм привлекателен… Читать ещё >
Методы статистической обработки медико-биологических данных (реферат, курсовая, диплом, контрольная)
В основе автоматизированных систем диагностики различных болезней лежат базы данных по показателям — МБС этих болезней, полученных в результате исследования здоровых и больных пациентов разного пола и возраста. Такие исследования называются эпидемиологическими.
В силу стохастичности патологических процессов физиологические показатели обладают значительной вариабельностью. Это привело к созданию разнообразных диагностических методов, алгоритмов и приборов, применение и изучение которых затруднено. В то же время стохастический характер МБС позволяет подойти к разработке систем обработки МБС как к системам передачи, преобразования и представления реализаций случайного процесса, формирования оценок статистических характеристик.
Случайной величиной х (к) называется функция множеств, определяемая в точках к выборочного пространства. Это действительное число, которое сопоставляется каждой выборочной точке.
Под выборочным пространством понимают возможные исходы измерений, представляющих собой множество точек.
Наиболее простая оценка случайной величины — ее среднее значение (первый момент). Если имеется выборка значений X = = (jci, JC2, …, хь Xji)y то по данному физиологическому показателю X среднее значение можно вычислить по формуле.
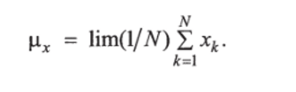
Например, общеизвестный физиологический показатель — нормальная температура Т внутренних полостей тела взрослого человека; имеет среднее значение рт = 36,6 °С. Повышенное или пониженное значение температуры Т, точнее, разность |pr — Т является первичным диагностическим показателем различных заболеваний.
Однако одного диагностического показателя для идентификации болезни недостаточно, в связи с чем используют набор, или вектор, физиологических показателей, например кластерный анализ.
Кластерный анализ. В настоящее время МБС регистрируют и анализируют с помощью многочисленных методов, которые условно можно разделить на три большие группы.
- 1. Визуальные (качественные). Врач наблюдает за МБС и на основании предыдущих наблюдений и знаний, полученных опытным путем, делает какие-либо заключения. Несмотря на низкую точность (со стороны математического описания), этот метод наиболее распространен и при наличии достаточного опыта врача дает высокие результаты.
- 2. Математические (количественные). При обработке МБС вычисляются его всевозможные параметры, на основании анализа которых врач ставит диагноз. С позиции математического описания, эти методы значительно более точны, однако требуют достаточно высокого уровня знаний врача в области теории вероятности и математической статистики, вследствие чего не всегда применяются.
Решение диагностической задачи (отнесение объекта к норме или патологии) связано с риском ложной тревоги (ошибка первого рода) или пропуска цели (ошибка второго рода). Для принятия обоснованного решения используют методы теории статистических решений, разработанные в радиолокации.
3. Смешанные методы представляют собой совокупность первых двух методов. К этой группе можно отнести методы кластерного и контурного анализа. Такое направление является наиболее перспективным, так как не требует значительных специфических знаний в математической области от врача. Анализируемая информация отображается графически, что наиболее привычно и удобно для врача. Использование цветовой гаммы в методах контурного и кластерного анализа особенно эффективно с физиологической точки восприятия.
Формально под задачей кластерного анализа заданного множества объектов понимается разбиение этого множества на непересекающиеся подмножества (кластеры) таким образом, чтобы элементы, относимые к одному подмножеству, отличались между собой в значительно меньшей степени, чем элементы из разных подмножеств.
В многомерном пространстве диагностических показателей кластеры нормы и болезней отображаются «облаками» точек, расположенных в разных частях этого пространства, различно удаленных от «нормального облака».
В геометрическом отношении кластеры представляют собой пространственные образы тех или иных заболеваний. Распознавание этих образов позволяет автоматизировать диагностику.
Общая теория распознавания образов — теоретический фундамент для решения основной задачи медико-технической диагностики. Эта теория занимается распознаванием образов любой природы (геометрических, звуковых, текстовых и т. п.) и представляет раздел теории управления (кибернетики). Медико-техническая диагностика разрабатывает алгоритмы распознавания применительно к задачам диагностики, которые обычно рассматривают как задачи классификации.
Алгоритмы распознавания в медико-технической диагностике основаны на диагностических моделях, которые устанавливают связь между состояниями биологического объекта и их отображениями — кластерами в пространстве МБС. Важная часть проблемы распознавания — правила принятия решений (решающие правила).
Классификация образов с помощью функций расстояния — одна из первых идей автоматического распознавания образов. Этот простой метод классификации весьма эффективен при решении таких задач, в которых классы характеризуются степенью изменчивости, ограниченной в разумных пределах. Далее подробно рассмотрены свойства и способы реализации классификаторов, основанных на критерии минимума расстояния.
Например, встречаются классы, которые можно охарактеризовать, выбрав по одному эталонному образу из класса. В этих случаях у образов любого из рассматриваемых классов существует тенденция к тесной группировке вокруг некоторого образа, являющегося типичным или репрезентативным для соответствующего класса. Подобные ситуации возникают, если степень изменчивости образов невелика, а помехи легко поддаются учету.
Типичным примером может служить считывание банковских чеков с помощью ЭВМ. Символы, помещаемые на чеках, сильно стилизованы и обычно наносятся магнитной печатной краской с тем, чтобы упростить процесс снятия показаний. В подобных ситуациях векторы образов (измерений) в каждом классе будут почти идентичны, поскольку одинаковые символы на всех практически используемых чеках идентичны. В таких условиях классификаторы, действующие по критерию минимума расстояния, могут оказаться чрезвычайно эффективным средством решения задачи классификации.
Иногда классы характеризуют выбором нескольких эталонных образов из класса. Допустим, что каждый класс можно описать не единственным, а несколькими эталонными образами, т. е. любой образ, принадлежащий классу А, проявляет тенденцию к группировке вокруг одного из эталонных образов Z|, Z2,…, ZN (,
где Ni — количество эталонных образов, определяющих г'-й класс. В этом случае необходимо воспользоваться другим классификатором.
Выбор функций расстояния в качестве инструмента классификации — естественное следствие того обстоятельства, что наиболее очевидный способ введения меры сходства для векторов образов, интерпретируемых нами так же, как и точки в евклидовом пространстве, — определение их близости.

Рис. 10.1. Образы, поддающиеся классификации с помощью понятия «близость».
В частности, изучая рис. 10.1, можно прийти к выводу о принадлежности вектора X классу С исключительно из тех соображений, что он находится ближе к векторам образа класса С, чем класса Сг.
Можно рассчитывать на получение удовлетворительных практических результатов при классификации образов с помощью функций расстояния только в тех случаях, когда классы образов обнаруживают тенденцию к проявлению кластеризационных свойств.
Интуитивным идеям необходимо придать общую форму и развить их на уровне соответствующей математической строгости.
В связи с тем что близость данного образа к образам некоторого класса используется в качестве критерия для его классификации, такой подход называют классификацией образов по критерию минимума расстояния. Поскольку кластеризационные свойства существенно влияют на работу автоматических классификаторов, основанных на критерии минимума расстояния, предложено несколько алгоритмов нахождения кластеров.
Необходимо отметить, что выявление кластеров во многих отношениях является «искусством» весьма эмпирическим. Качество работы определенного алгоритма зависит не только от характера анализируемых данных, но и от выбранной меры сходства образов и метода, применяемого для идентификации кластеров в системе данных. Соответствующие понятия, рассматриваемые ниже, обеспечивают основу для построения систем распознавания без учителя.
На формальном уровне для определения кластера на множестве данных необходимо в первую очередь ввести меру сходства, которая может быть положена в основу правила отнесения образов к области, характеризуемой некоторым центром кластера.
Ранее на примере температуры тела рассматривалось евклидово расстояние между образами гиг:

Эту характеристику используют как меру сходства соответствующих образов: чем меньше расстояние между ними, тем больше сходство. На этом понятии основаны алгоритмы, приведенные далее.
Однако меры сходства не исчерпываются расстояниями. В качестве примера можно привести неметрическую функцию сходства.

представляющую собой косинус угла, который образован векторами х и z, и достигающую максимума, когда их направления совпадают. Этой мерой сходства удобно пользоваться в тех случаях, когда кластеры обнаруживают тенденцию располагаться вдоль главных осей. Следует отметить, что использование данной меры связано с такими определенными ограничениями, как, например, достаточная удаленность кластеров друг от друга и от начала координат.
Проблема определения процедуры разбиения анализируемых данных на кластеры остается открытой и после выбора меры сходства образов. Критерий кластеризации может либо воспроизводить некие эвристические соображения, либо основываться на минимизации (или максимизации) какого-нибудь показателя качества.
При эвристическом подходе решающую роль играют интуиция и опыт. Такой подход предусматривает задание набора правил, которые обеспечивают использование выбранной меры сходства для отнесения образов к одному из кластеров. Евклидово расстояние хорошо приспособлено для подобного подхода, что связано с естественностью его интерпретации как меры близости. Поскольку близость двух образов является относительной мерой их подобия, обычно приходится вводить порог, чтобы установить приемлемые степени сходства для процесса отыскания кластеров.
Подход к кластеризации, предусматривающий использование показателя качества, связан с разработкой процедур, которые обеспечивают минимизацию или максимизацию выбранного показателя качества.
Один из наиболее популярных показателей — сумма квадратов отклонений:

где Nc/ — число кластеров; Sj — множество образов, относящихся к j-му кластеру; ntj — вектор выборочных средних значений для множества 5, «i( = (l/Nj)^x; Nj — число образов, входящих в.
xeSj
множество Sj.
Показатель качества (10.2) определяет общую сумму квадратов отклонений характеристик всех образов, входящих в некоторый кластер, от соответствующих средних значений по кластеру. Алгоритм, основанный на этом показателе качества, рассматривается далее.
Естественно, существуют другие показатели качества: среднее квадратов расстояний между образами в кластере; среднее квадратов расстояний между образами, входящими в разные кластеры; показатели, основанные на понятии матрицы рассеяния; минимум и максимум дисперсии и др.
Нередко применяют алгоритмы нахождения кластеров, основанные на совместном использовании эвристического подхода и показателя качества. Подобной комбинацией является алгоритм ИСОМАД (итеративный самоорганизующийся метод анализа данных, англ. Isodata — Iterative Self-Organizing Data Analysis Techniques).
В свете предыдущих замечаний о состоянии дел в области кластеризации это обстоятельство нельзя назвать неожиданным, так как качество отдельных алгоритмов нахождения кластеров в значительной степени определяется способностями его авторов по части извлечения полезной информации из анализируемых данных.
Алгоритмы, приведенные ниже, служат для этого хорошей иллюстрацией.
Простой алгоритм выявления кластеров. Пусть задано множество N образов {хь х2,…, xN} центр первого кластера г, — совпадает с любым из заданных образов, определена произвольная неотрицательная пороговая величина Г; для,-удобства можно считать, .ЧТО Z, = X/.
Вычисляется расстояние D2, между образом х2 и центром кластера z, по формуле (10.1). Если это расстояние больше значения пороговой величины 7D2, > Т, то учреждается новый центр кластера z2 = х2. В противном случае образ х2 включается в кластер, центром которого является Zj.
Пусть условие D2, > Т выполнено, т. е. z2 — центр нового кластера. На следующем шаге вычисляют расстояния D-ц и D32 от образа хз до центров кластеров zj и z2. Если оба расстояния оказываются больше пороговой величины Т, то учреждается новый центр кластера z3 = х3. В противном случае образ х3 зачисляется в тот кластер, чей центр к нему ближе.
Аналогично находят расстояния от каждого нового образа до известного центра кластера и сравнивают их с пороговой величиной. Если все эти расстояния превосходят значение пороговой величины Т, то устанавливается новый центр кластера. В противном случае образ зачисляется в кластер с самым близким к нему центром.
Результаты описанной процедуры определяются выбором первого центра кластера, порядком рассмотрения образов, значением пороговой величины Т и, конечно, геометрическими характеристиками данных. На рис. 10.2 приведены три варианта выбора центров кластеров для одних и тех же данных, возникшие в результате изменения только значения пороговой величины Т и положения исходной точки кластеризации.

Рис. 10.2. Варианты (а — в) выбора центров кластеров для одних и тех же данных, возникшие в результате изменения значения пороговой величины и положения исходной точки Простой алгоритм выявления кластеров обладает рядом недостатков, однако он позволяет просто и быстро получить приблизительные оценки основных характеристик заданного набора данных. Кроме того, этот алгоритм привлекателен с вычислительной точки зрения, так как для нахождения центров кластеров, соответствующих определенному значению пороговой величины Т, требуется только однократный просмотр выборки.
Чтобы хорошо понять геометрию распределения образов с помощью такой процедуры, проводят многочисленные эксперименты с различными значениями пороговой величины и исходными точками кластеризации. Поскольку изучаемые образы обычно имеют высокую размерность, визуальная интерпретация результатов исключается. В связи с этим необходимую информацию получают в основном с помощью сопоставления после каждого цикла просмотра данных расстояний, разделяющих центры кластеров, и количества образов, вошедших в разные кластеры.
К полезным характеристикам также относят ближайшую и наиболее удаленную от центра точку кластера и различие размеров отдельных кластеров. Информация после каждого цикла обработки данных может использоваться для коррекции выбора новых значения пороговой величины Т и исходной точки кластеризации в следующем цикле. С помощью подобной процедуры можно добиться полезных результатов в тех случаях, когда в данных имеются характерные «гнезда», которые достаточно хорошо разделяются при соответствующем выборе значения пороговой величины.
Алгоритм К внутригрупповых средних. Простой алгоритм выявления кластеров относится, в сущности, к эвристическому подходу. Алгоритм К внутригрупповых средних минимизирует показатель качества, определенный как сумма квадратов расстояний всех точек, которые входят в кластерную область, до центра кластера. Эта процедура, часто называемая алгоритмом, основанным на вычислении К внутригрупповых средних, состоит из следующих шагов.
Шаг 1. Выбор К исходных центров кластеров zi (l), z2(1), z*(1). Выбор проводят произвольно, в качестве исходных центров используют первые К результатов выборки из заданного множества образов.
Шаг 2. Распределение на к-м шаге итерации заданного множества образов по К кластерам:

где Sj (к) — множество образов, входящих в кластер с центром Zj{k). В случае равенства в (10.3) решение принимается произвольным образом.
Шаг 3. Определение на основе результатов шага 2 новых центров кластеров zj (k + 1 ), j =1,2,…, К, исходя из условия, что сумма квадратов расстояний между всеми образами, принадлежащими множеству Sj (к), и новым центром кластера должна быть минимальной.
Другими словами, новые центры кластеров Zj (k +1) выбираются таким образом, чтобы минимизировать показатель качества:
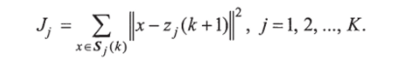
Центр Zj{k + 1), обеспечивающий минимизацию показателя качества, представляет собой выборочное среднее, определенное по множеству Sj{k). Следовательно, новые центры кластеров определяются следующим образом: 
где Nj — число выборочных образов, входящих в множество Sj (k).
Очевидно, что название алгоритма К внутригрупповых средних определяется способом, принятым для последовательной коррекции назначения центров кластеров.
Шаг 4. Равенство z/k + 1) = Zj{k) при j = 1,2,…, К является условием сходимости алгоритма, при его достижении выполнение алгоритма заканчивается. В противном случае алгоритм следует повторить начиная с шага 2.
Качество работы алгоритмов, основанных на вычислении К внутригрупповых средних, зависит от числа выбираемых центров кластеров, выбора исходных центров кластеров, последовательности осмотра образов и геометрических особенностей данных. Хотя для этого алгоритма общее доказательство сходимости неизвестно, приемлемые результаты можно ожидать в тех случаях, когда данные образуют характерные «гнезда», отстоящие друг от друга достаточно далеко. В большинстве случаев практическое применение этого алгоритма требует проведения экспериментов, связанных с выбором различных значений параметра К и исходного расположения центров кластеров.
Алгоритм ИСОМАД в принципе аналогичен алгоритму вычисления К внутригрупповых средних, поскольку и в нем центрами кластеров служат выборочные средние, определяемые итеративно. Отличие заключается в том, что алгоритм ИСОМАД обладает обширным набором вспомогательных эвристических процедур, встроенных в схему итерации. Следует постоянно иметь в виду определение «эвристические», поскольку ряд описываемых ниже шагов вошел в алгоритм в результате осмысления эмпирического опыта его использования.
До выполнения алгоритма необходимо задать набор Nd исходных центров кластеров z, z2,…, zN^. Этот набор, число элементов которого должно быть равно предписанному количеству кластеров, может быть получен выборкой образов из заданного множества данных.
При работе с набором {*1, дг2, …, л>}, составленным из Аэлементов, алгоритм ИСОМАД выполняет следующие основные шаги.
Шаг 1. Задание параметров, определяющих процесс кластеризации: К — необходимое число кластеров; 0,v — параметр, с которым сравнивается количество выборочных образов, вошедших в кластер; 0 $ - параметр, характеризующий среднеквадратичное отклонение (СКО); (c)с — параметр, характеризующий компактность; L — максимальное количество пар центров кластеров, которые можно объединить; / - допустимое число циклов итерации.
Шаг 2. Распределение заданных N образов по кластерам, соответствующим выбранным исходным центрам, по правилу xeSj (k),
если |дс —Zj I < ||лг — z, ||, i = 1, 2,…, Nd, i * j, применяемому ко всем образам х, вошедшим в выборку; через Sj обозначено подмножество выборочных образов, включенных в кластер с центром zj.
Шаг 3. Ликвидация подмножества образов, в состав которых входит менее количества (c)л— элементов, т. е. если для некоторого числа j выполняется условие Nj < (c)л-, то подмножество Sj исключается из рассмотрения и значение Nd уменьшается на 1.
Шаг 4. Каждый центр кластера z, j = 1,2, …, Nd, локализуется и корректируется посредством приравнивания его выборочному среднему, найденному по соответствующему подмножеству S/.

где Nj — число выборочных образов, вошедших в подмножество Sj.
Шаг 5. Вычисление среднего расстояния Dj между объектами, входящими в подмножество Sj, и соответствующим центром кластера по формуле.

Шаг б. Определение обобщенного среднего расстояния между объектами, находящимися в отдельных кластерах, и соответствующими центрами кластеров по формуле.
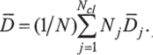
Шаг 7. Если текущий цикл итерации является последним, то задается (c)с = 0 и переходят к шагу 11. Если выполняется условие Nc/ < К/2, то осуществляется переход к шагу 8. Если текущий цикл итерации имеет четный порядковый номер или выполняется условие Mci > 2К, то переходят к шагу 11; в противном случае процесс итерации продолжается.
Шаг 8. Вычисление вектора CKO о; = (а1;, a2j, …, аиу) для каждого подмножества выборочных образов с помощью соотношения.

где п — размерность образа; xik — г-я компонента к-го образа в подмножестве Sj Zij — i-я компонента вектора, представляющего центр кластера zf, Nj — число выборочных образов, вышедших в подмножество Sj. Каждая компонента вектора СКО ст, характеризует СКО образа, входящего в подмножество Sj, по одной из главных осей координат.
Шаг 9. Определение максимальной компоненты стутах в каждом векторе СКО о, у =1,2,…, Ncl.
Шаг 10. Если для любой компоненты о,гаах, у = 1, 2, …, Nci, выполняются условия оугаах > (c)с, Dj > D и Nj > 2(@N +1) или.
Nci < К/2, то кластер с центром z, распадается на два новых кластера с центрами zj и zj, кластер с центром zy ликвидируется, а значение Nci увеличивается на 1. Для определения центра кластера zj к компоненте Zj, соответствующей максимальной компоненте вектора Oj, прибавляется заданная величина у/, центр кластера zj находится вычитанием величины уу из той же самой компоненты zy. В качестве величины у, можно выбрать некоторую долю значения максимальной компоненты ajmm, т. е. принять у; = koJnm, где 0 < Л < 1. При выборе величины у, следует руководствоваться в основном тем, чтобы ее значение было достаточно большим для определения разницы в расстояниях от произвольного образа до двух новых центров кластеров, но и достаточно малым, чтобы общая структура кластеризации существенно не изменилась.
Если распад происходит на этом шаге, то следует перейти к шагу 2; в противном случае необходимо продолжить выполнение алгоритма.
Шаг 11. Вычисление расстояния Dj между всеми парами центров кластеров: 
Шаг 12. Сравнение расстояния D:j с параметром 0С. Количество расстояний, значения которых оказались меньше значения параметра (c)с, ранжируется в порядке возрастания: [Dt ^ >^,2у2 ,•••> ^,LjL 1 >
причем D,, •, < … < D, i, a L — максимальное количество.
г >|Л ‘2J2 'LJL'
пар центров кластеров, которые можно объединить.
Шаг 13. Осуществление процедуры слияния кластеров. Каждое расстояние Dj ji вычислено для определенной пары кластеров с центрами zi; и zy;. К этим парам в последовательности, соответствующей увеличению расстояния между центрами, применяют процедуру слияния, которую осуществляют на основе следующего правила. Кластеры с центрами zt/ и Zj, i = 1,2,…, L, объединяются.
(при условии, что в текущем цикле итерации процедуру слияния не применяли ни к одному, ни к другому кластеру), причем новый центр кластера определяют по формуле.

Центры кластеров z. и. z^; ликвидируются, а значение Nd уменьшается на 1.
Следует отметить, что допускается только попарное слияние кластеров. В результате центр полученного кластера рассчитывается, исходя из позиций, занимаемых центрами объединяемых кластеров и взятых с весами, определяемыми количеством выборочных образов в соответствующем кластере.
Опыт показывает, что использование более сложных процедур слияния кластеров может привести к неудовлетворительным результатам. Описанная процедура обеспечивает выбор в качестве центра объединенного кластера точки, представляющей истинное среднее сливаемых подмножеств образов. Важно также иметь в виду, что, поскольку к каждому центру кластера процедуру слияния можно применить только один раз, реализация данного шага ни при каких обстоятельствах не может привести к получению количества L объединенных кластеров.
Шаг 14. Если текущий цикл итерации — последний, то выполнение алгоритма прекращается. В противном случае следует возвратиться либо к шагу 1, если по предписанию пользователя меняется какой-либо из параметров, определяющих процесс кластеризации, либо к шагу 2, если в очередном цикле итерации параметры процесса должны остаться неизменными. Завершением цикла итерации считается каждый переход к шагу 1 или 2.
Применение алгоритма ИСОМАД к набору данных умеренной сложности в принципе позволяет получить результаты только после проведения большого числа’экспериментов.
Выявление структуры данных может быть существенно ускорено благодаря эффективному использованию информации, собираемой после каждого цикла итерации. Эту информацию можно применять для коррекции параметров процесса кластеризации непосредственно при реализации алгоритма, для чего требуется доработка алгоритма ИСОМАД.
Требование нахождения однозначной (четкой) кластеризации элементов исследуемой области характеристических признаков заболевания является достаточно грубым и жестким. Особенно плохо это требование работает при решении таких слабо структурируемых задач, как дифференциальная диагностика ранних стадий заболеваний. Методы нечеткой кластеризации, основанные на аппарате нечетких множеств, ослабляют это требование в результате введения нечетких кластеров и соответствующих им функций принадлежности.