В3. 2. Линейная регрессия: вычисление

Рассмотрим, например, степенную функцию у = аа^у где х — входной, прогнозирующий признак, а у — выходной, прогнозируемый признак, тогда как коэффициенты, а и b неизвестны. Для каждого наблюдаемого объекта i = 1,…, N известны значения и уг Задача степенной регрессии может быть сформулирована как задача минимизации суммы квадратов или абсолютных значений ошибки по всем парам коэффициентов, а и Ь… Читать ещё >
В3. 2. Линейная регрессия: вычисление (реферат, курсовая, диплом, контрольная)
Регрессия — это способ отображения корреляции между х и у в виде линейной функции (т.е. на графике — прямой линии), у = slope • х + intercept, где slope и intercept константы; первая характеризует изменение у при изменении х на 1, а вторая — значение у при х = 0. Наилучшие возможные значения наклона и сдвига (те, которые минимизируют средний квадрат разницы между наблюдаемыми значениями у и найденными с помощью уравнения slope • х + intercept) задаются в МатЛабе, согласно формулам (2.4)—(2.6), следующим образом:
" rho=corr (x, y); % коэффициент корреляции;
" slope = rho*std (y)/std (x);% наклон;
" intercept = mean (y) — slope*mean (x);% сдвиг.
Здесь rho — коэффициент корреляции (3.5) между х и г/, для вычисления которого в МатЛаб существует функция «согг».
Проект 3.1. Линейная регрессия и бутстрэп
Зададим в МатЛабе данные из таблицы данных об ирисах в виде массива 150×4 в переменной iris. Выберем любые два признака и зададим данные о них в виде множества точек декартовой плоскости. Например, пусть длина лепестка — это х, а сто ширина — это у
" x=iris (, 3); % длина лепестка является 3-м столбцом массива iris;
" y=iris (, 4); % ширина лепестка в 4-м столбце iris.
Цветок ириса 1 (первая строка) задается точкой с координатами дг = 1,4 — длина лепестка и у — 0,3 — его ширина. Чтобы построить поле рассеяния данных признаков, используем команду.
" plot (x, y/k.').
% к соответствует черному цвету, — представлению объектов точками;
% ‘гр' соответствовало бы пентаграмме (пятиконечная звезда) красного цвета;
К сожалению, такое представление не совсем удачно, так как некоторые точки попали на границы поля (см. левую часть рис. 3.5). Чтобы отдалить границы, можно воспользоваться командой axis, например, так:
«plot (x, y,'k.'); d=axis; axis (1.2*d-.l); % здесь рамка увеличена на 20% и смещена вниз или так.
«plot (x, y,'k.'); axis ([-.5 8 -.5 3]); % здесь рамка задана значениями х (первая пара) и у Эти преобразования изображены посередине и справа па рис. 3.7. Для того чтобы отобразить все три графика в одном и том же окне, используем функцию «subplot» МатЛаба:
" subplot (1,3,1); plot (x, y/k.');
" subplot (l, 3,2); plot (x, y,'rp'); d=axis; axis (1.2*d-10);
" subplot (1,3,1); plot (x, y,'k.'); axis ([-.5 8 -.5 3]);
% здесь первые два аргумента функции subplot характеризуют количество рядов и % столбцов для размещения рисунков, а третий — номер конкретного окна в этой % структуре для размещения последующего plot.
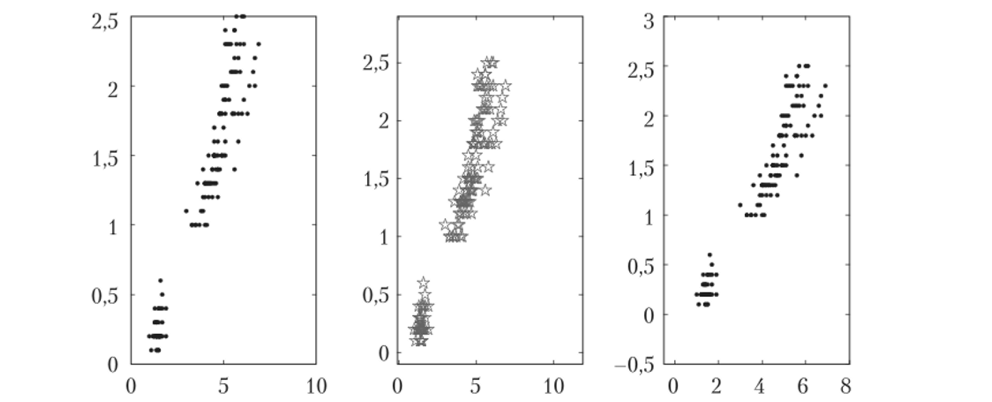
Рис. 3.7. Поле рассеяния признаков «Длина лепестка» и «Ширина лепестка»
с разными масштабами рамки
Поле рассеяния признаков длины и ширины лепестков ириса выглядит довольно обещающим с точки зрения наличия между ними линейной связи.
Уравнение линейной регрессии имеет вид: у = slope • х + intercept. Оценим его параметры в МатЛабе, используя формулы (3.4)—(3.6):
" сс= corrcoef (x, y); rho=c (l, 2); % порождаем rho=0.9629 «slope = rho*std (y)/std (x); % порождаем slope =0.4158;
" intercept = mean (y) — slope*mean (x);
% порождаем intercept = -0.3631;
Здесь использованы команды более старых версий МатЛаба, в которых функция согг отсутствует, зато есть функция corrcoef, порождающая матрицу коэффициентов корреляции для данного множества признаков. С функцией согг первая строка должна выглядеть следующим образом.
" rho=corr (x, y); % порождаем rho=0.9629.
Рис. 3.8. Поле рассеяния признаков, связанных между собой и нолем рассеяния непереводимой игрой слов английского языка
Percentage of scatter plots of joint distribution that look like joints
Таким образом, получаем уравнение линейной регрессии у = 0,416.г — 0,363. Величина наклона говорит о том, что каждый дополнительный сантиметр длины лепестка увеличивает его ширину в среднем на 0,416 см. Как обычно в анализе данных требуется определенная осторожность при формировании подобных заключений: строго говоря, они верны только в диапазонах реально наблюденных значений.
В целом уравнение регрессии объясняет р2 = 0,927 = 92,7% от общей дисперсии у. Это довольно высокий процент, как это нередко бывает в естественнонаучных исследованиях и практически никогда в социальных и гуманитарных науках.
Оценим надежность данного уравнения регрессии с помощью бутстрэпа. Это довольно популярный вычислительный эксперимент для оценки доверительных интервалов для результатов анализа данных, который был описан в проекте 2.3 на примере задачи валидации среднего значения. Бутстрэп основан на заранее заданном числе испытаний, например 5000. Каждое испытание состоит из следующих шагов:
(i) Из данной выборки случайно, с возвращением, Аграз выбирается по объекту. При этом некоторые объекты могут быть выбраны несколько раз, в то время как другие могут не попасть в испытание вообще (как показано выше в проекте 2.3, в среднем только 62% объектов попадают в выборку). N — это число объектов рассматриваемого множества, в нашем случае N= 150. Используем следующие команды МатЛаба:
" N=150;ra=ceil (N*rand (N, 5000));
% rand (N, 5000) задает 5000 столбцов из N случайных действительных чисел от 0 до 1.
% Умножение на N позволяет перейти к числам из интервала (0,N);
% операция ceil округляет выбранные числа до ближайших больших целых,.
% так что элементы матрицы га — это целые числа в интервале от 1 до 150.
Каждый столбец сгенерированной матрицы га имитирует отдельное испытание — случайный выбор с возвращением N объектов из заданной совокупности N объектов.
(и) Значения признаков на выбранных индексах — элементах матрицы га — определяются как:
«xt=x (ra);yt=y (ra);
% здесь х и у — входной и целевой признаки, соответственно.
При этом одни и те же объекты получают одни и те же значения признаков, (iii) Обращаемся к тому методу анализа данных, для которого производится валидация, в нашем случае это метод построения линейной регрессии. Для каждого испытания ?= 1,2, …, 5000 этим методом вычисляются коэффициент корреляции rho, наклон (slope) и сдвиг (intercept). К сожалению, при этом используются операции, не применимые к матрицам. Поэтому вычисления проводим в цикле по отдельным испытаниям — столбцам матрицы га:
" for k=l:5000; r=ra (, k); % выбираем к-е испытание xt=x®;yt=y®; rh (k)=corr (xt, yt);
sl (k)=rh (k)*std (yt)/std (xt); inte (k)=mean (yt)-sl (k)*mean (xt); end.
% результаты: rh (5000 значений коэффициента корреляции), si (5000 величин % наклона) и inte (5000 величин сдвига).
Теперь можно посчитать среднее и стандартное отклонение полученных 5000 значений параметра сдвига:
«msl=mean (sl);ssl= std (sl);
что дает msl = 0,4159 и ssl = 0,0098. Это означает, что исходная величина наклона 0.416 подтверждается процедурой бутстрэпа. По бутстрэп порождает разнообразие оценок среднего, позволяющее вычислить величину стандартного отклонения, 0,0098. Аналогичным образом вычисляются величины среднего и стандартного отклонения для сдвига и коэффициента корреляции: -0,363 / 0,0277 и 0,9629 / 0,0 соответственно.
Далее построим 30-бинные гистограммы для найденных 5000 значений наклона и сдвига (рис. 3.9):
" subplot (1,2,1); hist (sl, 30).
" subplot (l, 2,2); hist (inte, 30).
Функция subplot (1,2,1) создает ряд из двух окон для изображений, причем помещает гистограмму наклонов в первом из них (слева). Функция subplot (1,2,2) вносит гистограму сдвигов во второе окно.
Для получения 95%-ного доверительного интервала для наклона, сдвига и коэффициента корреляции можно использовать как метод с опорой, так и метод без опоры. Метод с опорой использует предположение о том, что выборка
5000 значений в процедуре bootstrap — случайная независимая выборка из Гауссова распределения. Параметры этого распределения определяются как среднее и стандартное отклонение выборочных значений
" msl=mean (sl); ssl=std (sl);
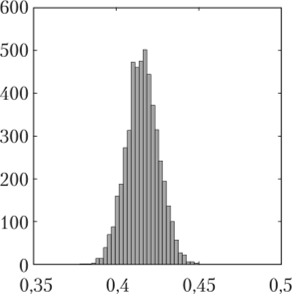
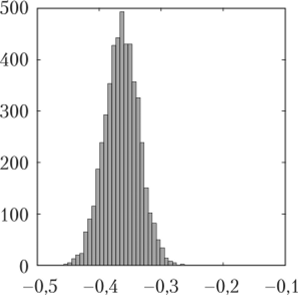
Рис. 3.9. 30-бинные гистограммы для наклона (слева) и сдвига (справа) линейной регрессии ширины лепестка по его длине, полученные в результате.
5000 испытаний бутстрапа.
Поскольку 95% площади Гауссового распределения попадает в интервал «среднее ± 1,96 • ст.о.», границы 95%-ного доверительного интервала для величины наклона получаются следующим образом.
" lbsl=msl — 1.96*ssl; rbsl=msl + 1.96*ssl;
Бсзопорныс вычисления определяются только по выборке. Нужно отсортировать все значения выборки, после чего 2,5%-ные квантили на краях отсортированного ряда определяются, отбросив по 125 крайних значений (125 = 2,5% от 5000): «ssl=sort (sl); lbn=ssl (126);rbn=ssl (4875);
Действительно, чтобы построить 95%-ный доверительный интервал, необходимо удалить из выборки 5% объектов по краям отсортированного ряда. Так как 5% от 5000 это 250, то, придерживаясь центрального интервала для отбора 95% значений, надо удалить из отсортированной выборки бутстрэпа первые 125 и последние 125 наблюдений. То есть величины ssl (126) и ssl (4875) и есть левая и правая границы доверительного интервата величины наклона по безопорному методу.
Аналогично вычисляются границы 95%-ного доверительного интервала, lbin и rbin, для полученного распределения величин сдвига. Все эти оценки представлены в табл. 3.3. Опорные и безопорные границы отличаются не слишком сильно.
Полученные результаты можно представить с помощью трех регрессионных прямых, обычной, а также двух вспомогательных, соответствующих нижним и верхним границам доверительных оценок, соответственно:
" yreg=slope*x+intercept; % регрессия по исходной выборке «yregleft=lbsl*x+lbin; % линия с с самыми левыми границами «yregright=rbsl*x+rbin; % линия с самыми правыми границами.
и затем отобразить все три на поле рассеяния данных (рис. 3.10):
" plot (x, y,'*kx, yreg,'k', x, yrcgleft,'r', x, yrcgright,'r').
% x, y,'*k' данные по студентам отображаются черными звездочками;
% x. yreg/k' график обычной регрессионной прямой задается черной линией % x, yregleft, Y and x, yregright, Y красный для граничных регрессий.
Таблица 33
Параметры распределений бутстрапа, а также границы 95%-ного доверительного интервала, полученные с использованием опоры и без
Среднее. | Стд. откл. | Границы с опорой. | Границы без опоры. | |||
Левая. | Правая. | Левая. | Правая. | |||
Наклон. | 0,4159. | 0,0098. | 0,3967. | 0,4351. | 0,3966. | 0,4351. |
Сдвиг. | — 0,3636. | 0,0277. | — 0,4178. | — 0,3093. | — 0,4185. | — 0,3092. |
Коэф. кор. | 0,9630. | 0,0051. | 0,9530. | 0,9730. | 0,9519. | 0,9721. |
Ограничивающие прямые оказались не слишком далеки от построенной линии регрессии, что, конечно же, объясняется очень высокой корреляцией рассматриваемых признаков.
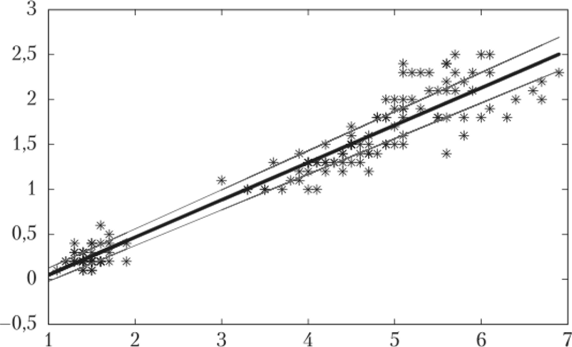
Рис. 3.10. Регрессия ширины лепестка ирисов (утолщенная прямая) относительно их длины, а также граничные прямые 95%-ного доверия
Проект 3.2. Нелинейная и линеаризованная регрессии: инспирированный природой алгоритм
Во многих случаях связь между признаками может оказаться нелинейной. Например, в экономике процессы, связанные с инфляцией, моделируются с помощью экспоненциальной функции. Подобный подход применяется и к процессам роста в биологии. Переменные, описывающие климатические условия, очевидно, имеют циклический «зима-лето» характер. Для многих социальных процессов характерен степенной закон.
Рассмотрим, например, степенную функцию у = аа^у где х — входной, прогнозирующий признак, а у — выходной, прогнозируемый признак, тогда как коэффициенты а и b неизвестны. Для каждого наблюдаемого объекта i = 1,…, N известны значения и уг Задача степенной регрессии может быть сформулирована как задача минимизации суммы квадратов или абсолютных значений ошибки по всем парам коэффициентов а и Ь. Заметим, что не существует метода, который сразу непосредственно приведет к глобально оптимальному решению задачи, поскольку минимизация суммы экспонент — сложная проблема. На практике уравнение степенной регрессии часто перезаписывают в виде уравнения линейной регрессии путем применения операции логарифмирования. При этом log (x) становится входным, a og (y) — выходным признаком: log (iy) = blog (jt) + log (tf). При такой линеаризации Xj и г/, заменяются на Vj = log (xf) и Zj = log (^), затем осуществляется линейная регрессия 2, — по vj} после чего найденные коэффициенты преобразуются в коэффициенты для исходной степенной функции. Этот способ часто дает высокое значение коэффициенту детерминации, поскольку логарифмирование сильно сглаживает данные.
Однако надо иметь в виду то, что найденные коэффициенты оптимальны для уравнения линейной регрессии, не обязательно означает, что при обратном переходе к степенной записи они также будут оптимальными. Данный проект посвящен иллюстрации этого утверждения.
Рассмотрим задачу минимизации суммы квадратов невязок согласно исходной степенной регрессии без ее линеаризации. Для ее решения применим подход, становящийся все более популярным — оптимизацию сложной функции методом, инспирированным природными процессами. Вместо получения единственного решения путем его последовательного улучшения, как это делается в классических методах оптимизации, этот подход использует целое множество, так называемую популяцию решений, которая итеративно эволюционирует от поколения к поколению согласно правилам, имитирующим какие-либо природные процессы. Обычно такие правила включают: а) небольшие целенаправленные случайные изменения от поколения к поколению; б) принципы отбора наилучших из найденных решений в так называемую элиту. После того как осуществлено заранее заданное число итераций, одно из элитных решений выдается как результат данной процедуры. Такой подход часто относят к направлению, называемому «вычислительный интеллект».
Перед тем как начать эволюционный процесс оптимизации, необходимо определить границы области допустимых решений так, чтобы ни один член популяции не выходил за ее пределы. Это гарантирует, что в процессе эволюции популяция не «взорвется» путем устремления решения в бесконечность. В данном случае предлагается следующее рассуждение. В условиях гипотезы степенной зависимости переменных у = ахР, для любых двух объектов i и j должны выполняться следующие равенства: 2f = ft ? v} + с и z}- ft • Vj + с, где с = log (tf), 2,= log(yj) и vx = log^). Тогда ft и с выражаются как: b = (2, — zj) / {vi — vj), с = (Vj • z} — v} • 2,) / (Vj — vj), что может привести к различным значениям b и с при различных i и j. Для тех i и j, для которых Vj — Vj * 0, обозначим минимальное и максимальное значения (Zj — Zj) / (Vj — Vj) через hrn и ЪМ соответственно, а минимальное и максимальное значения (Vj • Zj — Vj? 2,) / (vt — vj) через cm и cM. Допустимые ft и с должны находиться в этих пределах, что позволяет задать область допустимых решений неравенствами (bm, cm) < (ft, с) < (ftM, сМ). При этом оптимальные значения (ft, с) нс должны сильно отклоняться от средних значений определенных выше отношений, т. е. находиться ближе к центру данного прямоугольника, чем к его границам. Кроме того, вычисления пойдут гораздо быстрее, если мы ограничимся только теми парами для которых vjy v} и zv Zj не слишком близки к 0 из-за большой чувствительности логарифма в зоне 0. Все эти соображения учтены в программном коде ddr. m для МатЛаба, который можно найти в приложении.
Для определения правил перехода к новому поколению обозначим массив популяции размера 2р на текущей итерации через /, а через /' — массив популяции на следующей итерации. Переход от / к /' осуществляется в три этапа.
Во-первых, возьмем ряд средних значений по столбцам / и повторим его р раз в массиве mf размера р х 2. Затем сделаем случайный Гауссов сдвиг:
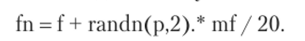
Здесь randn (p, 2) — массив размера р х 2 (псевдо)-случайных чисел из Гауссова распределения N (0, 1) с нулевым математическим ожиданием и единичной дисперсией. Символ «.*» обозначает операцию «умножения» матриц путем умножения друг на друга соответствующих элементов в матрицах, так что (af)*(bf) — это матрица, (ij)-vi элемент которой равен Щ*Ь^. Эта случайная матрица масштабируется долей двумерного вектора средних, повторенного р раз в р х 2 матрице mf/20, так что шаг покрывает около 5% от средних значений /.
Поскольку вышеопределенное изменение / допускает выход за допустимые границы, каждый «-элемент (первый столбец fri), больший, чем аМ, должен быть заменен на аМ, и каждый «-элемент, меньший, чем am, заменяется на am. Подобная замена производится и для 6-элементов. Обозначим результат через /г.
Теперь возьмем массив el, тоже размера р х 2, в строках которого — значения («, b) для элиты популяции, и определим популяцию следующего поколения как результат смешивания /г и el:

Такое смешивание сдвигает популяцию в направлении элиты, т. е. наилучшего найденного к данной итерации решения, на 30%. Эксперименты показали, что такой сдвиг хорошо работает в данной задаче.
Под элитой понимается та из имеющихся пар («, 6), на которой критерий достигает минимального значения. Элита пересчитывается на каждой итерации так же, как и в проекте 2.2. А именно, найдем значения критерия для всех пар («, Ь) нового поколения, выберем наилучшую и наихудшую пары («', Ь') и («», 6») и сравним их с элитой («, 6). Если («', 6') лучше, чем («, Ь), запомним («', 6') в качестве элиты («, Ь). Если («', //) и, тем более, («» , Ь») хуже, чем элита («, Ь), заменим («» , Ь») в текущей популяции на («, Ь).
Описанная процедура реализована на МатЛабе в программном коде nlr. m, который использует вышеописанную программу ddr. m (см. раздел А4 приложения).
Рассмотрим следующий эксперимент. Создадим входной признак л: как 50-мерный вектор случайных положительных величин от 0 до 10: х = 10 • rand (l, 50), а выходной признак определим как у = 2 • л:107. Добавим к нему нормальную ошибку из распределения 2 • JV (0, 1), математическое ожидание которого равно 0, а стандартное отклонение — 2, причем так, чтобы результат не мог стать меньше, чем 1 (это необходимо для того, чтобы логарифмирование в программе ddr. m не приводило к отрицательным числам), при помощи следующей строчки в коде МатЛаб:
«for й=1:50;уу=2*х (й)л1.07 +2*randn; y (ii)=max (yy, 1.01);end;
Признак у моделирует тренд 7%-ного роста, сильно зашумленного Гауссовой ошибкой.
При использовании обычной регрессионной модели линеаризации, т. е. при линейном отображении log (.r) на log (*/), находим b и а (переходом к экспоненте для найденного с) в llr. m: «= 3,0843 и b = 0,8011. При этом средняя ошибка квадрата у — ах!* равна 4,41, так что стандартная ошибка равна 2,10, т. е. приблизительно 21% от среднего значения у = 10,1168. Это говорит не только о том, что
ошибка высока, но и о том, что сам степенной закон оказался найден неверно. Заданная функция растет с темпом 7%, гак как b = 1,07 > 1, тогда как полученная функция убывает (b = 0,80 < 1).
В то же время минимизация средней ошибки квадрата разности у — ах1) для исходной модели с использованием кода nlr. m, где реализован вышсопрсдслснный эволюционный алгоритм, дает а = 2,0293 и b = 1,0760. При этом средний квадрат ошибки составляет 0,0003, а стандартное отклонение — 0,0180. В противоположность значениям, найденным для линеаризованной модели, полученные эволюционно значения параметров а и Ь довольно близки к тем, которые использовались при генерации данных.
Пример показывает, что процедура линеаризации может приводить к совершенно неправильным оценкам. Поэтому лучше ею не пользоваться. Более точные результаты получаются путем минимизации критерия исходной нелинеаризоваиной модели с помощью эволюционного алгоритма.
Задание 3.4. Моделирование роста инвестиций
Применим рассмотренный в проекте 3.2 подход к переменным х и г/, значения которых для 20 моментов времени представлены в табл. 3.4 (рис. 3.11).
Таблица ЗА
Величина инвестиционного фонда у в моменты времени х в промежутке 0,10—2,00
X | 0,10 | 0,20 | 0,30 | 0,40 | 0,50 | 0,60 | 0,70 | 0,80 | 0,90 | 1,00 |
У | 1,30 | 1,82 | 2,03 | 4,29 | 3,30 | 3,90 | 3,84 | 4,24 | 4,23 | 6,50 |
X | 1,10 | 1,20 | 1,30 | 1,40 | 1,50 | 1,60 | 1,70 | 1,80 | 1,90 | 2,00 |
У | 6,93 | 7,23 | 7,91 | 9,27 | 9,45 | 11,18 | 12,48 | 12,51 | 15,40 | 15,91 |
Переменная х отражает движение времени, а у — размеры фонда. Эти данные получены следующим образом. Компоненты х — это числа от 1 до 20, деленные на 10. Значения у получены в МатЛабе по формуле у = 2*exp (1.04*r) + 0.6*randn, где rantln — нормальная (Гауссова) случайная величина с математическим ожиданием 0 и дисперсией 1. Задача — определить тренд динамики фонда.
Для начала применим традиционный подход к определению темпа роста инвестиционного фонда в течение всего периода времени. Согласно этому подходу средний рост инвестиций выражается корнем 19-й степени (степенью 1/19) из отношения У2о/Уо = 15,91 / 1,30 = 12,238. Корень 19-й степени из этой величины равен 1,1409, что соответствует среднему годовому приросту в 14% — это гораздо выше, чем 4%, использованные при генерации данных. Традиционный подход в данном случае не очень-то применим.
Попытаемся теперь оценить связь между у и х, применяя процедуру линеаризации, рассмотренную в подпараграфе Ф3.2.3, где рассматривалась экспоненциальная зависимость у = аеЬх (в проекте 3.2 зависимость — степенная). Задача линейной регрессии для линеаризованной зависимости приводит к значениям коэффициентов b = 1,1969 и с = 0,4986. Переходя обратно к экспонентам, получаем значения для коэффициентов а = ес= 1,6465 и Ь = 1,1969. Легко заметить, что эти значения отличаются от истинных значений а = 2 и b = 1,04 приблизительно на 15—20%. Средняя величина квадрата ошибки Е = 0,700.
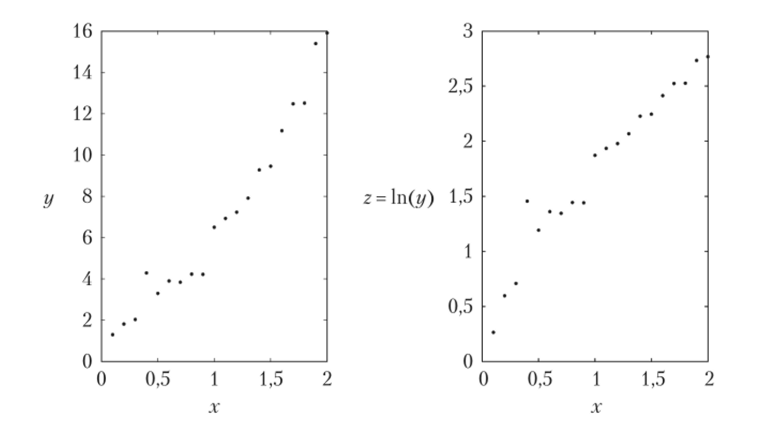
Рис. 3.11. График пар (л, у), где у — зашумленная экспоненциальная функция от х (слева), и график пар (лг, г), где z — ln (*/) (справа):
правый график выглядит несколько более линейным, хотя коэффициенты корреляции для данных полей рассеяния близки по своим значениям: 0,970 для левого графика и 0,973 для правого Теперь исходную нелинейную задачу проанализируем с применением процесса, инспирированного природой.
Программа nlr. m из приложения, реализующая эволюционный подход, описанный в проекте 3.2, модифицированная таким образом, что вычисляющая функцию строчка в подпрограмме delta заменена на yp (ii)=a*exp (b*x (ii));, приводит к а = 1,9908 и b = 1,0573. Отличие от истинных значений а = 2 и b = 1,04 составляет не более 2%. Средний квадрат ошибки Е = 0,373 гораздо ниже среднего квадрата ошибки, уравнения, найденного с помощью линеаризации.
Оба полученных решения отражены на рис. 3.12. Можно видеть, что результат линеаризации дает более крутую экспоненту, что особенно заметно в более поздние периоды времени.
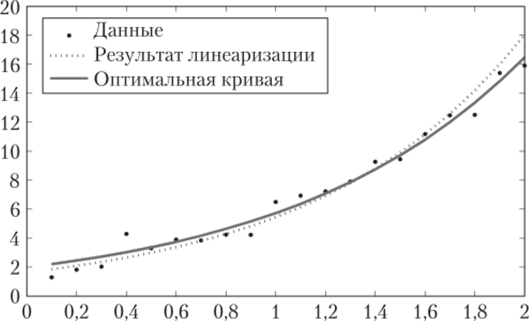
Рис. 3.12. Два экспоненциальных приближения для задания 3.4, представленные сплошной и пунктирной линиями соответственно.
Вопрос 3.7. Рассмотрим бинарный признак, значения которого известны для семи объектов: первые три из них принадлежат категории Л, остальные четыре — категории В. Зададим две фиктивные 1/0 (бинарные) переменные хА и хВ> так что хА = 1 для первых трех объектов и хА = 0 для остальных четырех, при этом хВ = 0 для первых трех и хВ = 1 для остальных объектов. Что можно сказать о коэффициенте корреляции между хА и хВ?
Ответ. Коэффициент корреляции хА и хВ равен -1, так как хА + хВ = 1 для всех объектов, так что хА = -хВ + 1.
Вопрос 3.8. Подумайте, как распространить алгоритм, инспирированный природой, на задачу определения коэффициентов линейной регрессии с нетрадиционным критерием, таким как средняя относительная ошибка, заданная формулой.
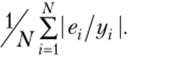
Задание 3.5. Неоднородность данных: корреляция между длиной и шириной чашелистика Обозначим через х — длину, а через у — ширину чашелистика для множества ирисов из табл. 1.3.
Поле рассеяния х и у представлено на рис. 3.13 слева. Это облако точек без видимого направления, напоминающее множество точек с нулевой корреляцией на рис. 3.2 слева. Однако в данном случае величина коэффициента не только мала, порядка -0,12, но еще и отрицательна, что довольно странно, поскольку интуитивно корреляция между длиной и шириной чашелистика должна быть положительной — ведь оба напрямую характеризуют размер!
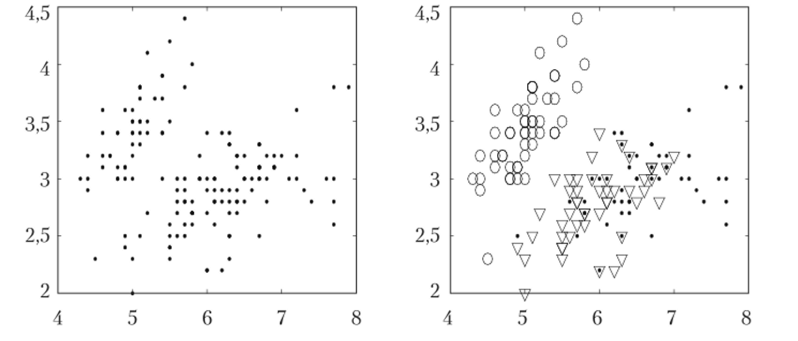
Рис. 3.13. Диаграмма разброса длины и ширины чашелистика, отражающая данные из табл. 1.3, в общем виде слева и с разбиением на таксоны справа. Таксон 1 представлен кружками, таксон 2 — треугольниками.
и таксон 3 — точками Чтобы понять, в чем причина такой низкой и даже отрицательной корреляции, необходимо учесть, что выборка не является однородной: множество Iris состоит из 50 образцов каждого из трех таксонов. Когда таксоны разделены (см. рис. 3.13 справа), положительная корреляция обнаруживается. Коэффициенты корреляции равны 0,74, 0,53 и 0,46 для объектов внутри таксонов 1, 2 и 3 соответственно. Это пример эффекта неоднородности выборки на результаты анализа данных.