Структуры хранения данных в памяти

Без специальных средств (программного обеспечения) увидеть содержимое двоичного файла в понятном для человека виде невозможно. При выводе на экран или печатающее устройство считываются и выводятся 8-разрядные битовые последовательности (байты), воспринимаемые как символы ASCII. В результате содержимое файла воспринимается как набор произвольных графических символов. Если байт не имеет… Читать ещё >
Структуры хранения данных в памяти (реферат, курсовая, диплом, контрольная)
В СВТ память делят на внутреннюю (используется для хранения и обработки данных текущих операций) и внешнюю (для долговременного хранения информации). К первой категории относят, например, оперативную память и кэш-память устройств. Внешнюю память представляют жесткие диски, оптические диски, флеш-память. Рассмотрим основные понятия и особенности, связанные с хранением структур данных во внутренней и внешней памяти.
Структурно оперативная память состоит из множества пронумерованных отдельных однобайтовых ячеек памяти. Номер каждой ячейки называется ее адресом. Максимально возможное количество непосредственно адресуемых ячеек памяти определяет адресное пространство. Адресное пространство зависит от количества к бит, отводимых для адреса (разрядности к адресной шины), т. е. адресное пространство равно 2к. Например, если память имеет 32-разрядные адреса, то ей соответствует адресное пространство из 232 Б или 4 ГБ. Последовательные байты имеют адреса 0, 1, 2 и т. д.
Поскольку данные составляют группу из п байтов (машинное слово), то память организуется так, что группы по п байтов могут записываться и считываться за одну операцию. Если, например, длина машинного слова равна 4 Б, то в одном слове может храниться одно 32-разрядное число в дополнительном коде или четыре символа ASCII, занимающих 8 бит каждый. В этом случае последовательные машинные слова будут иметь адреса 0,4,8,… (рис. 12.16). Соответственно, если длина слова равна 64 бит (8 Б), го слова начинаются по байтовым адресам 0,8,16,… .
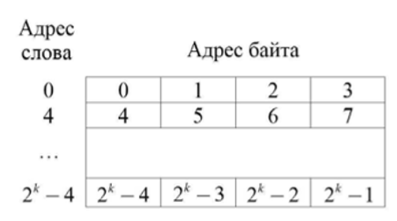
Рис. 12.16. Способ адресации байтов в оперативной памяти.
Числа в оперативной памяти обычно занимают целое машинное слово. Следовательно, чтобы обратиться к числу, необходимо указать адрес слова, в котором это число хранится. Аналогично для доступа к отдельному символу, хранящемуся в памяти, следует обратиться по адресу байта, который содержит код символа.
Текстовые сроки представляют собой массивы символов. Фактически они являются строками переменной длины. При обращении к такой строке необходимо указать адрес байта, в котором хранится первый символ. Последующие символы строки хранятся в последующих байтах. Длина строки может варьироваться, поэтому существуют специальные методы ее определения (задания):
- — используется специальный символ, означающий конец строки и являющийся последним ее символом;
- — используется отдельное поле (слово памяти), в котором хранится длина строки в байтах.
Рассмотрим более подробно организацию данных во внешней памяти.
Именованная совокупность однородных данных, записанная на внешнем носителе, называется файлом. Фактически файл является основной единицей хранения данных на внешнем запоминающем устройстве (ВЗУ), и именно с файлами производятся различные операции, такие как создание и удаление файла, чтение их содержимого, запись данных в них и т. д. Реализацию различных операций с файлами осуществляет файловая система — часть операционной системы, включающей комплекс системных программных средств.
Рассматривая организацию данных на внешнем носителе, различают логическое и физическое представление данных, логическую и физическую структуры файла.
Логическое представление определяет, как используются данные в прикладных программах, какие логические (причинно-следственные связи) существуют между отдельными элементами данных. Физическое представление определяет хранение данных на физическом носителе (во внешней памяти).
Логическое представление указывает на то, как данные используются в прикладной программе, т.с. отражают логику обработки. Физическое представление — это то, как данные хранятся на физическом носителе.
Понятию логической и физической структур файлов соответствует понятие записи данных.
Логическая запись представляет собой совокупность элементов данных, воспринимаемую и обрабатываемую как единое целое. С точки зрения пользователя прикладные программы работают именно с логическими записями. Обычно логические записи физически размещаются отдельно в рабочей области памяти. Совокупность логических записей образует логический файл. Обработка логических файлов осуществляется прикладными программными средствами.
Физическая запись представляет собой совокупность элементов данных, размещаемых на внешнем носителе, которая может быть считана (записана) одной командой ввода-вывода. Совокупность физических записей образует физический файл. Операции над такими файлами выполняются в рамках файловой системы.
Логическая и физическая организация данных могут быть не идентичны: одна физическая запись может содержать несколько логических (см. рис. 12.17). Возможна и другая ситуация, когда данные из нескольких различных физических источников (файлов, баз данных и пр.) объединяются в единую структуру, например, отчет. Кроме того, в физических записях могут использоваться специальные средства для оптимизации памяти (например, изменение порядка следования нолей или сжатие данных). Таким образом, логическая структура файла может варьироваться в зависимости от используемых программных средств, тогда как физическая всегда жестко связана с типом носителя и используемой файловой системой.

Рис. 12.17. Логические и физические записи.
Напомним, что линейные, древовидные и сетевые структуры являются логическими структурами данных. Их обработка и интерпретация целиком относится к прикладным программным средствам (приложениям). На внешнем носителе (ВЗУ) файл обычно представляется в виде неструктурированной последовательности данных. Для считывания или записи данных приложение формирует запросы к файловой системе (запросы ввода-вывода), которые являются общими для всех приложений в конкретной ОС. Поступивший в приложение поток байтов структурируется и интерпретируется в соответствии с заложенной в программу логикой. При этом следует помнить, что эти действия никак не связаны с реальным способом хранения данных на физическом носителе.
Обработка файлов на уровне файловой системы в виде последовательности нсструктурированных данных позволяет организовать обработку файла различными приложениями в соответствии с заложенными программными особенностями и реализованной логикой интерпретации данных. В большинстве современных ОС применяется именно такой способ хранения и обработки файлов во внешней памяти.
По отношению к способам доступа к логическим записям файла (или режимы обработки данных в файловых структурах) выделяют:
- 1. Последовательный доступ. В этом случае обработка (запись или чтение) логических записей осуществляются последовательно: из ВЗУ в оперативную память (и наоборот) в соответствии с порядком, в котором они размещены на носителе. Такой тип доступа применяется для неструктурированных файлов, длина и формат записей которых могут меняться, например, для текстовых файлов.
- 2. Произвольный (прямой) доступ. В этом случае обработка логических записей выполняется в соответствии с логикой и алгоритмами, реализованными в конкретной программе. Данные считываются и формируются записями фиксированной длины, к которым можно обратиться по номерам машинных слов. Подобный способ доступа применяется при обработке структурированных файлов, например, двоичных файлов, файлов реляционных баз данных, типизированных файлов языка Pascal.
Логическая организация файлов может быть различна. Современные ОС и используемые ими файловые системы поддерживают широко распространенные типы схем логической организации файлов или логической структуризации данных в файлах (рис. 12.18):
- — в виде записей фиксированной длины;
- — записей переменной длины;
- — индексной логической организации.

Рис. 12.18. Способы логической организации данных
На рис. 12.18, а приведена схема, согласно которой данные организованы в виде записей фиксированной длины. При этом доступ к г-й записи может быть осуществлен путем последовательного чтения первых (i — 1) записей либо, но адресу, вычисленному, но номеру г.
Пусть, например, L — фиксированная длина записи, тогда начальный адрес г-й записи по отношению к началу файла будет вычисляться как L i. Различные файлы в рамках одной файловой системы могут иметь различные длины L, но в пределах одного файла L остается неизменной.
Память, выделяемая для каждой из записей подобного типа, всегда имеет фиксированный размер, известный заранее. Данные в каждом поле жестко структурированы и обычно содержат ряд ограничений (см. параграф 1.12). Наиболее часто встречающимися ограничениями являются жестко заданный числовой формат и фиксированная длина строк.
На рис. 12.18, б показана схема последовательности записей переменной длины, согласно которой перед байтами содержания (данными, которые, собственно, и являются сутыо записи) располагаются байты длины, в которых хранится непосредственная длина содержания. Подобная схема применяется, когда записи имеют различную длину, например, текстовые строки. Еще одним распространенным случаем использования данной схемы является обработка файлов, содержащих переменное число нолей фиксированной длины.
Для обращения к требуемой записи необходимо последовательно обратиться (считать) все предыдущие записи. Так как длина каждой из них не является постоянной, то вычислить адрес нужной записи не представляется возможным, т. е. в данном случае нельзя применить более эффективный метод прямого доступа. Это один из существенных недостатков подобной логической организации файлов.
Для индексированных файлов, схема организации данных которых приведена на рис. 12.18, в, физическое расположение записи на носителе непосредственно связано с ее ключом. Для обработки файлов подобного типа строится специальная индексная таблица, в которой каждому значению ключа записи поставлен в соответствие адрес внешней памяти.
Индексная таблица не содержит данных, но в ней хранятся номера (индексы) записей исходного файла. Использование подобных таблиц позволяет обрабатывать файлы с нолями переменной длины и переменным количеством записей. Ведением индексных таблиц занимается файловая система.
Выделяют два основных формата файлов: двоичные и текстовые.
Двоичные файлы обычно состоят из последовательностей байт, сгруппированных в записи фиксированной длины. В файлах такого типа хранятся исполняемые программы и данные в двоичном (внутреннем, кодовом) представлении. В первом случае файл должен иметь определенную структуру, что в обязательном порядке проверяется ОС. Интерпретацией данных в двоичном представлении занимаются прикладные и системные программы.
Без специальных средств (программного обеспечения) увидеть содержимое двоичного файла в понятном для человека виде невозможно. При выводе на экран или печатающее устройство считываются и выводятся 8-разрядные битовые последовательности (байты), воспринимаемые как символы ASCII. В результате содержимое файла воспринимается как набор произвольных графических символов. Если байт не имеет графического представления, то символ вообще не отображается (не печатается), код никак нс воздействует на устройство вывода. Большинство собственных форматов файлов прикладных программ, например, офисных пакетов, имеют двоичный формат.
Текстовый файл или AS СП-файл, состоит из последовательностей символов, ко торые сгруппированы в строки переменной длины. Каждая такая строка является ло гической записью, состоящей из текстовых символов и заканчивающейся специальным маркером конца строки. Текстовым символом считается любой ASCII-символ. Их последовательность выводится на экран или печатающее устройство в понятном для человека виде. В виде текстовых файлов могут быть представлены исходные тексты программ на некотором алгоритмическом языке, таблицы, исходные данные, результаты и т. д.
В качестве маркера конца строки обычно выступает символ возврата каретки CR, за которым, возможно, следует символ перевода строки LF. Первый символ имеет ASCII-код 13, второй — 10. Выделение этих двух символов исторически обусловлено использованием печатных машинок для подготовки текстовых документов.
В современных программах символы CR и LF обычно объединяются в составной символ конца строки eoln (End Of LiNe). Завершается текстовый файл обычно символом конца файла SUB (ASCII-код равен 26). Более употребительное название данного символа EOF (End Of File). Указанные символы обычно являются невидимыми для пользователя при просмотре или печати, однако с помощью специальных программных средств они могут отображаться. Кроме eoln и EOF имеются и другие невидимые, но значимые символы, например, символ табуляции.
При размещении данных на внешних носителях выделяют следующие типы файловых структур данных:
- — последовательные (неиндексированные);
- — прямые (индексно-произвольные);
- — индексно-последовательн ые;
- — библиотечные.
В последовательных файловых структурах данных записи на внешнем носителе располагаются в соответствии с порядком их поступления. Произвольный доступ к записям невозможен: при обращении к некоторой записи необходимо последовательно считать в оперативную память вес записи. При подобной файловой структуре данных проявляются все недостатки последовательного доступа, например, длительный поиск записей, но некоторому признаку, особенно если они расположены в конце файла. Удаляемые записи физически исключаются путем создания нового файла. В качестве примера можно привести простые текстовые файлы и другие структурированные и неструктурированные наборы символьной информации.
В прялгых (индексно-произвольных) файлах расположение данных на внешнем носителе является произвольным: записи не упорядочены по ключу. Индексная таблица содержит полные (абсолютные) адреса записей. Очевидно, что при такой файловой структуре используется произвольный режим работы, хотя возможен и последовательный режим. При удалении записей происходит высвобождение памяти, адрес может повторно использоваться для новой записи, которая будет иметь тот же адрес, что и удаленная.
Одним из существенных недостатков индексно-произвольных файлов является ограничение на количество обрабатываемых ключевых полей: доступ к данным можно осуществлять только по одному ключевому полю. Так как в большинстве реальных задач приходится обрабатывать данные, но нескольким полям, составляющим ключ, то все преимущества прямого доступа к данным сводятся на нет.
Для повышения эффективности обработки данных применяют специальные методы. Один из них заключается в упорядочивании записей в порядке возрастания или убывания значений некоторого поля. Хранение упорядоченных записей осуществляется не в исходном, а в дополнительно создаваемом файле, называемом инвертированным. В случае обработки данных по нескольким полям создается соответствующее количество инвертированных файлов. Так как информация в исходном и инвертированном файлах различается только порядком записей, то для хранения каждого инвертированного файла требуется столько же дискового пространства, что и для исходного файла. Очевидно, что такой подход требует больших объемов внешней памяти, что, в конечном счете, снижает ценность применения индексно-произвольных файловых структур.
В индексно-последовательных (Jжилах для обработки используется совокупность исходного и одного (или нескольких) индексных файлов. Для ускорения обращения к данным записи файла упорядочиваются по ключу, при этом индекс обычно содержит ссылки нс на каждую запись, а на блоки записей. В индексной таблице адреса могут содержаться в усеченном виде, так как старшие знаки последовательных адресов будут совпадать. Такое сокращение при хранении адресов блоков записей позволяет существенно уменьшить размер индекса. При непосредственной обработке данных индексный файл обрабатывается в последовательном режиме, файл данных — в произвольном (при обращении к блокам данных) и последующем последовательном (при обращении к конкретной записи в указанной области).
При библиотечной организации (/хшлов записи объединяются в последовательно организованные разделы. Каждый раздел имеет собственное имя. В начале файла имеется специальный раздел, содержащий адреса начала разделов. При обращении к разделу используется прямой доступ, обращение к записям внутри раздела выполняется последовательно.
Контрольные вопросы
- 1. Что называется структурой данных? Приведите примеры структур данных, которые могут использоваться в экономических задачах.
- 2. Охарактеризуйте линейные типы данных. Приведите примеры данных, для хранения и обработки которых можно использовать линейные структуры.
- 3. Охарактеризуйте списковые структуры данных: список, очередь, стек.
- 4. В каких случаях целесообразно использовать списковые структуры?