Использование генетических алгоритмов в методе FCM

Сгенерируем на компьютере случайным образом 50 строк длины 7 • N-К, все элементы которых принимают значения 0 или 1. Декодируем по приведенной выше формуле каждую хромосому и вычисляем функцию пригодности каждой строки, которая будет совпадать со значением целевой функции при данных р к. Обозначим через рг (а,) пригодность 1-й строки. Тогда зо пригодность всей популяции составит? рг (а,). Так как… Читать ещё >
Использование генетических алгоритмов в методе FCM (реферат, курсовая, диплом, контрольная)
Для нахождения решения оптимизационной задачи нелинейного программирования в обобщенном методе FCM (в смысле использования произвольных метрик) целесообразно использовать генетические алгоритмы.
Важно!
Принципиальными особенностями генетических алгоритмов, позволяющими их применить в FCM-алгоритме, является отсутствие требований к дифференцируемости целевой функции и возможность отыскания глобальных экстремумов.
Отметим сначала, что стандартное нечеткое разбиение обладает следующим недостатком: объектам, удаленным от центров всех кластеров, интуитивно хочется присвоить маленькие значения степени принадлежности к каждому из кластеров, так как они имеют с ними мало общего. Тем не ме;
к
нее условие нормировки Z р k = 1, V/ = 1, N запрещает нам это сделать, ес;
ifr-i.
ли количество кластеров невелико. Для устранения этого недостатка предлагается использовать допустимое разбиение, которое требует лишь, чтобы каждый объект принадлежал хотя бы одному кластеру[1]. Тогда условие нор;
к _.
мировки можно ослабить до ограничения Z Рд > О, V/ = 1, N.
k= 1.
Покажем, как задача нечеткой кластеризации, представленная в виде оптимизационной модели, может быть решена с использованием генетических алгоритмов.
На практике для простоты будем предполагать, что все степени принадлежности принадлежат интервалу i.jk е [0,001; 1], /k = 1, К, V/ = 1, N. Значение, равное 0,001, можно интерпретировать в данных условиях как величину бесконечно малую. При необходимости границу можно передвинуть. Важно, что тогда все степени принадлежности будут положительными, не превосходящими 1. Следуя выдвинутым предположениям, мы выполним все требования задачи и перейдем к ее решению.
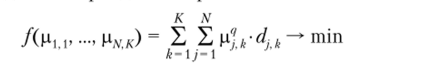
на гиперкубе, заданном вышеназванными ограничениями на р; к, где через dj к обозначено расстояние от элемента X' до центра k-oro кластера в соответствующей метрике.
Выберем для примера объем популяции М = 50 хромосом, зададим вероятность скрещивания рс = 0,25, вероятность мутации рт = 0,01. Данные параметры подбираются аналитиком из эвристических соображений и влияют в первую очередь на скорость сходимости алгоритма. Зададим точность, с которой мы хотим найти р; к, например, равной 0,01, т. е. точность, определяемую двумя знаками после запятой. Тогда для каждой переменной р; к диапазон ее изменения 1 — 0,001 = 0,999 должен быть разделен на 0,999−10″ = = 99,9 е (64; 128) равных отрезков. Следовательно, чтобы закодировать каждую степень принадлежности ру к в двоичном коде и удовлетворить требуемой точности, нам потребуется 7 бит (|log., 99,9| + 1 = 7; 128 = 2'). Тогда длина одной хромосомы должна составлять 7 • NК бит, где первые 7 бит будут кодировать р,, следующие 7 бит р, 2 и т. д.
Каждой части хромосомы — гену, отвечающему за значение р; к, будет сопоставляться соответствующее десятичное число по правилу.
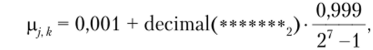
где звездочками закодированы соответствующие биты гена, «2» указывает на двоичное представление, а функция decimal возвращает десятичную форму двоичного числа.
Сгенерируем на компьютере случайным образом 50 строк длины 7 • N-К, все элементы которых принимают значения 0 или 1. Декодируем по приведенной выше формуле каждую хромосому и вычисляем функцию пригодности каждой строки, которая будет совпадать со значением целевой функции при данных р к. Обозначим через рг (а,) пригодность 1-й строки. Тогда зо пригодность всей популяции составит? рг (а,). Так как мы решаем задачу.
/-1.
на минимум, т. е. нас интересуют строчки с самой низкой пригодностью, то логично вероятность отбора для каждой из строк в следующую популяцию задать как.
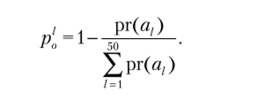
Осуществим селекцию, например, с помощью метода пропорциональной рулетки. Для этого вычислим кумулятивные вероятности для каждой.
t __.
строки по формуле q, = YjP'", t = 1, 50. Генерируем последовательность.
/-1.
из 50 равномерно распределенных на интервале [0; 11 случайных чисел е,. Для каждого из этих чисел в следующую популяцию отбираем строки (хромосомы) по правилу: выбираем строку t + 1, если qtt< <71+1. Получаем новую популяцию.
Теперь необходимо произвести скрещивание. Мы задали рс = 0,25, значит, в среднем, скрещиванию должны подвергнуться 25% исходных хромосом. Генерируем для каждой хромосомы в новой популяции случайное число г из диапазона [0; 1 ]. Если г < 0,25, то выбираем данную хромосому для скрещивания. Если количество отобранных строк окажется нечетным, то просто убираем произвольным образом одну из строк. Затем случайным образом разбиваем строки на пары. Для каждой пары случайным образом выбираем точку скрещивания. Для этого генерируем случайное натуральное число из интервала [1; I N K — 1J. Например, если для хромосом а, и, а было сгенерировано число k, то потомки а- и а формируются согласно правилу: а, получается конкатенацией первых к бит хромосомы at и последних 7 N Kk бит хромосомы аг Для aJt соответственно, наоборот: к первых бит хромосомы а; и последних 7 N Kk бит хромосомы аг
Наконец, производим мутацию. Мы задали рт = 0,01, значит ожидаем, что количество мутированных, т. е. подвергшихся операции инверсии, бит должно составить 1% от общего числа бит в популяции, т. е. 0,01 I N K- 50. И снова уже для каждого бита каждой хромосомы генерируем случайное число г из диапазона [0; 1]. Если г< 0,01, то бит подвергаем мутации.
Затем весь процесс итеративно повторяем, т. е. для новой популяции, получившейся в результате селекции, скрещивания и мутации, снова рассчитываем функции пригодности, проводим операции селекции, скрещивания и мутации. В качестве критерия остановки алгоритма следует выбрать либо выполнение определенного количества циклов, либо достижение заданного качества популяции (в нашем случае априорно задать его очень сложно), либо достижение определенного уровня сходимости (к примеру, разница между пригодностями популяции, но модулю не превосходит заданного уровня? > О)[2].
Важно!
Отметим, что в процессе построения алгоритма нас явно не интересовали ни дифференцируемость, ни сложность целевой функции (а значит, и выбранная метрика). Нам нужно было лишь уметь вычислять значение этой функции в конкретной точке, что не представляет труда.
Можно выделить следующие основные отличия генетических алгоритмов (ГЛ) от классических методов оптимизации[3].
- • Генетический алгоритм для поиска оптимума использует несколько точек одновременно, а не переходит от точки к точке. Это позволяет существенно снизить вероятность сходимости процесса поиска решения к локальным оптимумам.
- • Генетический алгоритм не использует никаких дополнительных предпосылок о виде целевой функции, достаточно вычислять лишь значение этой функции в конкретных точках.
- • Генетические алгоритмы используют и детерминированные правила для перехода от одних точек к другим, и вероятностные правила для порождения новых точек анализа.
- • Генетический алгоритм работает с кодами, интерпретация которых происходит лишь перед началом работы алгоритма и после его завершения.
В заключение отметим, что, если бы мы решили не отказываться от условия нормализации 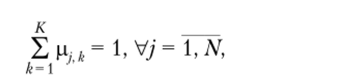
то в качестве целевой функции можно было бы выбрать, например,.
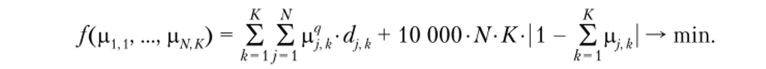
Такой выбор целевой функции обусловлен тем фактом, что после стандартизации переменных целевую функцию можно оценить сверху числом N K. Тогда для этой новой целевой функции оптимизация в первую очередь будет проводиться по второму слагаемому 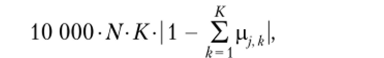
которое вносит существенно больший вклад и будет стремиться к нулю, а уже для тех u k, для которых второе слагаемое примет значения, близкие к нулю, будет минимизироваться исходная целевая функция.
Представленный алгоритм может быть реализован в математическом пакете МЛТГЛВ. Полученные результаты верификации позволяют сделать вывод о сходимости численного итерационного алгоритма решения задачи нечеткой кластеризации и возможности его использования в практической деятельности.