Непараметрический тест Краскала – Уоллиса

Оценить полученную статистику можно с помощью специально созданных таблиц .//-распределения, если число наблюдений и число групп оказываются небольшими. Если же число наблюдений в каждой группе больше пяти, распределение статистики Н может быть аппроксимировано распределением ?2 с k — 1 степенями свободы. Если при использовании метода однофакторного дисперсионного анализа возникают глубокие… Читать ещё >
Непараметрический тест Краскала – Уоллиса (реферат, курсовая, диплом, контрольная)
Если при использовании метода однофакторного дисперсионного анализа возникают глубокие и обоснованные сомнения в адекватности его применения (распределение полученных данных явно отличается от нормального, наблюдается сильная гетерогенность внутригрупповой дисперсии, а полученное значение.
F-статистики находится на границе уровней значимости), возможно, имеет смысл отказаться от использования параметрического критерия в пользу непараметрического. Наиболее известным и разработанным в теоретическом отношении непараметрическим методом для анализа таблиц с одним входом является критерий оценки контрастов Краскала — Уоллиса (В. J. Winer 128]). Этот тест является непараметрическим аналогом однофакторного дисперсионного анализа. Он может быть рекомендован, если результаты экспериментального исследования представлены в порядковой шкале.
Смысл теста Краскела — Уоллиса состоит в том, чтобы от исходных эмпирических данных перейти к их ранговым значениям. Дальнейшие манипуляции с вновь полученными данными практически не отличаются от процедур дисперсионного анализа. В результате по формуле (3.10) строится статистика.
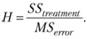 (3.10).
(3.10).
Оценить полученную статистику можно с помощью специально созданных таблиц .//-распределения, если число наблюдений и число групп оказываются небольшими. Если же число наблюдений в каждой группе больше пяти, распределение статистики Н может быть аппроксимировано распределением ?2 с k — 1 степенями свободы.
Поясним применение этого метода на примере задачи, которую мы рассматривали в параграфе 2.3. Напомним, там речь шла о двух группах испытуемых, оценивавших уровень понимания прочитанного им текста. Одна группа испытуемых получила от экспериментатора предварительную информацию, касающуюся содержания текста. Другая группа такой информации не получала.
Для начала переведем данные, представленные в табл. 2.2, в ранговые значения. Испытуемый, продемонстрировавший наиболее высокую степень понимания прочитанного ему текста, должен получить ранг 1. Следующий испытуемый, продемонстрировавший наиболее высокий уровень понимания текста после первого испытуемого, должен получить ранг 2 и т. д. В случае повторения результатов различных испытуемых необходимо провести дробление рангов. В итоге оказывается, что среднее значение рангов испытуемых, получивших предварительную инструкцию, равно 5,88, а среднее значение рангов испытуемых, не получивших такой инструкции, равно 13,11.
После известных нам вычислений находим значение SStreatment и MSerror По формуле (3.10) находим значение статистики Н. Оно оказывается равным 8,57. С помощью таблиц нетрудно установить, что вероятность получить такой (и даже больший) результат при условии, что мы имеем дело действительно с H-распределением, ничтожно мала — р < 0,01. Те же действия можно осуществить с помощью распределения хи-квадрат (см. приложение 2). Критическое значение ?2 для 1%-ного квантиля при одной степени свободы оказывается равным 6,63. Следовательно, необходимо принять альтернативную гипотезу и сделать вывод о том, что ранговые значения неравномерно распределились по двум экспериментальным группам. Учитывая, что за ранговыми значениями стоят реально полученные в эксперименте оценки уровня понимания прочитанного текста, делаем все тот же вывод о том, что испытуемые, получившие предварительную инструкцию, склонны оценивать предложенный им текст как более понятный.
Как видим, результаты двух различных методов однофакторного статистического анализа приводят к одним и тем же выводам. Однако такое случается не всегда. При переходе к рангам неминуемо теряется часть исходной информации. Сохраняется только информация о порядке, т. е. полученные данные начинают описываться более слабой шкалой. Если экспериментатор готов согласиться с такими потерями, он приобретает значительное преимущество, состоящее в том, что ему теперь не нужно делать никаких допущений относительно параметров распределения. Иногда, однако, полученные преимущества не могут компенсировать потерь. Напротив, в ряде случаев, имея результаты ранжирования, стоит подумать о том, чтобы представить их в более сильной шкале. Для этого ранги нужно трансформировать в 2-значения, осуществив нормализацию полученных данных. Если такая нормализация оказывается невозможной по содержательным критериям, выбор непараметрического теста представляется оптимальным решением.
В заключение следует отметить, что так же, как и однофакторный дисперсионный анализ, тест Краскела — Уолиса в первую очередь следует применять при сравнении нс двух, а нескольких выборок. В случае сравнения двух выборок предпочтительнее использовать аналог ?-теста Стьюдента — 17-статистику Манна — Уитни. Этот же тест следует использовать и при попарной непараметрической оценке контрастов.