Использование Miсrоsоft Оffiсе Ехсеl в компьютерной обработке данных

В заключение следует сказать несколько слов об инструментах, которыми пользуется специалист по статистике, либо исследователь, самостоятельно проводящий анализ данных. Давно ушли в прошлое ручные вычисления. Существующие на сегодняшний день статистические компьютерные программы позволяют проводить статистический анализ, не имея серьезной математической подготовки. Такие мощные системы как SРSS… Читать ещё >
Использование Miсrоsоft Оffiсе Ехсеl в компьютерной обработке данных (реферат, курсовая, диплом, контрольная)
Основные понятия режимов компьютерной обработки данных
ЭВМ — электронно-вычислительная машина.
Информационные системы — В широком смысле информационная система есть совокупность технического, программного и организационного обеспечения, В узком смысле информационной системой называют только подмножество компонентов ИС в широком смысле, включающее базы данных, СУБД и специализированные прикладные программы.
ПЭВМ — Персональный компьютер персональная ЭВМ — компьютер, предназначенный для личного использования, цена, размеры и возможности которого удовлетворяют запросам большого количества людей.
СОД — Система обработки данных.
Обработка данных — процесс выполнения последовательности операций над данными. Обработка данных может осуществляться в интерактивном и фоновом режимах.
ВЦ — вычислительный центр.
ВС — Вычислительная система СХД — система хранения данных.
ГВС, Глобальная вычислительная сеть — компьютерная сеть, охватывающая большие территории и включающая в себя десятки и сотни тысяч компьютеров.
Существуют различные режимы компьютерной обработки данных, зависящие в первую очередь от ЭВС, от режимных возможностей технических средств, требований к быстроте обработки сообщений.
Пакетный режим — Пакетный режим может пригодиться и при разработке особенно длинных запросов, а именно — многострочных команд или больших последовательностей команд, он позволяет эффективно использовать имеющиеся ресурсы. Пакетная обработка данных — организация выполнения нескольких программ в определенной последовательности с помощью команд операционной системы. Пакетная обработка организуется с помощью пакетных файлов, т. е. пользователь, собирая информацию, формирует её в пакеты в соответствии с признаками и задачами. После сбора информации происходит ее обработка и ввод. Этот режим используется, как правило, при централизованном способе обработки информации.
Интерактивный режим — Интерактивность понятие, которое раскрывает характер и степень взаимодействия между объектами. Используется в областях: теория информации, информатика и программирование, системы телекоммуникаций, социология, промышленный дизайн и других. Это принцип организации системы, при котором цель достигается информационным обменом элементов этой системы. При использовании интерактивный режим у пользователя появляется возможность воздействовать на процесс обработки данных.
Диалоговый режим — способ взаимодействия пользователя или оператора с ЭВМ, при котором происходит непосредственный и двухсторонний обмен информацией, командами или инструкциями между человеком и ЭВМ. Диалоговый режим подразумевает такую скорость обработки данных, которая не сказывается на технологии действий пользователя. Различают активные и пассивные диалоговые режимы. Этот режим требует определенного уровня технической оснащенности пользователя, т. е. наличие терминала или ПЭВМ, связанных с центральной вычислительной системой каналами связи.
Диалоговый режим. | |
Активный. | Пассивный. |
Активный диалог — режим взаимодействия пользователя и программной системы, который характеризуется равноправием его участников. Обычно для организации активного диалога используются директивные (командные) языки, или языки, близкие к естественным. | Пассивный диалог — режим взаимодействия пользователя и программной системы, инициатива ведения которого принадлежит программной системе. При этом программная система ведет за собой пользователя, требуя от него в точках ветвления вычислительного процесса дополнительную информацию, необходимую для принятия заложенных в алгоритм решений. В пассивном диалоге программная система обеспечивает пользователя информационными сообщениями и подсказками, облегчающими использование диалоговой системы. Запросы к пользователю строятся обычно либо в виде меню, либо в виде шаблонов. |
Режим разделения времени — предполагает способность системы выделять свои ресурсы группе пользователей поочередно. Вычислительная система настолько быстро обслуживает каждого пользователя, что создается впечатление одновременной работы нескольких пользователей. Такая возможность достигается за счет соответствующего программного обеспечения.
Режим реального масштаба времени — Реальное время — режим работы вычислительной системы, при котором время отклика на событие не превышает предопределенной величины. Обработка данных в реальном масштабе времени это обработка данных, протекающая с такой же скоростью что и моделируемые события. Как правило, этот режим используется при децентрализованной и распределенной обработке данных.
Регламентный режим — характеризуется определенностью во времени отдельных задач пользователя. К примеру, получение результатных сводок по окончании месяца, расчет ведомостей начисления зарплаты к определенным датам и т. д. Сроки решения устанавливаются заранее по регламенту в противоположность к произвольным запросам.
Режим телеобработки — Телеобработка (удаленная обработка) — режим обработки данных при взаимодействии пользователей с СОД через линии связи. Телеобработка рассматривается в качестве самостоятельного режима обработки данных по следующим причинам. Во-первых, удаленность пользователей от СОД и наличие между ними специфического средства передачи данных — линии связи — порождает необходимость в специальных действиях пользователей при организации доступа к системе и завершении сеанса работы. Во-вторых, наличие линий связи налагает ограничения на форму и время обмена данными между пользователями и СОД. Эти ограничения приводят к необходимости специальных способов организации данных и доступа к ним, что в свою очередь отражается на структуре прикладных программ, используемых в режиме телеобработки.
Режим телеобработки характеризуется, прежде всего, спецификой доступа пользователя к системе и системы к данным, передаваемым через удаленные терминалы, т. е. связан в первую очередь с организацией обработки данных внутри СОД. При этом пользователи могут работать в режимах пакетном, диалоговом или «запрос-ответ». Каждый из этих режимов характеризуется специфичным способом взаимодействия пользователей с системой и соответствующим временем ответа.
Однопрограммный и многопрограммный режимы — Однопрограммный режим. Из подготовленных заданий пользователей составляется пакет заданий. Процессор обслуживает программы пользователей строго в порядке их следования в пакете. Процесс выполнения очередной программы не прерывается до полного ее завершения. Только после этого процессор как ресурс отдается в монопольное владение следующей очередной программе.
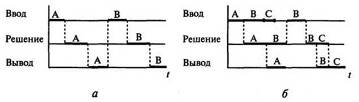
Однопрограммные режимы работы: а — режим непосредственного доступа; б — режим косвенного доступа Режим непосредственного доступа — пользователь получает ЭВМ в полное распоряжение: он сам готовит ЭВМ к работе, загружает задания, инициирует их, наблюдает за ходом решения и выводом результатов. По окончании работ одного пользователя все ресурсы ЭВМ передаются в распоряжение другого Режим косвенного доступа — пользователь не имеет прямого контакта с ЭВМ. Режим косвенного доступа имеет существенный недостаток. Он не позволяет полностью исключить случаи простоя процессора или непроизводительного его использования. Всякий раз, когда очередная программа, вызванная в процессор, предварительно не обеспечена данными, процессор вынужден простаивать. При этом резко снижается эффективность использования ЭВМ.
Многопрограммный режим — позволяет одновременно обслуживать несколько программ пользователей. Виды многопрограммной работы: классическое мультипрограммирование, режим разделения времени, режим реального времени и целый ряд производных от них. Режим классического мультипрограммирования, или пакетной обработки, применительно к однопроцессорным ЭВМ является основой для построения всех других видов многопрограммной работы. Режим имеет целью обеспечить минимальное время обработки пакета заданий и максимально загрузить процессор.
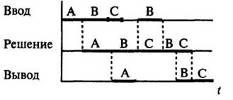
Многопрограммный режим пакетной обработки Однопрограммный и многопрограммный режимы характеризуют возможность системы работать одновременно по одной или нескольким программам.
Способы обработки данных делятся на централизованный, децентрализованный, распределительный и интегрированный способы.
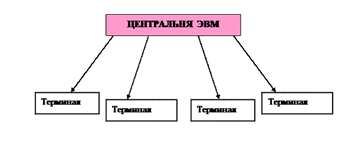
1. Централизованный — обрабатывает данные в одном месте, используя мощный компьютер и сложное программное обеспечение, установленное только на нем. Терминалы пользователей и автоматизированные устройства ввода первичных документов посылают данные на центральную ЭВМ для обработки, которая, если необходимо, предоставляет на терминалы обработанные данные. Преимуществами такого подхода являются меньшие затраты, лучший контроль за данными и программами (поскольку они находятся в одном месте), большая безопасность. Среди недостатков — большая сложность эксплуатации, высокие затраты на коммуникации (при большой удаленности терминалов).
учет школа информационный eхсеl.
- 2. Децентрализованный — системы, в которых данные хранятся и обрабатываются независимо в разных местах. При этом на каждом компьютере хранится какое-то подмножество всех данных компании, а часть данных находится в нескольких местах.
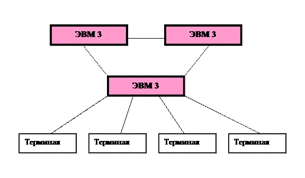
- 3. Распределительный — способ, при котором все подразделения компании, находящиеся в разных местах, соединены в единую сеть. Каждое из них имеет средства и возможности самостоятельно обрабатывать свои данные, поэтому пользуется преимуществами децентрализованной обработки. В то же время локальные компьютеры из разных мест могут посылать данные на центральную ЭВМ для подведения итогов и пользоваться общими данными компании, находящимися на ней, поэтому распределенная обработка дает и преимущества централизованной системы. В результате получается система, ориентированная как на нужды пользователей, так и на нужды руководства компании.
Преимущества распределенной обработки:
Поскольку пользователи контролируют каждую локальную систему, они имеют возможность подогнать ее под свои нужды и тем самым улучшить качество производимой информации.
Распределенная обработка данных позволяет быстрее и точнее вводить и корректировать данные, быстрее получать ответы на запросы.
Уменьшаются затраты на коммуникации, т.к. обработка производится локально.
Поскольку данные и другие ресурсы находятся в разных местах и частично дублируются, компьютеры как бы страхуют друг друга, уменьшая вероятность катастрофических потерь.
Каждая локальная система может рассматриваться как модуль общей системы, который может быть добавлен, модифицирован или удален из системы без необходимости изменять другие модули.
Недостатки распределительной обработки:
Распределенные системы более дороги, чем централизованные.
Намного усложняются задачи обслуживания оборудования, программного обеспечения, поддержания данных в необходимом состоянии.
Поскольку данные принадлежат разным подразделениям, неизбежно их дублирование со всеми вытекающими последствиями от использования такой информации, поэтому возникает необходимость специальных процедур по согласованию содержимого общих частей баз данных.
Поскольку неизбежно распределение полномочий и зон ответственности в такой системе, намного усложняется процесс документирования и контроля.
Разбросанность частей системы в пространстве и наличие коммуникаций снижают возможности обеспечения безопасности.
Уменьшается информационная насыщенность каждой отдельной локальной системы, поскольку вся информация, которая присуща централизованным системам, не может быть продублирована на всех компьютерах.
4. Интегрированный — способ обработки информации. Он предусматривает создание информационной модели управляемого объекта, то есть создание распределенной базы данных. Такой способ обеспечивает максимальное удобство для пользователя.
Системы хранения данных (СХД) обеспечивают эффективное хранение и оперативный доступ к информации. Благодаря достижениям в современной технологии, хранение больших объёмов информации стало довольно лёгкой задачей. Существует множество различных типов электронных устройств, используемых для хранения данных. Самые обычные способы хранения данных, используемые пользователями: — хранение на магнитных и оптических носителях; - на сменном носителе или, как говорят, флэш-памяти.
Самые популярные из магнитных устройств, хранения данных:
- — дискеты;
- — жёсткие диски;
- — ziр-накопитель;
- — цифровые аудиокассеты. Эти устройства имеют читающую / пишущую головку, для записи и дальнейшего чтения информации.
Система хранения данных содержит следующие подсистемы и компоненты: непосредственно устройства хранения (дисковые массивы, ленточные библиотеки), инфраструктуру доступа к устройствам хранения, подсистему резервного копирования и архивирования данных.
В случае отдельного ПК под системой хранения данных можно понимать внутренний жесткий диск или систему дисков (RАID массив). Если же речь заходит о системах хранения данных разного уровня предприятий, то традиционно можно выделить три технологии организации хранения данных:
- · Dirесt Аttасhеd Stоrаgе (DАS);
- · Nеtwоrk Аttасh Stоrаgе (NАS);
- · Stоrаgе Аrеа Nеtwоrk (SАN)
Устройства DАS (Dirесt Аttасhеd Stоrаgе) — решение, когда устройство для хранения данных подключено непосредственно к серверу, или к рабочей станции, как правило, через интерфейс по протоколу SАS.
Основные преимущества и недостатки создания хранилищ данных на основе сети DАS:
Плюсы:
- · Достаточно низкая стоимость. По сути эта СХД представляет собой дисковую корзину с жесткими дисками, вынесенную за пределы сервера.
- · Простота развертывания и администрирования.
- · Высокая скорость обмена между дисковым массивом и сервером.
Минусы:
- · Низкая надежность. При выходе из строя сервера, к которому подключено данное хранилище, данные перестают быть доступными.
- · Низкая степень консолидации ресурсов — вся ёмкость доступна одному или двум серверам, что снижает гибкость распределения данных между серверами. В результате необходимо закупать либо больше внутренних жестких дисков, либо ставить дополнительные дисковые полки для других серверных систем
- · Низкая утилизация ресурсов.
Устройства NАS (Nеtwоrk Аttасhеd Stоrаgе) — отдельно стоящая интегрированная дисковая система, посути, NАS-сервер, со своей специализированной ОС и набором полезных функций быстрого запуска системы и обеспечения доступа к файлам. Система подключается к обычной компьютерной сети (ЛВС), и являющаяся быстрым решением проблемы нехватки свободного дискового пространства, доступного для пользователей данной сети.
Основные преимущества и недостатки создания хранилищ данных на основе сети N АS:
Плюсы:
- · Дешевизна и доступность его ресурсов не только для отдельных серверов, но и для любых компьютеров организации.
- · Простота коллективного использования ресурсов.
- · Простота развертывания и администрирования
- · Универсальность для клиентов (один сервер может обслуживать клиентов MS, Nоvеll, Mас, Uniх)
Минусы:
- · Доступ к информации через протоколы «сетевых файловых систем» зачастую медленнее, чем как к локальному диску.
- · Большинство недорогих NАS-серверов не позволяют обеспечить скоростной и гибкий метод доступа к данным на уровне блоков, присущих SАN системам, а не на уровне файлов.
Stоrаgе Аrеа Nеtwоrk (SАN) -это специальная выделенная сеть, объединяющая устройства хранения данных с серверами приложений, обычно строится на основе протокола Fibrе Сhаnnеl или протокола iSСSI.
Основные преимущества и недостатки создания хранилищ данных на основе сети SАN:
Плюсы:
- · Высокая надёжность доступа к данным, находящимся на внешних системах хранения. Независимость топологии SАN от используемых СХД и серверов.
- · Централизованное хранение данных (надёжность, безопасность).
- · Удобное централизованное управление коммутацией и данными.
- · Перенос интенсивного трафика ввода-вывода в отдельную сеть, разгружая LАN.
- · Высокое быстродействие и низкая латентность.
- · Масштабируемость и гибкость логической структуры SАN
- · Возможность организации резервных, удаленных СХД и удаленной системы бэкапа и восстановления данных.
- · Возможность строить отказоустойчивые кластерные решения без дополнительных затрат на базе имеющейся SАN.
Минусы:
- · Более высокая стоимость
- · Сложность в настройке FС-систем
- · Необходимость сертификации специалистов по FС-сетям (iSСSI является более простым протоколом)
- · Более жесткие требования к совместимости и валидации компонентов.
- · Появление в силу дороговизны DАS-" островов" в сетях на базе FС-протокола, когда на предприятиях появляются одиночные серверы с внутренним дисковым пространством, NАS-серверы или DАS-системы в силу нехватки бюджета.
Обработка информации в современной информатике выполняется компьютером и часто включает хранение данных с использованием внешней памяти. Быстрый рост объемов информационных ресурсов требует принципиально новых подходов к хранению и обработке данных. Обработка информации выполняет определенные цели и задачи.
Типичными целями обработки данных является собрать всю доступную информацию, представленную в данных различной природы; представить существенную информацию в виде, наиболее удобном для восприятия пользователя. Эти цели, в свою очередь, приводят к постановке задач обработки данных После завершения любого научного исследования, фундаментального или экспериментального, производится статистический анализ полученных данных. Чтобы статистический анализ был успешно проведен и позволил решить поставленные задачи, исследование должно быть грамотно спланировано. Следовательно, без понимания основ статистики невозможно планирование и обработка результатов научного эксперимента. Тем не менее, медицинское образование не дает не только знания статистики, но даже основ высшей математики. Поэтому очень часто можно столкнуться с мнением, что вопросами статобработки в биомедицинских исследованиях должен заниматься только специалист по статистике, а врачу-исследователю следует сосредоточиться на медицинских вопросах своей научной работы. Подобное разделение труда, подразумевающее помощь в анализе данных, вполне оправдано. Однако понимание принципов статистики необходимо хотя бы для того, чтобы избежать некорректной постановки задачи перед специалистом, общение с которым до начала исследования является в такой же степени важным, как и на этапе обработки данных.
Прежде чем говорить об основах статистического анализа, следует прояснить смысл термина «статистика». Существует множество определений, но наиболее полным и лаконичным является, на наш взгляд, определение статистики как «науки о сборе, представлении и анализе данных». В свою очередь, использование статистики в приложении к живому миру называют «биометрией» или «биостатистикой» .
Следует заметить, что очень часто статистику сводят только к обработке экспериментальных данных, не обращая внимания на этап их получения. Однако статистические знания необходимы уже во время планирования эксперимента, чтобы полученные в ходе него показатели могли дать исследователю достоверную информацию. Поэтому, можно сказать, что статистический анализ результатов эксперимента начинается еще до начала исследования.
Уже на этапе разработки плана исследователь должен четко представлять себе, какого типа переменные будут в его работе. Все переменные можно разделить на два класса: качественные и количественные. То, какой диапазон может принимать переменная, зависит от шкалы измерений.
Можно выделить четыре основных шкалы:
- 1. номинальную.
- 2. ординальную;
- 3. интервальную;
- 4. рациональную (шкалу отношений).
В номинальной шкале (шкале «названий») присутствуют лишь условные обозначения для описания некоторых классов объектов, например, «пол» или «профессия пациента». Номинальная шкала подразумевает, что переменная будет принимать значения, количественные взаимоотношения между которыми определить невозможно. Так, невозможно установить математические отношения между мужским и женским полом. Условные числовые обозначения (женщины — 0, мужчины — 1, либо наоборот) даются абсолютно произвольно и предназначены только для компьютерной обработки. Номинальная шкала является качественной в чистом виде, отдельные категории в этой шкале выражают частотами (количество или доля наблюдений, проценты).
Ординальная (порядковая) шкала предусматривает, что отдельные категории в ней могут выстраиваться по возрастанию или убыванию. В медицинской статистике классическим примером порядковой шкалы является градация степеней тяжести заболевания. В данном случае мы можем выстроить тяжесть по возрастанию, но все еще не имеем возможности задать количественные взаимоотношения, т. е. дистанция между значениями, измеренными в ординальной шкале, неизвестна или не имеет значения. Установить порядок следования значений переменной «степень тяжести» легко, но при этом невозможно определить, во сколько раз тяжелое состояние отличается от состояния средней тяжести.
Ординальная шкала относится к полуколичественным типам данных, и ее градации можно описывать как частотами (как в качественной шкале), так и мерами центральных значений, на чем мы остановимся ниже.
Интервальная и рациональная шкалы относятся к чисто количественным типам данных. В интервальной шкале мы уже можем определить, насколько одно значение переменной отличается от другого. Так, повышение температуры тела на 1 градус Цельсия всегда означает увеличение выделяемой теплоты на фиксированное количество единиц. Однако в интервальной шкале есть и положительные и отрицательные величины (нет абсолютного нуля). В связи с этим невозможно сказать, что 20 градусов Цельсия — это в два раза теплее, чем 10. Мы можем лишь констатировать, что 20 градусов настолько же теплее 10, как 30 — теплее 20.
Рациональная шкала (шкала отношений) имеет одну точку отсчета и только положительные значения. В медицине большинство рациональных шкал — это концентрации. Например, уровень глюкозы 10 ммоль/л — это в два раза большая концентрация по сравнению с 5 ммоль/л. Для температуры рациональной шкалой является шкала Кельвина, где есть абсолютный ноль (отсутствие тепла).
Следует добавить, что любая количественная переменная может быть непрерывной, как в случае измерения температуры тела (это непрерывная интервальная шкала), или же дискретной, если мы считаем количество клеток крови или потомство лабораторных животных (это дискретная рациональная шкала).
Указанные различия имеют решающее значение для выбора методов статистического анализа результатов эксперимента. Так, для номинальных данных применим критерий «хи-квадрат», а известный тест Стьюдента требует, чтобы переменная (интервальная либо рациональная) была непрерывной.
После того как будет решен вопрос о типе переменной, следует заняться формированием выборки. Выборка — это небольшая группа объектов определенного класса (в медицине — популяция). Для получения абсолютно точных данных нужно исследовать все объекты данного класса, однако, из практических (зачастую — финансовых) соображений изучают только часть популяции, которая и называется выборкой. В дальнейшем, статистический анализ позволяет исследователю распространить полученные закономерности на всю популяцию с определенной степенью точности. Фактически, вся биомедицинская статистика направлена на получение наиболее точных результатов из наименее возможного количества наблюдений, ведь при исследованиях на людях важен и этический момент. Мы не можем позволить себе подвергать риску большее количество пациентов, чем это необходимо.
Создание выборки регламентируется рядом обязательных требований, нарушение которых может привести к ошибочным выводам из результатов исследования. Во-первых, важен объем выборки. От объема выборки зависит точность оценки исследуемых параметров. Здесь следует обратить внимание на слово «точность». Чем больше размеры исследуемых групп, тем более точные (но не обязательно правильные) результаты получает ученый. Для того же, чтобы результаты выборочных исследований можно было переносить на всю популяцию в целом, выборка должна быть репрезентативной. Репрезентативность выборки предполагает, что в ней отражены все существенные свойства популяции. Другими словами, в исследуемых группах лица разного пола, возраста, профессий, социального статуса и пр. встречаются с той же частотой, что и во всей популяции.
Однако перед тем как начать выбор исследуемой группы, следует определиться с необходимостью изучения конкретной популяции. Примером популяции могут быть все пациенты с определенной нозологией или люди трудоспособного возраста и т. д. Так, результаты, полученные для популяции молодых людей призывного возраста, вряд ли удастся экстраполировать на женщин в постменопаузе. Набор характеристик, которые будет иметь изучаемая группа, определяет «обобщаемость» данных исследования.
Формировать выборки можно различными путями. Самый простой из них — выбор с помощью генератора случайных чисел необходимого количества объектов из популяции или выборочной рамки (sаmрling frаmе). Такой способ называется «простой случайной выборкой». Если случайным образом выбрать начальную точку в выборочной рамке, а затем взять каждый второй, пятый или десятый объекты (в зависимости от того каких размеров группы требуются в исследовании), то получится интервальная выборка. Интервальная выборка не является случайной, так как никогда не исключается вероятность периодических повторений данных в рамках выборочной рамки.
Возможен вариант создания так называемой «стратифицированной выборки», которая предполагает, что популяция состоит из нескольких различных групп и эту структуру следует воспроизвести в экспериментальной группе. Например, если в популяции соотношение мужчин и женщин 30:70, тогда в стратифицированной выборке их соотношение должно быть таким же. При данном подходе критически важно не балансировать выборку избыточно, то есть избежать однородности ее характеристик, в противном случае исследователь может упустить шанс найти различия или связи в данных.
Кроме описанных способов формирования групп есть еще кластерная и квотная выборки. Первая используется в случае, когда получение полной информации о выборочной рамке затруднено из-за ее размеров. Тогда выборка формируется из нескольких групп, входящих в популяцию. Вторая — квотная — аналогична стратифицированной выборке, но здесь распределение объектов не соответствует таковому в популяции.
Возвращаясь к объему выборки, следует сказать, что он тесно связан с вероятностью статистических ошибок первого и второго рода. Статистические ошибки могут быть обусловлены тем, что в исследовании изучается не вся популяция, а ее часть. Ошибка первого рода — это ошибочное отклонение нулевой гипотезы. В свою очередь, нулевая гипотеза — это предположение о том, что все изучаемые группы взяты из одной генеральной совокупности, а значит, различия либо связи между ними случайны. Если провести аналогию с диагностическими тестами, то ошибка первого рода представляет собой ложноположительный результат.
Ошибка второго рода — это неверное отклонение альтернативной гипотезы, смысл которой заключается в том, что различия либо связи между группами обусловлены не случайным совпадением, а влиянием изучаемых факторов. И снова аналогия с диагностикой: ошибка второго рода — это ложноотрицательный результат. С этой ошибкой связано понятие мощности, которое говорит о том, насколько определенный статистический метод эффективен в данных условиях, о его чувствительности. Мощность вычисляется по формуле: 1-в, где в — это вероятность ошибки второго рода. Данный показатель зависит преимущественно от объема выборки. Чем больше размеры групп, тем меньше вероятность ошибки второго рода и выше мощность статистических критериев. Зависимость эта как минимум квадратичная, то есть уменьшение объема выборка в два раза приведет к падению мощности минимум в четыре раза. Минимально допустимой мощностью считают 80%, а максимально допустимый уровень ошибки первого рода принимают 5%. Однако всегда следует помнить, что эти границы заданы произвольно и могут изменяться в зависимости от характера и целей исследования. Как правило, научным сообществом признается произвольное изменение мощности, однако в подавляющем большинстве случаев уровень ошибки первого рода не может превышать 5%.
Все сказанное выше имеет непосредственное отношение к этапу планирования исследования. Тем не менее, многие исследователи ошибочно относятся к статистической обработке данных только как к неким манипуляциям, выполняемым после завершения основной части работы. Зачастую после окончания никак не спланированного эксперимента, появляется непреодолимое желание заказать анализ статистических данных на стороне. Но из «кучи мусора» даже специалисту по статистике будет очень сложно выудить ожидаемый исследователем результат. Поэтому при недостаточных знаниях биостатистики необходимо обращаться за помощью в статистическом анализе еще до начала эксперимента.
Обращаясь к самой процедуре анализа, следует указать на два основных типа статистических техник: описательные и доказательные (аналитические). Описательные техники включают в себя методы позволяющие представить данные в компактном и легком для восприятия виде. Сюда можно отнести таблицы, графики, частоты (абсолютные и относительные), меры центральной тенденции (средние, медиана, мода) и меры разброса данных (дисперсия, стандартное отклонение, межквартильный интервал и пр.). Другими словами, описательные методы дают характеристику изучаемым выборкам.
Наиболее популярный (хотя и зачастую ошибочный) способ описания имеющихся количественных данных заключается в определении следующих показателей:
- · количество наблюдений в выборке или ее объем;
- · средняя величина (среднее арифметическое);
- · стандартное отклонениепоказатель того, насколько широко изменяются значения переменных.
Важно помнить, что среднее арифметическое и стандартное отклонение — это меры центральной тенденции и разброса в достаточно небольшом числе выборок. В таких выборках значения у большинства объектов с равной вероятностью отклонены от среднего, а их распределение образует симметричный «колокол» (гауссиану или кривую Гаусса-Лапласа). Такое распределение еще называют «нормальным», но в практике медицинского эксперимента оно встречается лишь в 30% случаев. Если же значения переменной распределены несимметрично относительно центра, то группы лучше описывать с помощью медианы и квантилей (процентилей, квартилей, децилей).
Завершив описание групп, необходимо ответить на вопрос об их взаимоотношениях и о возможности обобщить результаты исследования на всю популяцию. Для этого используются доказательные методы биостатистики. Именно о них в первую очередь вспоминают исследователи, когда идет речь о статистической обработке данных. Обычно этот этап работы называют «тестированием статистических гипотез» .
Задачи тестирования гипотез можно разделить на две большие группы. Первая группа отвечает на вопрос, имеются ли различия между группами по уровню некоторого показателя, например, различия в уровне печеночных трансаминаз у пациентов с гепатитом и здоровых людей. Вторая группа позволяет доказать наличие связи между двумя или более показателями, например, функции печени и иммунной системы.
В практическом плане задачи из первой группы можно разделить на два подтипа:
- · сравнение показателя только в двух группах (здоровые и больные, мужчины и женщины);
- · сравнение трех и более групп (изучение разных доз препарата).
Необходимо учитывать, что статистические методы существенно отличаются для качественных и количественных данных.
В ситуации, когда изучаемая переменная — качественная и сравниваются только две группы, можно использовать критерий «хи-квадрат». Это достаточно мощный и широко известный критерий, однако, он оказывается недостаточно эффективным в случае, если количество наблюдений мало. Для решения данной проблемы существуют несколько методов, такие как поправка Йейтса на непрерывность и точный метод Фишера.
Если изучаемая переменная является количественной, то можно использовать один из двух видов статистических критериев. Критерии первого вида основаны на конкретном типе распределения генеральной совокупности и оперируют параметрами этой совокупности. Такие критерии называют «параметрическими», и они, как правило, базируются на предположении о нормальности распределения значений. Непараметрические критерии не базируются на предположении о типе распределения генеральной совокупности и не используют ее параметры. Иногда такие критерии называют «свободными от распределения» (distributiоn-frее tеsts). В определенной степени это ошибочно, поскольку любой непараметрический критерий предусматривает, что распределения во всех сравниваемых группах будут одинаковыми, иначе могут быть получены ложноположительные результаты.
Существует два параметрических критерия применяемых к данным, извлеченным из нормально распределенной совокупности: t-тест Стьюдента для сравнения двух групп и F-тест Фишера, позволяющий проверить равенство дисперсий (он же — дисперсионный анализ). Непараметрических же критериев значительно больше. Разные критерии отличаются друг от друга по допущениям, на которых они основаны, по сложности вычислений, по статистической мощности и т. д. Однако наиболее приемлемыми в большинстве случаев считаются критерий Вилкоксона (для связанных групп) и критерий Манна-Уитни, также известный как критерий Вилкоксона для независимых выборок. Эти тесты удобны тем, что не требуют предположения о характере распределения данных. Но если окажется, что выборки взяты из нормально распределенной генеральной совокупности, то их статистическая мощность будет несущественно отличаться от таковой для теста Стьюдента.
Полное описание статистических методов можно найти в специальной литературе, однако, ключевым моментом является то, что каждый статистический тест требует набора правил (допущений) и условий для своего использования, и механический перебор нескольких методов для поиска «нужного» результата абсолютно неприемлем с научной точки зрения. В этом смысле статистические тесты близки к лекарственным препаратам — у каждого есть показания и противопоказания, побочные эффекты и вероятность неэффективности. И столь же опасным является бесконтрольное применение статистических тестов, ведь на них базируются гипотезы и выводы.
Для более полного понимания вопроса точности статистического анализа необходимо определить и разобрать понятие «доверительной вероятности». Доверительная вероятность — это величина, принятая в качестве границы между вероятными и маловероятными событиями. Традиционно, она обозначается буквой «р». Для многих исследователей единственной целью выполнения статистического анализа является расчет заветного значения р, которое словно проставляет запятые в известной фразе «казнить нельзя помиловать». Максимально допустимой доверительной вероятностью считается величина 0,05. Следует помнить, что доверительная вероятность — это не вероятность некоторого события, а вопрос доверия. Выставляя перед началом анализа доверительную вероятность, мы тем самым определяем степень доверия к результатам наших исследований. А, как известно, чрезмерная доверчивость и излишняя подозрительность одинаково негативно сказываются на результатах любой работы.
Уровень доверительной вероятности показывает, какую максимальную вероятность возникновения ошибки первого рода исследователь считает допустимой. Уменьшение уровня доверительной вероятности, иначе говоря, ужесточение условий тестирования гипотез, увеличивает вероятность ошибок второго рода. Следовательно, выбор уровня доверительной вероятности должен осуществляться с учетом возможного ущерба от возникновения ошибок первого и второго рода. Например, принятые в биомедицинской статистике жесткие рамки, определяющие долю ложноположительных результатов не более 5% - это суровая необходимость, ведь на основании результатов медицинских исследований внедряется либо отклоняется новое лечение, а это вопрос жизни многих тысяч людей.
Необходимо иметь в виду, что сама по себе величина р малоинформативна для врача, поскольку говорит только о вероятности ошибочного отклонения нулевой гипотезы. Этот показатель ничего не говорит, например, о размере терапевтического эффекта при применении изучаемого препарата в генеральной совокупности. Поэтому есть мнение, что вместо уровня доверительной вероятности лучше было бы оценивать результаты исследования по величине доверительного интервала. Доверительный интервал — это диапазон значений, в котором с определенной вероятностью заключено истинное популяционное значение (для среднего, медианы или частоты). На практике удобнее иметь оба эти значения, что позволяет с большей уверенностью судить о применимости полученных результатов к популяции в целом.
В заключение следует сказать несколько слов об инструментах, которыми пользуется специалист по статистике, либо исследователь, самостоятельно проводящий анализ данных. Давно ушли в прошлое ручные вычисления. Существующие на сегодняшний день статистические компьютерные программы позволяют проводить статистический анализ, не имея серьезной математической подготовки. Такие мощные системы как SРSS, SАS, R и др. дают возможность исследователю использовать сложные и мощные статистические методы. Однако далеко не всегда это является благом. Не зная о степени применимости используемых статистических тестов к конкретным данным эксперимента, исследователь может провести расчеты и даже получить некоторые числа на выходе, но результат будет весьма сомнительным. Поэтому, обязательным условием для проведения статистической обработки результатов эксперимента должно быть хорошее знание математических основ статистики.