Суть метода. Об одной псевдоассоциативной модели текста

Построенное таким образом множество пар бинарных псевдоассоциаций можно рассматривать как ассоциативную модель текста. Параметр в знаменателе необходим для принудительного ослабления связи между соседними лексемами. Пусть на предыдущем шаге между лексемами A и B была установлена связь r'(A, B). В простейшем случае этот функционал может быть определен так: Каждое предложение — это упорядоченное… Читать ещё >
Суть метода. Об одной псевдоассоциативной модели текста (реферат, курсовая, диплом, контрольная)
Представим анализируемый текст T в виде множества предложений Pi. (Название «предложение» здесь достаточно условно. На самом деле речь идет о некоторой смысловой единице — фразе в общем случае.).
T = {Pi}, i=1.N.
Каждое предложение — это упорядоченное множество лексем li
Pi = {li1, li2, …, lik}.
Введем понятие величины псевдоассоциативной связи между лексемами li и lj одного предложения. Нас интересует функционал, который определяет степень близости между лексемами на основе анализа их взаимного расположения. При этом желательно, чтобы степень близости находилась в интервале [0.1].
В простейшем случае этот функционал может быть определен так:
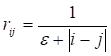
ij (1).
Параметр в знаменателе необходим для принудительного ослабления связи между соседними лексемами.
Теперь можно определить бинарные псевдоассоциации между лексемами уже на множестве предложений, т. е. на тексте. Для этого применяется следующая итерационная процедура.
- · Берется очередное предложение текста Pi.
- · Пусть на предыдущем шаге между лексемами A и B была установлена связь r'(A, B).
Если анализ Pi дает по формуле (1) между этими лексемами степень близости r''=r (A, B), то результирующее значение бинарной псевдоассоциации можно определить как.
r (A, B) = r'+r''-r'r''(2).
Это, во-первых, гарантирует сохранение итоговой оценки близости в интервале [0.1], а во-вторых — монотонно увеличивает степень связи между лексемами по мере того, как они встречаются совместно по ходу анализа предложений текста.
· Далее процесс повторяется.
Построенное таким образом множество пар бинарных псевдоассоциаций можно рассматривать как ассоциативную модель текста.
Интересно, что эта модель является работоспособной даже в самом примитивном случае, когда из текста выделяются предложения (на уровне просмотра теста до подходящего знака препинания), а лексемами объявляются последовательности символов без учета морфологии и правил словообразования.
После построения сети можно ввести слово и получить множество ассоциированных лексем. Ранжированных, например, по степени их близости. Помимо степени близости, полученной по формуле (2), можно использовать и общее количество ассоциаций для данной пары li, lj (сколько раз эти лексемы встречались вместе в одном предложении) — частоту ассоциации ij. Тогда в качестве интегральной оценки степени ассоциации можно рассматривать, скажем, произведение частоты и близости ijrij.
Здесь можно вновь вернуться к формуле (1). Принудительное ослабление степени связности связано с тем, что наибольшую близость имеют лексемы, стоящие в соседних позициях. При отсутствии параметра соседние лексемы имели бы максимальную, единичную ассоциативную близость, даже если бы во всем тексте они встретились вместе лишь однажды. На самом деле, вместо функционала (1) можно было бы использовать и более тонкие функции — показательно-степенные или гиперболические, лишь бы обеспечивались их ограниченность и монотонность.
Следует отметить, что в [1] описывается несколько похожий механизм, однако в нем рассматриваются ассоциативные связи на основе частот повторения лексем в тексте. При этом каждое предложение рассматривается как вектор частот появления в нем лексем.