Определение периодов эргодичности и бифуркации макроэкономической ситуации в АПК Краснодарского края в период с 1991 по 2005 годы

Расчет характеристик качества моделей с учетом сходства дает более высокие значения достоверности и верного отнесения, и более низкий процент ошибочного не отнесения, по сравнению с методом, учитывающим количество верных и ошибочных идентификаций классов. Это означает, что для получения более точных результатов, но с большей вероятностью ошибки прогнозирования следует использовать метод расчета… Читать ещё >
Определение периодов эргодичности и бифуркации макроэкономической ситуации в АПК Краснодарского края в период с 1991 по 2005 годы (реферат, курсовая, диплом, контрольная)
В статье исследуются периоды эргодичности и бифуркации в макроэкономической ситуации аграрно-промышленного комплекса (АПК) Краснодарского края. Описываются численные эксперименты, выполненные в универсальной когнитивной аналитической системе «Эйдос», и обосновывается разбиение исследуемого 16-ти летнего лонгитюда на периоды эргодичности и бифуркации. Проведено независимое исследование с помощью системы SPSS, подтвердившее достоверность полученных результатов и сделанных выводов.
Важность исследования периодов эргодичности связана с риском снижения адекватности синтезированной модели. При этом исследование такой модели нельзя будет считать исследованием предметной области.
Для решения задачи выявления причинно-следственных зависимостей между структурой себестоимости и объемами производства продукции в АПК, были построены модели, анализ достоверности которых показал сложную зависимость от объема обучающей выборки, а не плавный рост достоверности с увеличением объема исходных данных. Мы считаем, что это может быть связано с попаданием в обучающую выборку данных из разных периодов эргодичности. Под периодом эргодичности понимается интервал времени, в течение которого не происходило изменение действующих закономерностей. Поэтому нами было предпринято специальное исследование, посвященное обнаружению точек бифуркации, т. е. этапов смены периодов эргодичности.
Исходные данные, включающие выборку за 16 лет начиная с 1991 года, были предоставлены краевым комитетом статистики. Первичный анализ полученных данных показал, что кроме адекватной информации, в них содержится шум, т. е. данные являются фрагментарными, могут содержать ошибки или недостоверную информацию. Выбранная в качестве средства анализа данных универсальная когнитивная аналитическая система «Эйдос» [1], позволяет подавить имеющийся в данных шум и выявить закономерности и взаимосвязи между структурой себестоимости и объемом производства продукции АПК.
Снижение достоверности модели, при использовании данных, соответствующих разным периодам эргодичности, приводит к усложнению задачи выявления зависимостей, прогнозирования и поддержки принятия решений. Выходит, существующее мнение, о том, что большое количество исходных данных обеспечивает высокое качество результатов, не всегда верно, т.к. данные о поведении объекта управления в периоды с различными закономерностями и типом взаимосвязей могут противоречить друг другу. Это приводит к ошибочным выводам.
Из сказанного следует, что есть смысл изучать систему в рамках одного периода эргодичности, исключив из обучающей выборки данные, соответствующие другим периодам.
Исследование периодов эргодичности проводилось на основе моделей 1.1 и 1.2, синтез которых выполнен ранее [5], путем уменьшения объема обучающей выборки с 16 до 2-х лет. Для определения момента изменения действующих в структуре АПК закономерностей (точек бифуркации), использовались графики характеристик достоверности моделей, синтезированных системой «Эйдос» .
Для пояснения смысла этих характеристик, приведем карту идентификации информационного источника с классами распознавания (Таблица 1). В строках таблицы содержатся наименования классов и уровень их сходства с информационным источником (объектом). Положительное значение уровня сходства означает, что класс отнесен системой к объекту, отрицательное значение означает, что класс не отнесен к объекту. Флажок, поставленный в строке рядом со значением уровня сходства, означает, что класс распознавания действительно относится к объекту.
Таким образом, мы наблюдаем четыре возможные ситуации идентификации объекта с классами — две верных и две ошибочных:
верное отнесение — класс распознавания, реально относящийся к объекту, системой также отнесен к этому объекту (сходство положительное, флажок установлен),.
верное не отнесение — класс распознавания, реально не относящийся к объекту, системой не отнесен к объекту (сходство отрицательное, флажок не установлен),.
ошибочное отнесение — класс распознавания, не относящийся к объекту, отнесен системой к этому объекту (сходство положительное, флажок не установлен),.
ошибочное не отнесение — класс распознавания, реально относящийся к объекту, системой не отнесен к этому объекту (сходство отрицательное, флажок установлен).
Обратим внимание на высокий уровень сходства верно идентифицированных классов и низкий уровень сходства при ошибочной идентификации. Это означает, что расчет качества распознавания можно выполнять с учетом уровня сходства класса распознавания и объекта. Т. е. использовать значение уровня сходства как вес верной или ошибочной идентификации в целой картине расчета качества распознавания.
Второй метод расчета характеристик достоверности распознавания классов, учитывает количество верно идентифицированных классов и количество ошибочных идентификаций. При этом результат каждой идентификации класса учитывается независимо от уровня его сходства с объектом.
Таблица 1. Результат идентификации информационного источника с классами распознавания

Система «Эйдос» рассчитывает характеристики достоверности модели двумя методами: первый — с учетом уровня сходства и второй — с учетом количества верных и ошибочных идентификаций объекта. Для каждого метода, в отчете о достоверности построенной семантической информационной модели (СИМ), рассчитывается по три параметра:
- — достоверность СИМ,
- — процент верно отнесенных классов к объекту,
- — процент ошибочно не отнесенных классов к объекту.
Таким образом, имеется 6 параметров, оценивающих качество модели. А по качеству модели можно судить об адекватности синтезированной модели исследуемой предметной области, т. е. верно ли определены существующие закономерности.
В рамках данного исследования было рассмотрено три модели:
Модель A. Для классов и признаков было выбрано разбиение на 5 градаций, был выполнен синтез семантической информационной модели первым методом (СИМ 1).
Модель B. Классы и обобщенные признаки были разбиты на 7 градаций, также использовалась СИМ 1.
Модель C. Для третьей модели было выбрано 5 градаций классов и обобщенных признаки, и был выполнен синтез модели вторым методом (СИМ 2).
Модели СИМ 1 и СИМ 2 отличаются методом расчета матрицы информативностей [2]. Для обеих моделей используется классическая формула измерения количества информации Харкевича (1).
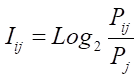
(1).
Pij — вероятность перехода объекта управления в j-е состояние в условиях действия i-го фактора;
Pj — вероятность самопроизвольного перехода объекта управления в j-е состояние, т. е. в условиях отсутствия действия i-го фактора или в среднем.
Для СИМ 1 используется выражение классической формулы Харкевича через частоты фактов.
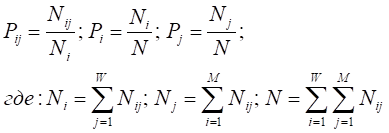
(2).
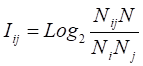
(3).
W — количество классов (мощность множества будущих состояний объекта управления),.
M — количество первичных признаков,.
Nij — суммарное количество встреч i-го признака у объектов, перешедших в j-е состояние,.
Ni — суммарное количество встреч i-го признака у всех объектов,.
Nj — суммарное количество встреч различных признаков у объектов, перешедших в j-е состояние,.
N — суммарное количество встреч различных признаков у всех объектов.
Отличие СИМ 2 заключается в изменении смысла параметров Nj и N:
Nj — количество объектов обучающей выборки, относящихся к j-му классу,.
N — общее количество всех объектов по всем категориям (в системе «Эйдос» N равняется количеству логических анкет).
Преимущество модели, рассчитанной по второму методу, в том, что отсутствует зависимость модели от количества анкет. В нашем случае СИМ 2 не зависит от количества лет в исследуемом временном интервале.
Для каждой модели было получено по 14 наборов точек по следующему алгоритму:
- 1. Формируется обучающая выборка, включающая полный набор исходных данных, т. е. статистику за 16 лет.
- 2. Выполняется синтез модели (СИМ 1 для моделей, А и В, СИМ 2 для модели С).
- 3. Обучающая выборка копируется в распознаваемую выборку и выполняется пакетное распознавание.
- 4. Выполняется измерение адекватности информационной модели, результатом которого являются шесть выше описанных характеристик достоверности модели.
- 5. Полученные точки наносятся на шесть графиков и маркируются старшим годом, из присутствующих данных в обучающей выборке.
- 6. Из обучающей выборки удаляется анкета, соответствующая старшему году, и выполняются шаги 2−6.
Очевидно, что для малого количества данных построенная модель не будет адекватна предметной области. Поэтому, анализ достоверности модели выполняется с обучающей выборкой, содержащей данные не менее чем за два года. Полученные результаты приведены в таблицах 2,3,4 и на рисунках 1 — 6.
Таблица 2. Результаты эксперимента: модель а.
Анкеты до. | С учетом сходства. | С учетом количества верных и ошибочных идентификаций. | |||||
Достоверность СИМ. | Правильно отнесены. | Ошибочно не отнесены. | Достоверность СИМ. | Правильно отнесены. | Ошибочно не отнесены. | ||
34,09%. | 85,23%. | 51,14%. | 34,09%. | 85,23%. | 51,14%. | ||
53,45%. | 89,66%. | 36,21%. | 53,45%. | 89,66%. | 36,21%. | ||
58,90%. | 91,78%. | 32,88%. | 58,90%. | 91,78%. | 32,88%. | ||
62,31%. | 92,68%. | 30,37%. | 56,25%. | 88,92%. | 32,67%. | ||
61,57%. | 91,93%. | 30,36%. | 53,02%. | 86,57%. | 33,55%. | ||
66,47%. | 91,33%. | 24,86%. | 57,47%. | 84,70%. | 26,81%. | ||
71,64%. | 88,12%. | 16,49%. | 54,37%. | 78,18%. | 23,81%. | ||
77,03%. | 87,63%. | 10,60%. | 55,04%. | 73,32%. | 18,28%. | ||
81,30%. | 89,69%. | 8,39%. | 60,76%. | 77,27%. | 16,51%. | ||
81,28%. | 88,39%. | 7,12%. | 62,49%. | 75,15%. | 12,66%. | ||
80,63%. | 87,08%. | 6,45%. | 62,11%. | 73,27%. | 11,16%. | ||
81,55%. | 86,98%. | 5,43%. | 62,24%. | 71,81%. | 9,56%. | ||
80,23%. | 85,47%. | 5,25%. | 59,79%. | 69,05%. | 9,25%. | ||
80,23%. | 85,47%. | 5,25%. | 59,79%. | 69,05%. | 9,25%. | ||
Таблица 3. Результаты эксперимента: модель в.
Анкеты до. | С учетом сходства. | С учетом количества верных и ошибочных идентификаций. | |||||
Достоверность СИМ. | Правильно отнесены. | Ошибочно не отнесены. | Достоверность СИМ. | Правильно отнесены. | Ошибочно не отнесены. | ||
50,00%. | 84,09%. | 34,09%. | 50,00%. | 84,09%. | 34,09%. | ||
60,35%. | 87,93%. | 27,59%. | 60,35%. | 87,93%. | 27,59%. | ||
69,86%. | 90,41%. | 20,55%. | 69,86%. | 90,41%. | 20,55%. | ||
68,75%. | 92,05%. | 23,30%. | 68,75%. | 92,05%. | 23,30%. | ||
69,48%. | 90,82%. | 21,33%. | 58,94%. | 81,59%. | 22,65%. | ||
76,83%. | 92,23%. | 15,40%. | 58,16%. | 77,22%. | 19,07%. | ||
77,64%. | 88,06%. | 10,41%. | 55,46%. | 70,20%. | 14,74%. | ||
79,95%. | 86,66%. | 6,71%. | 57,84%. | 69,02%. | 11,18%. | ||
83,87%. | 88,61%. | 4,74%. | 59,24%. | 68,68%. | 9,44%. | ||
84,62%. | 87,89%. | 3,27%. | 62,57%. | 69,36%. | 6,79%. | ||
84,75%. | 87,74%. | 2,99%. | 60,29%. | 66,70%. | 6,41%. | ||
84,41%. | 86,88%. | 2,47%. | 58,17%. | 63,47%. | 5,31%. | ||
83,08%. | 85,68%. | 2,60%. | 57,17%. | 62,40%. | 5,23%. | ||
83,08%. | 85,68%. | 2,60%. | 57,17%. | 62,40%. | 5,23%. | ||
Таблица 4. Результаты эксперимента: модель с
Анкеты до. | С учетом сходства. | С учетом количества верных и ошибочных идентификаций. | |||||
Достоверность СИМ. | Правильно отнесены. | Ошибочно не отнесены. | Достоверность СИМ. | Правильно отнесены. | Ошибочно не отнесены. | ||
47,73%. | 85,23%. | 37,50%. | 47,73%. | 85,23%. | 37,50%. | ||
58,62%. | 89,66%. | 31,03%. | 58,62%. | 89,66%. | 31,03%. | ||
64,38%. | 91,78%. | 27,40%. | 64,38%. | 91,78%. | 27,40%. | ||
68,16%. | 92,60%. | 24,43%. | 63,64%. | 88,92%. | 25,28%. | ||
65,52%. | 91,79%. | 26,27%. | 59,75%. | 86,73%. | 26,98%. | ||
65,42%. | 90,45%. | 25,03%. | 54,18%. | 81,91%. | 27,73%. | ||
71,13%. | 87,94%. | 16,81%. | 54,00%. | 75,21%. | 21,21%. | ||
76,95%. | 87,45%. | 10,50%. | 57,39%. | 74,22%. | 16,82%. | ||
81,22%. | 89,69%. | 8,47%. | 62,72%. | 76,36%. | 13,63%. | ||
81,61%. | 88,42%. | 6,82%. | 64,11%. | 74,26%. | 10,15%. | ||
81,55%. | 87,28%. | 5,74%. | 62,93%. | 72,48%. | 9,56%. | ||
82,86%. | 87,35%. | 4,50%. | 63,89%. | 72,12%. | 8,24%. | ||
81,65%. | 86,08%. | 4,43%. | 61,06%. | 69,19%. | 8,13%. | ||
81,65%. | 86,08%. | 4,43%. | 61,06%. | 69,19%. | 8,13%. | ||
На основе приведенных таблиц были построены графики, наглядно демонстрирующие полученные результаты.
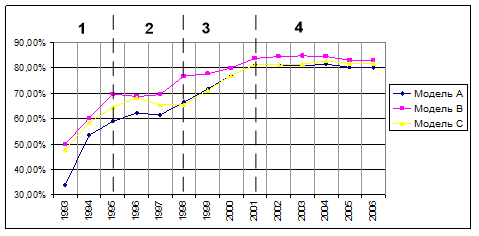
Рисунок 1. Достоверность СИМ (с учетом сходства).
На рисунке явно выделяется четыре периода: низкая достоверность модели в первом периоде объясняется малым объемом обучающей выборки. Второй этап показывает достоверность модели на уровне 60 — 70%. Это связано со смешением качественно различных закономерностей, действующих в это время: еще сильны механизмы плановой экономики, и в то же время набирают силу новые механизмы, присущие рыночной экономике. Третий период можно считать этапом бифуркации, за которым идет период стабилизации модели на уровне 80 — 85%. Из этого можно сделать вывод о сформировавшихся закономерностях рыночного характера, и уже незначительного остаточного влияния старых механизмов.
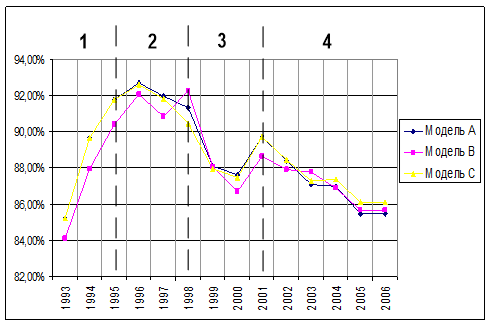
Рисунок 2. Правильно отнесено (с учетом сходства).
Максимальные значения правильно отнесенных классов наблюдается во втором периоде. Вероятно, это связано с ярким характером анкет данного этапа. Значения четвертого интервала снижаются до 85%, вероятно, в связи со стабилизацией системы, а значит, с более высокой степенью сходства информационных источников, соответствующих соседним годам.
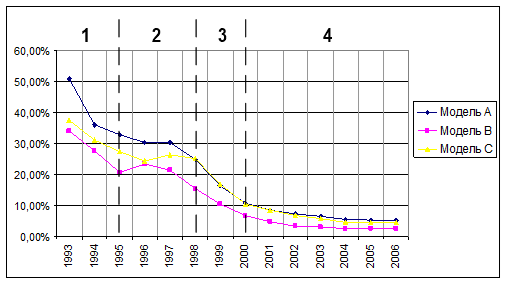
Рисунок 3. Ошибки не отнесения (с учетом сходства).
эргодичность бифуркация эксперимент лонгитюд На данном графике можно объединить третий и четвертый периоды, т.к. начиная с 1998 года, наблюдается тенденция к уменьшению процента ошибок не отнесения. При этом после 2001 года мы видим стабилизацию моделей на уровне 3−7%.
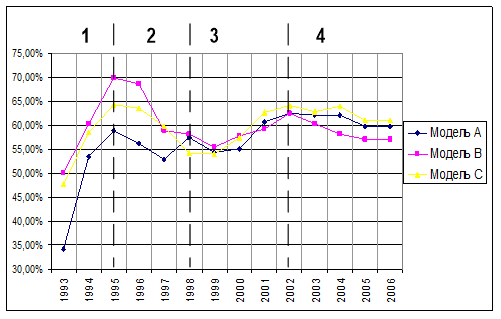
Рисунок 4. Достоверность СИМ (с учетом количества верных и ошибочных идентификаций).
Оценка достоверности моделей с учетом количества верных и ошибочных идентификаций показывает больший разброс значений и существенно более низкий уровень (57−65%) достоверности моделей в четвертом периоде. Однако, по прежнему, исследуемый интервал времени можно разделить на четыре периода. Эти замечания также касаются следующих двух характеристик качества моделей (Рисунки 5 и 6).
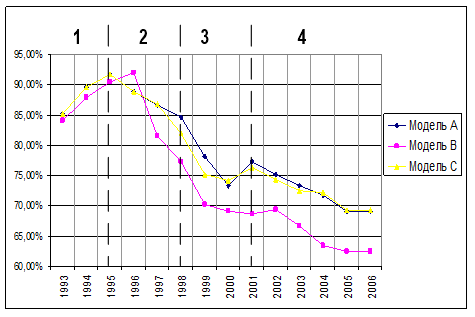
Рисунок 5. Правильно отнесено (с учетом количества верных и ошибочных идентификаций).
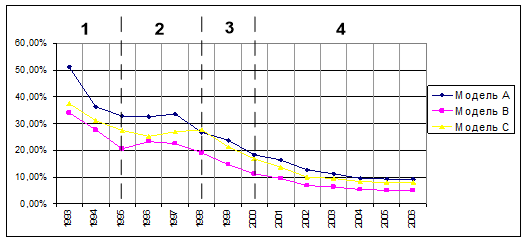
Рисунок 6. Ошибки не отнесения (с учетом количества верных и ошибочных идентификаций).
Все приведенные графики показывают возможность определения четырех периодов:
Первый — период, данные для которого были получены при очень малом объеме обучающей выборки — менее пяти анкет. Такое количество данных привело к резкому ухудшению качества моделей, что и отображено на графиках.
Второй период демонстрирует нестабильное поведение исследуемых параметров. Такое поведение говорит о смешении качественно различных закономерностей: еще продолжающих свое влияние законов плановой экономики и появившихся в результате экономических реформ, новых законов, связанных с переходом на рыночную экономику.
Начало третьего периода, очевидно, обусловлено дефолтом, произошедшем в 1998 году. После этого события влияние законов плановой экономики становится незначительным, и наблюдаемые закономерности становятся однотипными.
После 2000 — 2001 годов начинается четвертый период: мы наблюдаем стабилизацию моделей, связанную с тем, что закономерности рыночной экономики становятся доминирующими. Кроме этого, данные последнего периода получены при наибольшем объеме обучающей выборки, что приводит к максимальной достоверности синтезированных моделей.
Расчет характеристик качества моделей с учетом сходства дает более высокие значения достоверности и верного отнесения, и более низкий процент ошибочного не отнесения, по сравнению с методом, учитывающим количество верных и ошибочных идентификаций классов. Это означает, что для получения более точных результатов, но с большей вероятностью ошибки прогнозирования следует использовать метод расчета достоверности с учетом сходства. Но при повышенных требованиях к отсутствию ошибок, лучше воспользоваться данными второго метода, т.к. он предъявляет более строгие требования к достоверности идентификации классов.
Сравнение параметров трех построенных моделей приводит к выводу о большей достоверности модели В, для которой было выбрано 7 градаций классов и факторов. Однако, исследование качества модели показало не оправданным ее использование по сравнению с моделью А, где определено 5 градаций классов и факторов [4].
График модели С, при синтезе которой использовался метод СИМ 2, является более гладким по сравнению с графиком модели А, и при этом демонстрирует более высокую достоверность. Это означает возможность более точного прогнозирования поведения модели.
Независимое исследование периодов эргодичности было выполнено с помощью новой модели, синтезированной в системе Эйдос. В качестве классов распознавания в этой модели были взяты анкеты (каждая анкета соответствует одному из годов исследуемого периода времени). После выполнения синтеза модели, пакетного распознавания и кластерного конструктивного анализа, была построена семантическая сеть классов распознавания (Рисунок 7).
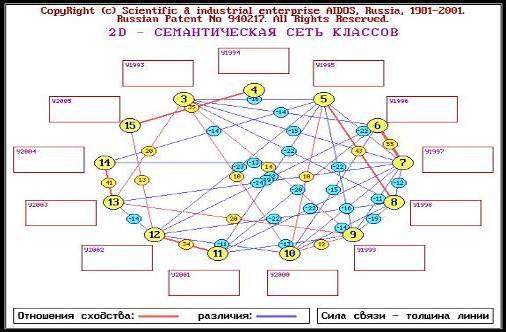
Рисунок 7. Семантическая сеть классов.
На рисунке красные линии обозначают сходство классов, синие — их различие. Толщина линии соответствует степени сходства или различия. В кружке на линии выведено значение уровня сходства классов, соединенных этой линией.
Анализ построенной семантической сети показывает сходство 1995 и 1998 гг., 1996 и 1997гг., 2001 и 2002 г., 2003 и 2004 годов. Изображенное сходство 1994 и 2005 годов объясняется малым количеством данных в анкете за эти годы, и должно считаться ошибочным. Заметим, что похожие пары классов находятся в границах одного периода эргодичности, согласно выше приведенным исследованиям.
Для проверки полученных результатов, был проведен анализ данных с использованием системы SPSS версии 13. В качестве исходных данных использовалась матрица информативностей, рассчитанная в системе Эйдос. Для этих данных была проведена иерархическая кластеризация методом ближайших соседей, и построена дендограмма полученных кластеров (Рисунок 8).
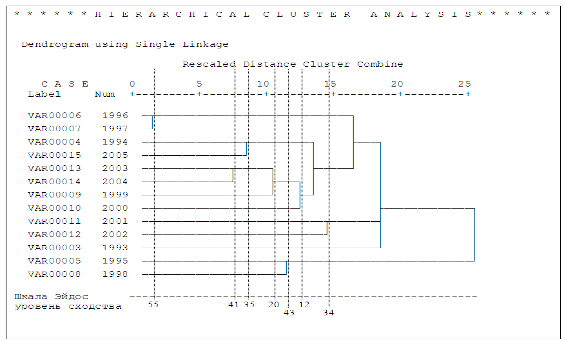
Рисунок 8. Сравнение результатов анализа периодов эргодичности в системах SPSS и Эйдос.
Очевидно сходство результатов анализа разными системами. На рисунке сверху приведена шкала уровня различия классов, а в нижней части рисунка выведена шкала уровней сходства классов, полученных в системе Эйдос.
Итак, в рамках данной работы был осуществлен анализ исходных данных на наличие периодов эргодичности и бифуркации. Сделан вывод о том, что повышение объема обучающей выборки положительно влияет на качество модели только в случае совпадения закономерностей, действующих в период времени, соответствующий этим данным. Т. е. для достижения максимальной адекватности модели необходимо ограничить обучающую выборку данными из одного периода эргодичности. На основе проведенных численных экспериментов, были определены границы трех периодов эргодичности, обоснованные изменением характеристик достоверности синтезированных моделей. Независимое исследование, проведенное с помощью системы SPSS, подтвердило полученные результаты и выводы.
- 1. Луценко Е. В. Интеллектуальные информационные системы: Учебное пособие для студентов специальности: 351 400 «Прикладная информатика (по отраслям)». — Краснодар: КубГАУ. 2004. — 633 с.
- 2. Луценко Е. В., Лойко В. И. Семантические информационные модели управления агропромышленным комплексом. Монография (научное издание). — Краснодар: КубГАУ. 2005. — 477 с.
- 3. Шеляг М. М. Изучение влияния структуры себестоимости на объемы производства в АПК с применением технологий искусственного интеллекта// Информационные технологии: Сборник научных работ: «Научное обеспечение агропромышленного комплекса». Материалы VII регион. науч.-практ. конф. молод. ученых. — Краснодар: КубГАУ, 2005. С. 379−380.
- 4. Шеляг М. М. Системно-когнитивный анализ влияния структуры себестоимости продукции на объемы ее производства в АПК// Технические науки: Сборник научных работ: «Труды Кубанского государственного аграрного университета». — Выпуск № 420 (448). — Краснодар: КубГАУ, 2005. С. 118−123.