Обработка результатов многоуровневых экспериментов

Если какие-либо из допущений, необходимых для проведения ANOVA, не выполняются на ваших данных (например, дисперсии в разных условиях негомогенны при том, что количество испытуемых в группах различается), есть смысл подумать о том, чтобы использовать непараметрический аналог дисперсионного анализа для несвязанных выборок — Я-критерий Краскела — Уоллеса. Он проверяет ту же нулевую гипотезу… Читать ещё >
Обработка результатов многоуровневых экспериментов (реферат, курсовая, диплом, контрольная)
Статистические методы обработки результатов многоуровневых экспериментов чуть более сложны, чем для двухуровневых, и состоят из большего количества шагов.
Здесь мы коротко опишем использующийся в таких случаях метод дисперсионного анализа, его разновидности и аналоги, а также связанные с его применением трудности. За более подробной характеристикой описываемых статистических критериев предлагаем вам обращаться к книгам, посвященным математическим методам в экспериментальной психологии и дисперсионному анализу.
Дисперсионный анализ (Analysis Of Variance, ANOVA) — статистический метод обработки результатов сложных экспериментов, автором которого является английский статистик Р. Фишер. Различают следующие виды дисперсного анализа:
однофакторный дисперсионный анализ (one-way ANOVA), который применяется для анализа данных многоуровневых экспериментов с одной независимой переменной;
многофакторный дисперсионный анализ (two-way ANOVA, three-way ANOVA и т. д.), применяющийся для обработки результатов экспериментов с двумя и более независимыми переменными;
многомерный дисперсионный анализ (МANOVA) — для случаев, когда зависимая переменная представлена несколькими измерениями. Здесь мы остановимся только на простом однофакторном дисперсионном анализе.
Начнем с ANOVA для межгрупповых исследований.
Математическая идея однофакторного ANOVA заключается в том, что общую изменчивость (дисперсию) исследуемого признака можно разделить на две составляющие — внутригрупповую и межгрупповую. Сопоставляя эти части дисперсии, мы можем получить представление о том, насколько различаются средние значения зависимой переменной на разных уровнях независимой. Так, если попытаться объединить в одну выборку несколько более мелких групп с одинаковыми дисперсиями, но разными средними, то дисперсия в получившейся общей выборке окажется больше, причем она увеличится пропорционально различиям в средних значениях. Эго связано с тем, что к внутригрупповой дисперсии добавится межгрупповая.
Внутригрупповая изменчивость — это дисперсия признака внутри каждой исследуемой группы, т. е. разброс индивидуальных различий испытуемых, работавших в каждом условии. Эта часть дисперсии рассматривается в рамках модели AN OVA как обусловленная влиянием случайных причин, ошибок измерения и т. п.
Межгрупповая изменчивость — это дисперсия признака между группами. Иначе говоря, это характеристика того, насколько велик разброс средних значений признака, полученных для разных уровней независимой переменной, по сравнению с общим средним значением признака, которое можно получить, объединив все группы в одну. Эта часть дисперсии в модели AN OVA считается обусловленной влиянием независимой переменной и (или) влиянием побочных переменных, определяющих также и внутригрупповую вариацию данных.
Поясним соотношения между внутригрупповой и межгрупповой дисперсией с помощью структурной модели однофакторного дисперсионного анализа, описывающей межгрупповой эксперимент. Предполагается, что всякое значение Xjj — зависимой переменной для испытуемого і в группе j — представляет собой аддитивную сумму се популяционного среднего значения р, эффекта независимой переменной на соответствующем уровне тj и экспериментальной ошибки ?ij и может быть выражено следующим образом:

Очевидно, что внутригрупповые различия результатов различных испытуемых, участвующих в эксперименте, обусловлены в соответствии с этой моделью только значением экспериментальной ошибки ?ij, тогда как межгрупповая дисперсия помимо этого источника может определяться эффектом тj.
Внутригрупповая дисперсия в дисперсионном анализе оценивается таким образом, что ее ожидаемое значение оказывается равным ??2. Ожидаемое значение межгрупповой дисперсии оказывается равным ??2 + п? т2.
Расчет отношения межгрупповой составляющей общей дисперсии зависимой переменной к внутригрупповой является основным результатом дисперсионного анализа. Его теоретически ожидаемое значение может быть выражено таким образом:

Чем сильнее межгрупповая (т.е. связанная с влиянием фактора) изменчивость преобладает над внутригрупповой (т.е. обусловленной случайными вариациями), тем больше вероятность того, что средние в сравниваемых группах различаются.
Нулевая гипотеза, проверяющаяся в рамках дисперсионного анализа, утверждает, что в популяции средние значения зависимой переменной на разных уровнях независимой равны между собой. А это значит, что значение ?т2 оказывается равным нулю. В этом случае статистика F описывается F-распределением, и ее ожидаемое значение оказывается равным 1. Альтернативная гипотеза заключается в том, что хотя бы два средних значения отличаются друг от друга. И тогда дисперсия ? т2превышает нулевое значение, а ожидаемое значение статистики F оказывается больше 1.
Таким образом, по F-отношению можно лишь узнать, есть ли влияние независимой переменной на зависимую вообще, но нельзя определить, для каких именно экспериментальных условий показатели зависимой переменной достоверно различаются и каковы конкретно количественные соотношения между независимой и зависимой переменными.
Если в результате подсчета ANOVA вы обнаруживаете значимое влияние фактора (значение p-уровня для F-отношения окажется меньше 0,05), тогда для выяснения того, средние для каких именно условий различаются, должны быть сделаны дополнительные шаги по обработке, связанные с оценкой контрастов. Они могут быть априорными или апостериорными (post hoc).
Определять апостериорные контрасты, т. е. попарные сравнения средних, при помощи t-критерия Стыодента было бы некорректно, поскольку это приведет к увеличению вероятности совершения ошибки первого рода (когда различий в действительности нет, но результаты расчетов позволяют отклонить нулевую гипотезу). Поэтому для осуществления множественных попарных сравнений используются специальные методы, корректирующие p-уровни. Чаще всего используются методы Шеффе, Бонферрони, Тыоки и др. Эти методы различаются степенью своей консервативности. Компьютерные статистические программы предлагают на выбор большое количество различных вариантов осуществления post hoc анализа.
Оценка априорных контрастов предполагает использование каких-либо заранее заданных количественных моделей. Например, можно предполагать, что между независимой и зависимой переменными имеет место линейная или какая-либо нелинейная связь. В этом случае оценка эффекта независимой переменной предполагает вычисление статистики следующего вида:

где Сj коэффициенты контраста такие, что должно выполняться соотношение 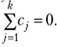
Сами коэффициенты контраста задаются с помощью выбраним ной модели. Например, для четырехуровнего плана можно использовать следующие коэффициенты, определяющие линейный контраст: -3, -1,1, 3. Надежность построенной статистики оценивается обычно путем построения F-отношения:

Для использования дисперсионного анализа при обработке результатов данные должны соответствовать допущениям, лежащим в его основе. Эти допущения, однако, не являются строгими, и в большинстве случаев ими можно пренебречь.
Первое допущение предполагает, что для каждого экспериментального условия значения зависимой переменной в генеральной совокупности подчиняются закону нормального распределения.
Второе допущение заключается в том, что дисперсии зависимой переменной, измеренной для разных экспериментальных условий, однородны (равны). Для проверки предположения об однородности дисперсий чаще всего используется критерий Ливиня или его аналоги. Данный критерий проверяет нулевую гипотезу о равенстве дисперсий для всех сравниваемых групп. Если /^-уровень для него оказывается больше 0,05, то нулевая гипотеза не отклоняется, и дисперсии могут рассматриваться как равные. Если p-уровень оказывается меньше 0,05, нулевая гипотеза отклоняется, и дисперсии нельзя рассматривать как равные; для таких данных допущение о равенстве дисперсий признается невыполненным. Нарушение этого допущения наиболее существенным образом сказывается на результатах ANOVA, когда количество испытуемых в разных группах различается.
Следует все же отметить, что невыполнение этих двух требований, как показывают теоретические расчеты, не сказывается существенно на результатах анализа[1].
Третье допущение предполагает, что выборки, соответствующие разным экспериментальным условиям, являются независимыми. Если вы использовали для подбора испытуемых в группы процедуры уравнивания, нужно применять AN OVA с повторными измерениями.
Таким образом, последовательность шагов при расчетах ANOVA будет следующей.
- 1) проверка выполнения допущения о гомогенности дисперсий в разных группах (тест Ливиня);
- 2) расчет показателей дисперсионного анализа (F-отношение и его p-уровень). Если F-отношение будет признано значимым, то:
- 3) парные сравнения средних для выяснения того, средние значения зависимой переменной для каких именно экспериментальных условий различаются между собой.
Следует иметь в виду, что статистические пакеты, обычно использующиеся для обработки данных (например, SPSS), выполняют все эти шаги одновременно. И вы получаете в окне вывода результаты сразу всех сравнений: независимо от того, оказался ли тест Ливиня значимым, будет подсчитано F-отношение, и независимо от того, значимо ли F-отношение, будут выведены результаты парных сравнений.
Поэтому нужно внимательно подходить к изучению тех таблиц и показателей, которые вы получите в результате использования статистических программ. Тот факт, что компьютер произвел подсчеты, еще не значит, что они имеют содержательную интерпретацию и должны быть приведены в отчетах. Анализировать результаты post hoc сравнений имеет смысл только при наличии значимого F-отношения, а серьезно подходить к анализу F-отношения — только в тех случаях, если первичные проверки показали, что ваши данные пригодны для проведения ANOVA.
При изложении в отчете (или статье) результатов проведения дисперсионного анализа приводятся следующие показатели:
- — описательная статистика зависимой переменной для каждого экспериментального условия (средние арифметические и стандартные отклонения);
- — F-отношение и p-уровень его значимости с обязательным указанием числа степеней свободы для F-статистики;
- — результаты post hoc анализа (в случае, если F-отношение значимо) с указанием используемого метода коррекции и p-уровня для каждого парного сравнения;
результаты анализа априорных контрастов.
Если какие-либо из допущений, необходимых для проведения ANOVA, не выполняются на ваших данных (например, дисперсии в разных условиях негомогенны при том, что количество испытуемых в группах различается), есть смысл подумать о том, чтобы использовать непараметрический аналог дисперсионного анализа для несвязанных выборок — Я-критерий Краскела — Уоллеса. Он проверяет ту же нулевую гипотезу, но на основании несколько других расчетов. В случае обнаружения значимых различий также нужно проводить дополнительные парные сравнения (в данном случае их нужно делать при помощи критерия Манна — Уитни).
При обработке результатов внутрисубъектных экспериментов используется ANOVA с повторными измерениями (repeated measures ANOVA). Общая идея применения этого вида анализа по сути схожа с межгрупповой версией ANOVA, за тем исключением, что здесь не предполагается независимость сравниваемых групп. В этом случае используется следующая структурная модель, учитывающая эффект испытуемого к:
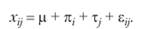
Согласно этой модели, дисперсия результатов внутри одного экспериментального условия определяется не только экспериментальной ошибкой, но и различиями между испытуемыми, заданными их индивидуальными особенностями. Поскольку эти различия воспроизводятся для всех уровней независимой переменной в неизменном виде, имеет место ковариация значений зависимой переменной для разных уровней независимой переменной. Эта ковариация должна быть извлечена из имеющейся дисперсии.
Стандартная модель дисперсионного анализа с повторными измерениями основана на предположении о сферичности ковариационно-вариационной матрицы. Иными словами, предполагается, что дисперсии значений зависимой переменной и величины их ковариаций в разных условиях одинаковы. Поэтому из оценки дисперсии экспериментальной ошибки просто вычитается средняя величина значений ковариации для всех экспериментальных условий.
Нужно особо отметить, что предположение об однородности ковариационно-вариационной матрицы является очень важным, и потому оно обязательно должно быть проверено. Для проверки этого допущения используется тест Моучли. Если в результате расчетов />уровень для него превышает 0,05, то допущение о сферичности выполняется, а если оказывается меньшим 0,05, то допущение о сферичности не выполняется.
При невыполнении условий гомогенности вариационно-ковариационной матрицы в расчетах можно использовать специальные поправки числа степеней свободы как числителя, так и знаменателя /•'-отношения. В крайнем случае, рекомендуется уменьшить их число в k — 1 раз, где к — число уровней независимой переменной. Чаще, однако, используют менее консервативные процедуры, такие как, например, поправки Гринхауса — Гейссера или Хюнха — Фельдта.
Обойти предположение об однородности ковариационно-вариационной матрицы можно также, используя многомерные тесты дисперсионного анализа MANOVA или исследуя априорные контрасты.
Если ANOVA с повторными измерениями показывает значимое влияние независимой переменной, для выяснения того, какие именно из сравниваемых средних значений различаются, также используются попарные сравнения средних (post hoc). Например, в программе SPSS они осуществляются при помощи /-критерия для связанных выборок с коррекцией р-уровней. Более правильным, однако, будет использование априорных контрастов, которые, как мы помним, позволяют исследовать не только качественные, но и количественные соотношения между независимой и зависимой переменными, а также обходить не всегда справедливое допущение об однородности вариационно-ковариационной матрицы.
Существует также непараметрический аналог дисперсионного анализа для связных выборок — тест Фридмана. Его рекомендуется использовать, когда значения зависимой переменной представляют собой результаты ранжирования. Однако для этого теста пока еще нет общепризнанных и хорошо разработанных процедур попарного сравнения. В крайнем случае, это можно осуществлять при помощи критерия Уилкоксона.
- [1] Box G. Some theorems on quadratic forms applied in the study of analysis of variance problems. Annals of Mathematical Statistics. 1954. Vol. 25. P. 290—302: 484—498.