Инструментарий маркетинговых исследований рынка инновационной деятельности

Рис. 10.14. Анализ остатков Одним из критериев, позволяющих осуществить проверку независимости остатков, является критерий Дарбина — Уотсона. Область допустимых значений критерия описывается отрезком. В случае если DW е, автокорреляция в остатках отсутствует и регресионная модель считается пригодной для использования. Для исследования зависимости между остатками и прогнозом щелкните по кнопке… Читать ещё >
Инструментарий маркетинговых исследований рынка инновационной деятельности (реферат, курсовая, диплом, контрольная)
Под маркетинговыми исследованиями понимают сбор, учет, анализ и обработку данных в маркетинговой предметной области в целях совершенствования управленческих решений в маркетинговой среде.
Схема проведения маркетинговых исследований представлена на рис. 10.4.
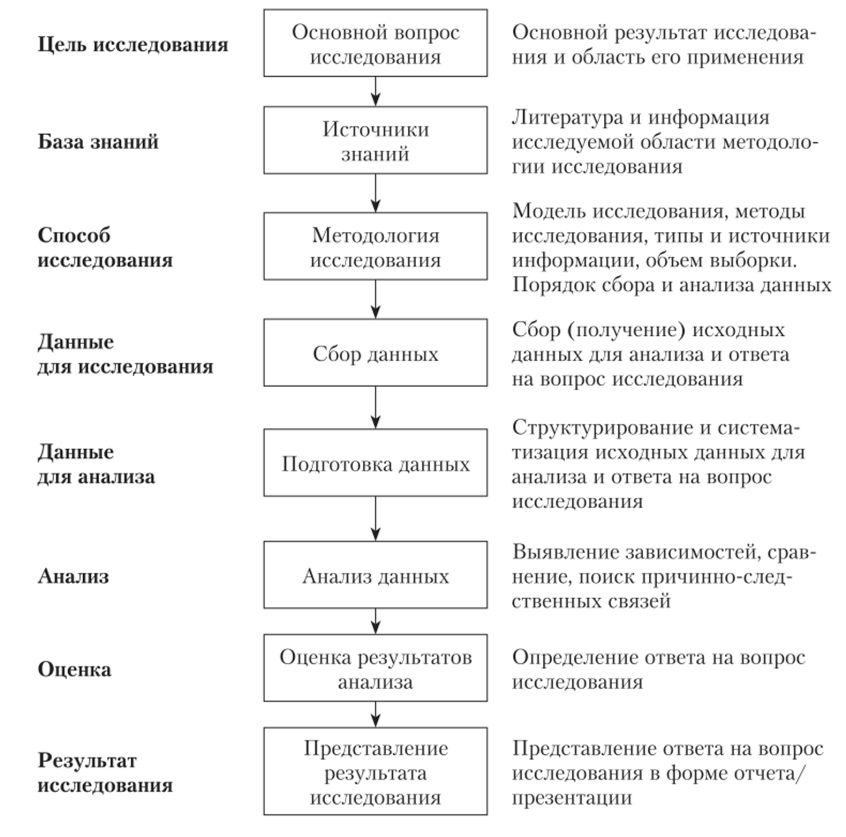
Рис. 10.4. Схема проведения маркетинговых исследований
Под методами маркетинговых исследований понимают приемы, процедуры и операции эмпирического, теоретического и практического изучения и анализа маркетинговой среды, в которой существует инновационное предприятие[1]. Методы маркетинговых исследований делятся на методы, основанные на сборе первичной и вторичной информации. Под вторичной информацией понимается информация, собранная для целей, не связанных с текущей задачей маркетингового исследования.
Методы маркетинговых исследований условно можно разделить на две крупные группы:
- — направленные в основном на сбор и учет маркетинговой информации: это методы опроса, фокус-группы и др.;
- — в большей степени направленные на анализ и обработку маркетинговой информации: статистические и вероятностные, методы экспертных оценок (анализа иерархий, Дельфи и др.), пробного маркетинга, а также методы конкурентного анализа (ВШЗВ-анализа, сегментации рынка и др.) и портфельного анализа (BCG-матрица, GB-матрица и др.) (рис. 10.5).
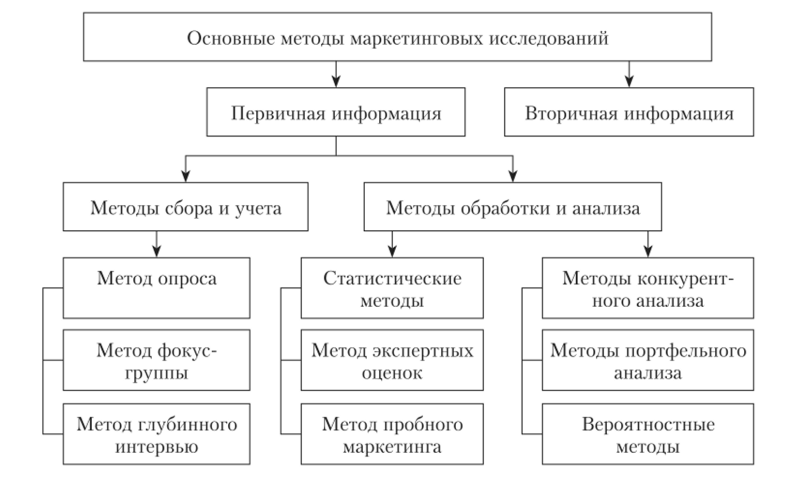
Рис. 10.5. Классификация методов маркетинговых исследований
Одним из наиболее популярных методов обработки и анализа маркетинговой информации, используемых в процессе сегментации, является статистическая сводка и группировка данных. Статистическая группировка позволяет упорядочить маркетинговую информацию. Э го разбиение статистической совокупности на отдельные группы однородные по одному или нескольким признакам. Помимо сегментации рынка, с помощью статистической группировки в маркетинге решаются задачи изучения структуры совокупности, исследования зависимостей, типов социально-экономических явлений.
По способу построения группировки делятся на структурную, аналитическую, типологическую и комбинационную.
Цель структурной группировки состоит в исследовании структуры совокупности по заданному признаку, при этом всегда рассматривается только один признак. Способ построения структурной группировки зависит от признака. Если признак, по которому требуется построить группировку, является качественным, то группировка выполняется по заданном}' признаку путем подсчета единиц совокупности, входящих в каждую группу.
Пусть имеются данные по потреблению молока марки «Простоквашино» среди подростков. Объем совокупности составляет 100 человек. Установлено, что в указанной фокус-группе молоко данной марки употребляют 10% юношей и 90% девушек. Требуется составить структурную группировку по признаку «пол» (табл. 10.8).
Таблица 10.8
Структурная группировка по признаку «пол».
Пол. | Количество человек. | % к итогу. |
Мужской. | ||
Женский. | ||
Итого. |
Если признак, по которому требуется построить группировку, количественный, то необходимо определить, каким является предлагаемый для рассмотрения признак: дискретным или непрерывным. Группировки по непрерывному признаку называются интервальными и могут состоять из равных и неравных интервалов. При построении группировок с неравными интервалами — неравноинтервальных — необходимо соблюсти определенную систему, например, построить такую группировку в геометрической прогрессии. Группировки, в которых количество элементов в каждой группе приблизительно одинаково, называются равнонаполненными группировками[2].
Алгоритм построения равноинтервалыюй группировки состоит из следующих шагов.
Шаг 1. Исследователь должен определить, на какое количество групп необходимо разбить интервал. Обычно для этого используется формула Стерджесса: п = 1 + 3,3lgN, где N — объем совокупности; п — количество групп.
Шаг 2. Определить минимальные и максимальные значения признака и рассчитать шаг интервала Д = (Xmax — Xmin) / п, где п — количество групп. Округлить полученную величину до целых.
Шаг 3. Рассчитать количество единиц признака в каждой группе.
Построение равноинтервальной группировки Пусть имеются распределенные в совокупности среднемесячные доходы целевых потребителей от 10 000 до 21 000 руб. Выполнено 100 наблюдений. Требуется построить равно интервальную группировку.
Решение. Определим количество групп по формуле Стерджссса: п = 1 + 3,3lg N = 5.
Шаг интервала соответствует значению 2,2 тыс. руб., полученному по формуле Д =(*тах -*тт)/Я= (21 ООО «Ю000) / 5 = 2,2 ТЫС. рУб.
Таким образом, равноинтервальная группировка имеет вид следующий вид (табл. 10.8).
Таблица 10.8
Равноинтервальная группировка по признаку «среднемесячные доходы»
Среднемесячные доходы, тыс. руб. | Количество опрошенных, чел. | % к итогу. |
[10−12,2]. | ||
(12,2−14,4]. | ||
(14,4−16,6]. | ||
(16,6−18,8]. | ||
(18,8−211. | ||
Итого. |
Алгоритм построения равнонанолненной группировки состоит из следующих шагов.
Шаг 1. Определить количество элементов, попадающих в группу по формуле т = N / пу где N — объем совокупности; п — количество групп.
Шаг 2. Упорядочить данные.
Шаг 3. Сформировать границы групп, ориентируясь на имеющиеся данные.
Пример 10.2.
Построение равнонанолненной группировки Пусть имеются данные о численности населения в торговой зоне, тыс. чел.: 1,7, 2,8, 3,2, 3,3, 2,5, 1,9, 2,1, 1,9, 3,1, 1,6, 2. Требуется построить равнонаполценную группировку.
Решение. Определим количество элементов, попадающих в группу, но формуле m = N/п= 12 /3=4. Упорядочим данные: 1,6, 1,7, 1,9, 1,9, 2, 2, 2,1, 2,5, 2,8, 3, 3,1, 3,3. Таким образом, равнонаполненная группировка имеет следующий вид (табл. 10.9).
Таблица 10.9
Равнонаполненная группировка по признаку «численность населения».
Численность населения, тыс. чел. | Количество торговых точек, шт. | % к итогу. |
11,6−1,9|. | 33,3. | |
(1,9−2,5|. | 33,3. | |
(2,5−3,3]. | 33,3. | |
Итого. |
Типологическая группировка строится с целью выявления социальноэкономических типов. Данная группировка строится на основе структурной группировки. Вид типологической группировки в значительной мере определяется представлением маркетологов о том, какие типы могут встретиться в изучаемой совокупности.
Алгоритм построения типологической группировки состоит из следующих шагов: Шаг 1. Выделить типы и явления, по которым требуется построить типологическую группировку; Шаг 2. Выбрать группировочные признаки, определяющие эти типы; Шаг 3. Сформировать границы групп, ориентируясь на имеющиеся данные; Шаг 4. Оформить группировку в виде таблицы, выделенные группы объединяются в намеченные типы.
Аналитическая группировка характеризует взаимосвязь между двумя и более признаками. При этом один из признаков рассматривается, как признак-результат, а другие — как признак-фактор, который оказывает влияние на признак-результат. Совокупность делится на подгруппы по признаку-фактору; по каждой подгруппе рассчитывается среднее значение по признаку-результату.
Пример 10.3.
Построение аналитической группировки Пусть имеются данные о численности населения в торговой зоне и об объеме продаж (табл. 10.11). Требуется построить аналитическую группировку.
Таблица 10.11
Выборка данных.
Численность населения в торговой зоне, тыс. чел. | Объем продаж, млн руб. |
1,7. | |
2,8. | |
3,3. | |
2,5. | |
1,9. | |
2,1. | |
1,9. | |
3,1. | |
1,6. |
Решение. Определим признак-фактор и признак-результат. В качестве признакафактора предлагается рассматривать численность населения, в качестве признакарезультата — объем продаж. Пользуясь группировкой из примера 10.2, построим аналитическую группировку (табл. 10.12).
Аналитическая группировка.
Численность населения, тыс. чел. | Количество торговых точек, шт. | Среднее значение объема продаж, млн руб. |
[1,6−1,9]. | (27 + 26 + 28 + 31)/4 = 28. | |
(1,9−2,5]. | ||
(2,5−3,3|. | 32,5. | |
Итого. |
В результате анализа данных аналитической группировки можно сделать вывод о прямой зависимости между численностью населения в торговой зоне и объемом продаж, поскольку с возрастанием значения признака-фактора растет значение признака-результата.
Комбинационная группировка строится по двум и более признакам и имеет цель проследить наличие зависимости между рассматриваемыми признаками и ее характер.
Пример 10.4.
Построение комбинационной группировки Пусть требуется построить комбинационную группировку по данным из примера 10.4.
Решение. Пусть количество групп соответствует трем; шаг каждого интервата соответствует значению 4 млн руб., полученному по формуле Д = (Xmzx — Xmin) / п = (38 — - 26) /3 = 4 млн руб. Пользуясь группировкой из примера 10.4, построим комбинационную группировку (табл. 10.13).
Комбинационная группировка
Таблица 10.13
Численность населения, тыс. чел. | Объем продаж, млн руб. | Итого. | ||
26−30. | 30−34. | 34−38. | ||
[1,6−1,9]. | ||||
(1,9−2,51. | ||||
(2,5−3,3]. | ||||
Итого. | ||||
Группировки делятся на первичные и вторичные в зависимости от видов используемой информации. Первичные группировки обычно строятся на основе собранных данных об изучаемом объекте. Вторичные представляют перегруппировку данных на основе уже существующих группировок путем укрупнения интервалов или перераспределения.
Еще одним статистическим методом, применяемым в обработке и анализе данных маркетинговых исследований, является построение рядов распределения, полигонов, кумулят и гистограмм. Числовой ряд, характеризующий структуру совокупности по некоторому признаку, называется рядом распределения.
Ряд распределения, но качественному признаку называется атрибутивным рядом распределения. Ряд распределения по количественному признаку называется вариационным. Ряды распределения строятся на основе структурных группировок. Вариационные ряды распределения, построенные по дискретному признаку, называются дискретными вариационными рядами, по непрерывному — интервальными. Основными элементами ряда распределения являются:
- — варианты распределения (X,) — отдельные значения признака совокупности;
- — объем совокупности (X);
— частота (/)) — численность элементов отдельной группы. Обязательным 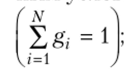 условием является равенство суммы всех частот объему совокупности.
условием является равенство суммы всех частот объему совокупности.
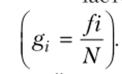
— чягтость (gj) — доля отдельной группы в общем объеме совокупности Обязательным условием является равенство суммы всех частостей единице 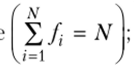
- — накопленная частота (Fj) — частота с нарастающим итогом, показывающая число элементов совокупности, индивидуальные значения которых не превышают значения признаков в группе;
- — накопленная частость (G,) — частость с нарастающим итогом показывает долю единиц совокупности, в которых значение признака меньше или равно значению признака в группе.
Графическим представлением дискретного вариационного частотного ряда является полигон, интервального вариационного ряда — гистограмма. Графики, построенные, но накопленным значениям признака, называются кумулятой распределения.
Расчет основных элементов вариационного ряда Пусть имеются данные по объемам продаж предприятий высокотехнологичной отрасли (табл. 10.14). Рассчитать основные элементы вариационного ряда распределения.
Выборка данных.
Таблица 10.14
Объем продаж, млн руб. | Количество предприятий. |
1−3. | |
3−5. | |
5−7. |
Объем продаж,. | Количество предприятий. |
млн руб. | |
7−9. | |
9−11. | |
11−13. | |
Итого. |
Решение. Рассчитаем основные элементы вариационного ряда распределения (табл. 10.15).
Таблица 10.15
Расчет основных элементов вариационного ряда распределения.
Объем продаж, Xj, млн руб. | Количество предприятий,. fi | Частость,. ft. | Накопленная частота,. | Накопленная частость,. |
1−3. | = 15/100 = 0,15. | = 15/100 = 0,15. | ||
3−5. | 0,3. | = 15 + 30 = 45. | = 45/ 100 = 0,45. | |
5−7. | 0,2. | = 45 + 20 = 65. | 0,65. | |
7−9. | 0,15. | 0,8. | ||
9−11. | 0,15. | 0,95. | ||
11−13. | 0,05. | |||
Итого. | ; | ; |
Множественная регрессия. Одним из инструментов маркетинговых исследований, позволяющих оценить степень зависимости результата от множества факторов, является построение множественной линейной регрессии. Выполнять эту процедуру вручную достаточно трудоемко.
Рассмотрим построение множественной регрессии в системе Statistica. Для начала работы необходимо создать новый файл и внести в него исходные данные. Командой All Variable Specs из меню Data ввести переменные объем продаж за текущий месяц 5; объем продаж за предыдущий месяц S1; расходы на рекламу в текущем месяце А; расходы на рекламу в предыдущем месяце Д1; число туристов в текущем месяце Г; средняя температура воздуха W; индекс розничных цен в текущем месяце Р. Имена переменных, например, 5, вводить в столбец Name, а комментарий, например, «объем продаж за текущий месяц», в столбец Long Name (label or formula). Ввести число наблюдений за 24 месяца, значения переменных, заголовки (рис. 10.6).
Для построения множественной регрессии необходимо выполнить команду Multiple Regression из меню Statistics, вкладка Advanced, кнопка Variables. Выбрать зависимые (Dependent) и независимые (Independent) переменные (рис. 10.7), OK, OK. Результаты стандартного множественного регрессионного анализа представлены на рис. 10.8.

Рис. 10.6. Исходные данные.
Рис. 10.7. Окно множественной регрессии.
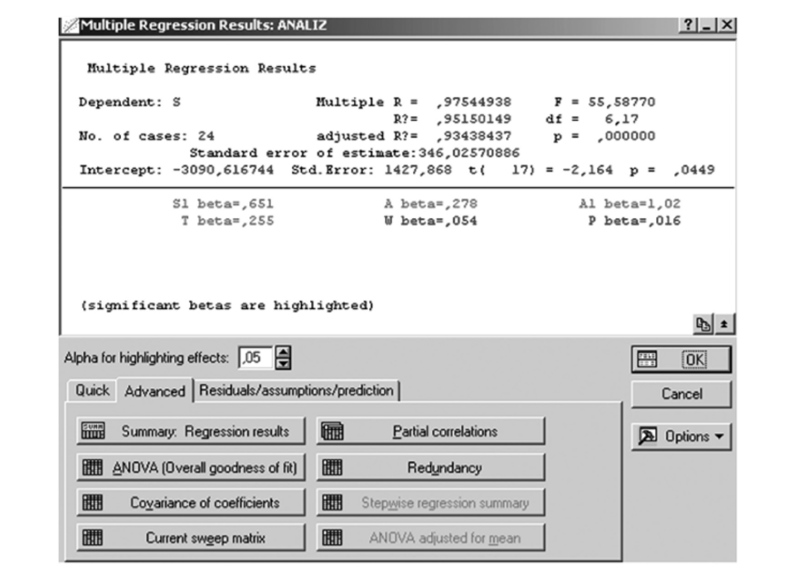
Рис. 10.8. Результат стандартной регрессии.
Нажать кнопку Cancel и изменить процедуру на пошаговую Stepwise (рис. 10.9), ОК. Выбрать метод на вкладке Advanced (рис. 10.10). Выбрать параметры пошаговой процедуры (рис. 10.11), ОК. Результат представлен на рис. 10.12.
Рис. 10.9. Пошаговый анализ.
Рис. 10.10. Выбор метода.
Рис. 10.11. Параметры пошаговой процедуры.
Для построения множественной регрессии пошаговым методом
необходимо щелкнуть по кнопке Summary. Regression Results на вкладке Advanced (рис. 10.12).
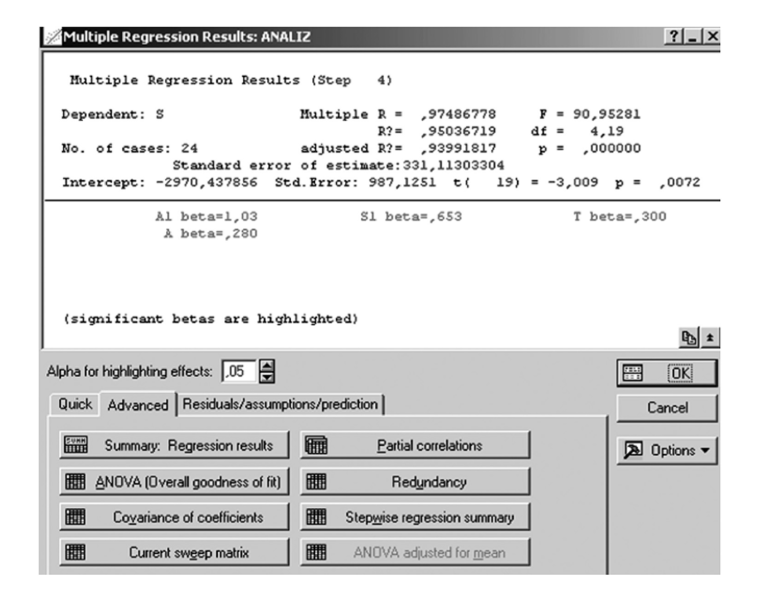
Рис. 10.12. Результат пошаговой регрессии.
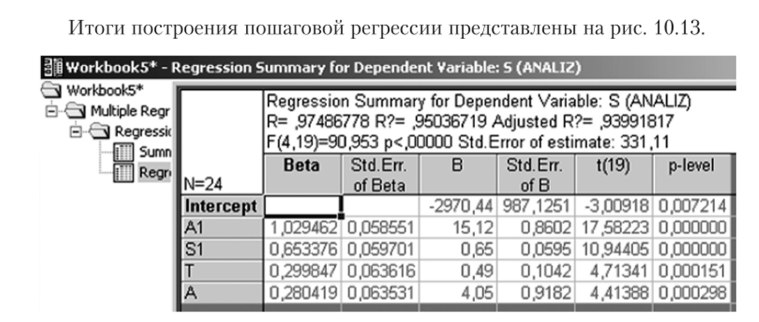
Рис. 10.13. Итоги пошаговой регрессии.
Для проверки на адекватность полученного уравнения регрессии необходимо провести исследование регрессионных остатков. Если выборочная регрессия удовлетворительно описывает истинную регрессионную зависимость, то регрессионные остатки должны быть независимыми, нормально распределенными случайными величинами с нулевым средним, и в их значениях должен отсутствовать тренд.
Для исследования регрессионных остатков в системе Statistica
необходимо вернуться в окно анализа, щелкнув по кнопке Multiple Regression. Произвести анализ остатков, щелкнув по кнопке Perform residual analysis на вкладке Residuals/'assumptions/prediction. Результат представлен на рис. 10.14.

Рис. 10.14. Анализ остатков Одним из критериев, позволяющих осуществить проверку независимости остатков, является критерий Дарбина — Уотсона. Область допустимых значений критерия описывается отрезком [0;4]. В случае если DW е [1,5;2,5], автокорреляция в остатках отсутствует и регресионная модель считается пригодной для использования. Для исследования зависимости между остатками и прогнозом щелкните по кнопке Durbin-Watson statistic на вкладке Advanced. Результат представлен на рис. 10.15.

Рис. 10.15. Итоги статистики Дарбина — Уотсона.
Для возвращения в окно анализа надо щелкнуть, но кнопке Residual Analysis. Затем — по кнопке Predicted vs. Observed на вкладке Scatteiplots. Результат представлен на рис. 10.16.
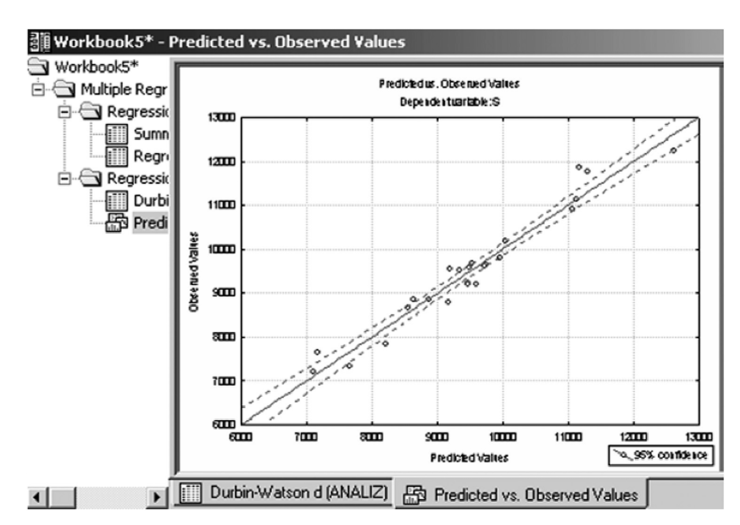
Рис. 10.16. Наблюдаемые и прогнозируемые значения.
Для прогноза показателя результата на основе построенной модели множественной регрессии необходимо вернуться в окно анализа, щелкнув по кнопке Residual Analysis, затем — по кнопке Cancel для того, чтобы вернуться в окно Model definition. Нажать кнопку Predict dependent variable на вкладке Residuals/assumptions/prediction. Ввести данные для прогноза на следующий месяц (рис. 10.17), щелкнуть по кнопке ОК. Результат представлен на рис. 10.18. Ожидаемый объем продаж 11 473,93 ед.
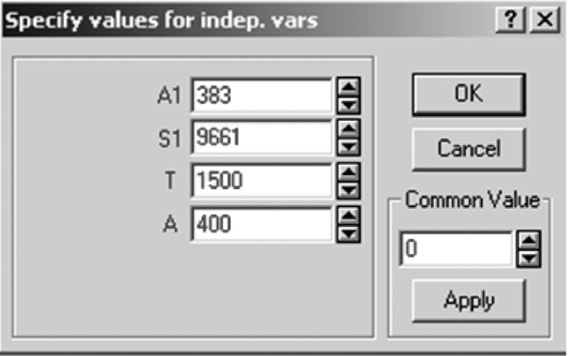
Рис. 10.17. Данные для прогноза.
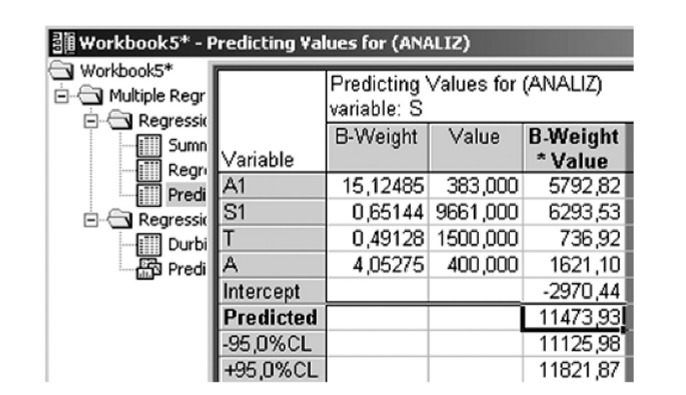
Рис. 10.18. Ожидаемый объем продаж.
- [1] Международная стандартная отраслевая классификация всех видов экономическойдеятельности. 4-я версия, 2009 г.
- [2] Справочник по прикладной статистике: в 2 т. / под ред. Э. Ллойда, У. Ледермана, IO. Н. Тюрина, С. А. Айвазяна. М.: Финансы и статистика, 1989; Интернет-портал компанииInterface ltd. URL: http://www.interface.ru/