Алгоритм К-средних.
Введение в анализ данных

Объекты, которые приписаны одному и тому же центру, формируют текущий кластер. Кластеры, найденные по табл. 4.10: S1 = {Ав, Ан, Ac}, S2 = {Бм, Бр, Бу}, и S3 = {Ви, By}. Приведенные кластеры соответствуют производимым продуктам. Метод К-средних подразумевает, что новые предполагаемые кластеры будут определяться теми же центрами. Проведите кластеризацию компаний, начиная с тех же объектов «Ан… Читать ещё >
Алгоритм К-средних. Введение в анализ данных (реферат, курсовая, диплом, контрольная)
- 0. Инициализация. Пользователь выбирает число К кластеров и назначает К гипотетических центров, см. рис. 4.11, а.
- 1. Обновление кластеров. При заданных К центрах ck (k = 1, 2,…, К), каждый объект ге/ приписывается одному из центров по правилу минимального расстояния: вычисляются расстояния от i до каждого ск, объект i приписывается ближайшему центру ск, см. рис. 4.11, б. Те объекты, которые приписаны центру ск, образуют кластер Sk (к = 1, 2,…, К), см. рис. 4.11, в. В качестве расстояния используется квадрат Евклидова расстояния.
- 2. Обновление центров. Вычисляется арифметический центр (центр масс) каждого кластера Sk, который и назначается новым центром ск (к = 1, 2,…, К), см. рис. 4.11, г. Компоненты центра вычисляются как средние арифметические соответствующих компонент объектов из Sk.
- 3. Правило остановки. Новые центры ск сравниваются со старыми. Если ск = ск Для каждого к = 1,2, …, К, то вычисления останавливаются и выдаются результаты: центр ск и кластер Sk для каждого к= 1, 2,…, К. Если же хотя бы одно из равенств не верно, то каждый центр ск заменяется вновь полученным центром ск, и процесс возвращается к шагу 1. «Обновление кластеров».
Модель суммаризации, лежащая в основе метода, предполагает, что каждый кластер представлен своим центром, иногда также называемым стандартной точкой, или прототипом кластера [17, 18 j. Прототип как бы концентрирует в себе всю информацию о кластере.
Нормализованные данные компаний из табл. 1.2.
Таблица 4.8
Ав. | — 0,20. | 0,23. | — 0,33. | — 0,63. | 0,36. | — 0,22. | — 0,14. |
Ан. | 0,40. | 0,05. | — 0,63. | 0,36. | — 0,22. | — 0,14. | |
Ас. | 0,08. | 0,09. | — 0,63. | — 0,22. | 0,36. | — 0,14. | |
Бм. | — 0,23. | — 0,15. | — 0,33. | 0,38. | 0,36. | — 0,22. | — 0,14. |
Бр | 0,19. | — 0,29. | 0,38. | — 0,22. | 0,36. | — 0,14. | |
Бу. | — 0,60. | — 0,42. | — 0,33. | 0,38. | — 0,22. | 0,36. | — 0,14. |
Ви. | 0,08. | — 0,10. | 0,33. | 0,38. | — 0,22. | — 0,22. | 0,43. |
Ву. | 0,27. | 0,58. | 0,67. | 0,38. | — 0,22. | — 0,22. | 0,43. |
Вклад. | 0,74. | 0,69. | 0,89. | 1,88. | 0,62. | 0,62. | 0,50. |
Вклад в % | 12,42. | 11,66. | 14,95. | 31,54. | 10,51. | 10,51. | 8,41. |
Примечание. Шаги нормализации: (i) вычитание из столбцов их средних значений, (и) затем деление столбцов на их размахи и (iii) дополнительное деление трех последних столбцов, отвечающих трем категориям признака «Сектор экономики», на 1з. Последняя строка: вклады признаков в исходные данные, вычисленные как суммы квадратов элементов соответствующего столбца.
Рабочий пример 4.1. Кластеризация данных «Компании» методом К-средних
Рассмотрим нормализованные данные о компаниях из табл. 1.2 (табл. 4.9). Данные могут быть визуализированы в пространстве двух главных компонент (рис. 4.12) [17]. Возьмем для примера объекты «Ан», «Бр» и «Ви» в качестве центров трех кластеров. Теперь мы можем сравнить каждый объект с центром, чтобы понять, какой центр ближе к каждому конкретному объекту. Для сравнения любых двух точек использован квадрат Евклидовой меры вычисления расстояний (табл. 4.9). Каждый объект приписывается ближайшему центру согласно правилу минимального расстояния (табл. 4.10), в которой представлены все расстояния между объектами и центрами; жирным выделены те из расстояний, которые вычислены с помощью правила минимального расстояния.
Таблица 4.9
Вычисление Евклидовой меры между строками «Ав» и «Ан» в табл. 4.8 как суммы квадратов разностей между соответствующими ячейками.
Точки. | Координаты. | d ( Аи, Ав). | ||||||
Ан. | 0,40. | 0,05. | 0,00. | — 0,63. | 0,36. | — 0,22. | — 0,14. | |
Ав. | — 0,20. | 0,23. | — 0,33. | — 0,63. | 0,36. | — 0,22. | — 0,14. | |
Ан-Ав. | 0,60. | — 0,18. | 0,33. | |||||
Квадраты. | 0,36. | 0,03. | 0,11. | 0,50. | ||||
Таблица 4.10
Расстояния между тремя компаниями — центрами и всеми остальными компаниями; каждый столбец матрицы показывает три расстояния между компанией и тремя центрами; наилучшие нары центр-компания выделены жирным.
Точка. | Ав. | Ан. | Ас. | Бм. | Бр | Бу. | В и. | Ву. |
Ан. | 0,50. | 0,00. | 0,77. | 1,55. | 1,82. | 2,99. | 1,90. | 2,41. |
_Б?_. | 2,20. | 1,82. | 1,16. | 0,97. | 0,00. | 0,75. | 0,83. | 1,87. |
Ви. | 2,30. | 1,90. | 1,81. | 1,22. | 0,83. | 1,68. | 0,00. | 0,61. |
Объекты, которые приписаны одному и тому же центру, формируют текущий кластер. Кластеры, найденные по табл. 4.10: S1 = {Ав, Ан, Ac}, S2 = {Бм, Бр, Бу}, и S3 = {Ви, By}. Приведенные кластеры соответствуют производимым продуктам. Метод К-средних подразумевает, что новые предполагаемые кластеры будут определяться теми же центрами.
Таблица 4.11
Предполагаемые кластеры и их центры, но табл. 4.10.
Ав. | — 0,20. | 0,23. | — 0.33. | — 0,63. | 0,36. | — 0,22. | — 0,14. |
Ан. | 0,40. | 0,05. | — 0,63. | 0,36. | — 0,22. | — 0,14. | |
Ас. | 0,08. | 0,09. | — 0,63. | — 0,22. | 0,36. | — 0,14. | |
Центр 1. | 0,10. | 0,12. | — 0.11. | — 0,63. | 0,17. | — 0,02. | — 0,14. |
Бм. | — 0,23. | — 0,15. | — 0.33. | 0,38. | 0,36. | — 0,22. | — 0,14. |
Бр | 0,19. | — 0,29. | 0,38. | — 0,22. | 0,36. | — 0,14. | |
Бу. | — 0,60. | — 0,42. | — 0.33. | 0,38. | — 0,22. | 0,36. | — 0,14. |
Центр 2. | — 0,21. | — 0,29. | — 0.22. | 0,38. | — 0,02. | 0,17. | — 0,14. |
Ви. | 0,08. | — 0,10. | 0.33. | 0,38. | — 0,22. | — 0,22. | 0,43. |
Bv. | 0,27. | 0,58. | 0.67. | 0,38. | — 0,22. | — 0,22. | 0,43. |
Центр 3. | 0,18. | 0,24. | 0.50. | 0,38. | — 0,22. | — 0,22. | 0,43. |
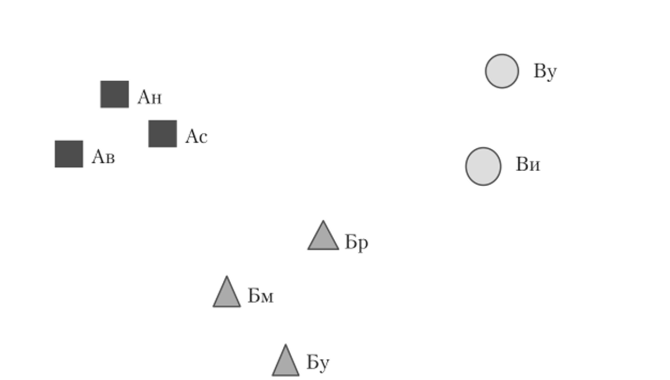
Рис. 4.12. Кластеры компаний, но нормализованным данным; они соответствуют выпускаемому продукту
Далее необходимо обновлять центры, используя информацию о текущих кластерах. Новые центры определены как их центры; компоненты центров — средние соответствующих компонент внутри кластеров, как показано в табл. 4.11.
Обновленные центры отличаются от центров предыдущего шага. Следовательно, повторяем итерацию метода К-средних. Для этого обновляются кластеры, используя расстояния между обновленными центрами и объектами (см. табл. 4.11). После этого получаем те же центры, так что объекты по правилу минимального расстояния будут приписаны тем же кластерам. Это означает, что процесс стабилизировался: новые итерации не могут ничего поменять. Процесс останавливается и возвращает найденные кластеры с центрами (в стандартизованной форме они представлены в табл. 4.11).
Таблица 4.12
Расстояния между тремя обновленными центрами и компаниями; наилучшие пары центр-компания выделены жирным.
Объект. | Ав. | Ан. | Ас. | Бм. | Бр | Бу. | Ви. | By. |
Центр 1. | 0,22. | 0,19. | 0,31. | 1,31. | 1,49. | 2,12. | 1,76. | 2,36. |
Центр 2. | 1,58. | 1,84. | 1,36. | 0,33. | 0,29. | 0,25. | 0,95. | 2,30. |
Центр 3. | 2,50. | 2,00. | 1,95. | 1,69. | 1,20. | 2,40. | 0,15. | 0,15. |
Очевидно, что данный результат сильно зависит от способа стандартизации данных, сделанной перед началом вычислений, так как метод основан на расстояниях — суммах квадратов разностей значений различных признаков, которые сильно зависят от выбранных масштабов.
Самостоятельная работа
- 4.5.1. Проведите кластеризацию компаний, начиная с тех же объектов «Ан», «Бр» и «Ви» в качестве центров трех кластеров, при условии, что стандартизация данных выполнена путем вычитания средних арифметических с последующим делением на стандартные отклонения признаков.
- 4.5.2. Проведите кластеризацию компаний на два кластера, начиная с объектов «Ан» и «Ви» в качестве центров кластеров, не меняя стандартизацию признаков табл. 4.9.