Упражнения с пояснениями

Применим два способа для решения проблемы гетероскедастичности. Первым способом является преобразование исходных переменных. Для этого создадим новые переменные. Получим 1,3 358 722. Поскольку значение тестовой статистики превышает критическое (при 5%-ном уровне значимости), то гипотеза о гомоскедастичности ошибок отвергается. Упражнение 10.1. С использованием статистического пакета Stata… Читать ещё >
Упражнения с пояснениями (реферат, курсовая, диплом, контрольная)
Упражнение 10.1. С использованием статистического пакета Stata по данным базы clothing о продажах одежды в 400 голландских магазинах мужской одежды выполним следующее.
1. Оценим коэффициенты уравнения регрессии.
sales = Р0 + fi{hoursi0 + р 2size + г.
- 2. Проведем тесты Уайта, Бройша — Нагана, Голдфслда — Квандта, Глейзера на выявление гетероскедастичности ошибок.
- 3. Если гетероскедастичность будет выявлена, то проведем коррекцию.
Решение. 1. Открыв файл clothing. csv в статистическом пакете Stata, оценим необходимую регрессию с помощью команды.
reg sales hoursw size Получим.
Source 1. | SS. | df. | MS. | Number of obs F (2, 397) Prob > F R-squared Adj R-squared Root MSE. | = 400 = 114.49 = 0.0000 = 0.3658 = 0.3626 = 2985.4. | |
Model I Residual 1. | 2.0409e+09 3.5382e+09. |
| 1.0204e+09 8 912 441.27. | |||
Total 1. | 5.5791e+09. | |||||
sales 1. | Coef . | Std. | Err. t. | P> 111. | [957, Conf. | Interval]. |
hoursw 1 size 1 .cons 1. |
| 2.83 722 13.23 1.625 067 -13.63 321.6934 15.96. |
|
|
| |
2. Для проведения теста Уайта после оценки регрессии необходимо набрать в командном окне.
I estat imtest, white.
Получим.
White’s test for Ho: homoskedasticity.
against Ha: unrestricted heteroskedasticity.
chi2(5) = 34.99.
Prob > chi2 = 0.0000.
Cameron & Trivedi’s decomposition of IM-test.
Source |. | chi2. | df. | P. |
Heteroskedasticity I. | 34.99. | 0.0000. | |
Skewness I. | 10.83. | 0.0045. | |
Kurtosis I. | 3.01. | 0.0826. | |
Total 1. | 48.83. | 0.0000. |
Поскольку p-value тестовой статистики равно 0,0000, то гипотеза о гомоскедастичности ошибок отвергается.
Для проведения теста Бройша — Пагана необходимо набрать в командном окне || estat hettest, rhs mtest.
Получим.
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity Ho: Constant variance.
Variable 1. | chi2. | df. | P. |
hoursw 1. | 24.85. | 0.0000. | |
size 1. | 0.21. | 0.6492. | |
simultaneous 1. | 41.41. | 0.0000. |
# unadjusted p-values.
Поскольку и для этого тестер-value равно 0,0000, то гипотеза о гомоскедастичности ошибок отвергается. Причем согласно выданной таблице следует тестировать зависимость дисперсии ошибок от переменной hoursw. Для проведения теста Глейзера сохраним остатки регрессии с помощью команды predict res, resid Создадим новые переменные е, у/hoursw,.
hoursw
с помощью команд.
gen modres = abs (res).
gen sqrthoursw = sqrt (hoursw).
gen invhoursw =1/hoursw.
Последовательно оценим коэффициенты трех регрессий | е | = а + fihoursw + г, | е = а + $ у/hoursw + е, | е | = а + -—-— + г.
hoursw
с помощью команд.
reg modres hoursw гeg modres sqrthoursw reg modres invhoursw.
Соответственно получим: для первой —.
Source. | SS. | df. | MS. | Number of obs F (1, 398) Prob > F R-squared Adj R-squared Root MSE. | = 400 = 7.48 = 0.0065 = 0.0185 = 0.0160 = 2079.7. | |||
Model. Residual. |
| 32 361 451 1.7215e+09. |
|
| ||||
Total. | 1.7538e+09. | 4 395 573. | ||||||
modres. | Coef . | Std. | Err. | t. | P> 11 |. | [957, Conf. | Interval]. | |
hoursw. .cons. |
|
| 1.615 838 2 221.6458 7. | .74. 11. |
|
|
| |
для второй ; | ||||||||
Source. | SS. | df. | MS. | Number of obs F (1, 398) Prob > F R-squared Adj R-squared Root MSE. | = 400 = 5.60 = 0.0184 = 0.0139 = 0.0114 = 2084.6. | |||
Model. Residual. |
| 24 353 314.2 1.7295e+09. |
|
| .2. | |||
Total. | 1.7538e+09. | 4 395 573. | ||||||
modres 1. | Coef . | Std. | Err. | t. | P> 111. | [957, Conf. | Interval]. |
sqrthoursw 1 _cons I. |
|
|
|
|
|
| |
для третьей ; | |||||||
Source I. | SS. | df. | MS. | Number of obs F (1, 398) Prob > F R-squared Adj R-squared Root MSE. | = 400 = 1.34 = 0.2475 = 0.0034 = 0.0009 = 2095.7. | ||
Model | Residual I. | 5 891 778.04 1.7479e+09. |
|
| ||||
Total I. | 1.7538e+09. | 4 395 573.89. | |||||
modres 1. | Coef . | Std. | Err. | t. | P> 111. | [957, Conf. | Interval]. |
invhoursw | _cons I. |
|
|
|
|
|
| |
Поскольку коэффициент р в первой регрессии значим, то гипотеза о гомоскедастичности ошибок отвергается.
Для проведения теста Голдфслда — Квандта упорядочим наблюдения, но переменной hoursw с помощью команды.
11 sort hoursw
Для того чтобы оценить параметры уравнения регрессии по первой и последней трети (приблизительно) наблюдений, наберем в командном окне.
|| reg sales hoursw size in 1/133
Используя RSS в последних двух оцененных регрессиях, рассчитаем (вручную) тестовую статистику по формуле.
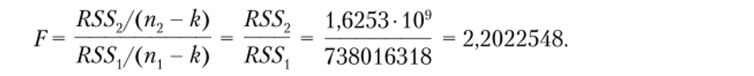
Критическое значение F-статистики можно найти с помощью команды display invFtail (130, 130, 0.05)
Получим 1,3 358 722. Поскольку значение тестовой статистики превышает критическое (при 5%-ном уровне значимости), то гипотеза о гомоскедастичности ошибок отвергается.
3. Применим два способа для решения проблемы гетероскедастичности. Первым способом является преобразование исходных переменных. Для этого создадим новые переменные.
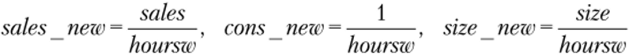
gen sales_new = sales/hoursw gen cons_new =l/hoursw gen size_new = size/hoursw.
с помощью команд Оценим коэффициенты новой регрессии.
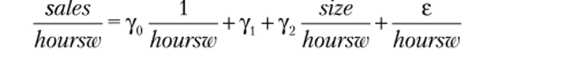
reg sales_new cons_new size_new Получим.
Source. | SS. | df. | MS. | Number of obs F (2, 397) Prob > F R-squared Adj R-squared Root MSE. | = 400. | |||
Model. Residual. |
|
|
|
| = 0.0000 = 0.3884 = 0.3853 = 29.587. | |||
Total. | 568 244.736. | .17 227. | ||||||
sales_new. | Coef . | Std. | Err . | t. | P>ltl. | [957. Conf. | Interval]. | |
cons.new. size_new. .cons. |
|
|
|
|
|
|
| |
Нужно быть внимательным при интерпретации оценок коэффициентов новой регрессии! Оценки коэффициентов^ = 3814,137, у, = 55,59,у2 = -26,63 будут эффективными оценками коэффициентов р0, р, р2 регрессии sales = р0 + рJioursw + + р 2size + е.
Вторым способом решения проблемы гетероскедастичности ошибок является использование оценок Уайта для дисперсий коэффициентов. Их можно рассчитать с помощью команды.
|| reg sales hoursw size, robust.
Получим.
Number of obs =. | |
F (2, 397) =. | 44.86. |
Prob > F =. | 0.0000. |
R-squared =. | 0.3658. |
Root MSE =. | 2985.4. |
Linear regression.
Robust.
sales I. | Coef . | Std. Err. | t. | P> 111. | [957. Conf . | Interval]. |
hoursw 1. | 37.52 842. | 4.122 108. | 9.10. | 0.000. | 29.42 453. | 45.63 231. |
size I. | — 22.14 457. | 2.800 518. | — 7.91. | 0.000. | — 27.65 027. | — 16.63 887. |
.cons 1. | 5133.59. | 387.7822. | 13.24. | 0.000. | 4371.227. | 5895.953. |
Отметим, что хотя качественная картина при коррекции гетероскедастичности не изменилась (при увеличении размера магазина продажи в расчете на квадратный метр уменьшаются, при увеличении общего числа отработанных работниками часов — увеличиваются), оценки стандартных отклонений при использовании двух описанных выше методов корректировки изменились.
Упражнение 10.2. Используя данные базы flats, с помощью статистического пакета R оценим модель Inprice_metrl = ро + р, *1пlivespi + Р2• Inkitsp{ + Р3— Indistf + + Р4 * In metrdisti + eit i = 1,…, n, где n — количество наблюдений, Inprice_metr — логарифм стоимости квадратного метра квартиры (описание остальных переменных приведено в приложении 1). Проведем тестирование гетероскедастичности ошибок для этой модели с помощью тестов Голдфелда — Кванта, Уайта и Бройша — Пагана.
Решение. Импортируем файл с данными flats. csv, как это делалось в предыдущих главах. Загрузим сразу пакеты Imtest и sandwich:
|| install. packages (с («Imtest», «sandwich»)) reg <- lra (ln_price_metr ~ 1 + ln_livesp + ln_kitsp + ln_dist + lnjnetrdist, data = data_flats).
Проведем тест Голдфелда — Квандта с помощью следующей команды:
I gqtest (reg, point = 0.5).
Получим
Goldfeld-Quandt test data: reg.
GQ = 1.753, dfl = 246, df2 = 245, p-value = 6.392e-06.
Тест Голдфелда — Квандта реализован в пакете Imtest в форме, немного отличной от той, которая рассказана в тексте главы. В данной версии теста сравниваются лишь две части выборки, а не три. Заинтересованный читатель может сам запрограммировать тест необходимым образом. Исходя из результатов теста гетероскедастичность в модели присутствует.
Теперь проведем тест Уайта. Поскольку данный тест отсутствует в пакетах, то запрограммируем его сами.
Сначала сохраним квадрат остатков оригинальной регрессии:
|| u_sq <_ reg$residuals~2.
Теперь оценим регрессию квадратов остатков на оригинальные переменные, их квадраты и их cross-terms (попарные произведения) и сохраним R2 из этой модели:
R_sq <- summary (lm (u_sq ~ 1 + ln_livesp + ln_kitsp + ln_dist + lnjnetrdist + ln_livesp_sq + ln_kitsp_sq + ln_dist_sq + ln_metrdist_sq + ln_livesp * ln_kitsp + ln_livesp * ln_dist + ln_livesp * lnjnetrdist + ln_kitsp * ln_dist + ln_kitsp * lnjnetrdist + ln_dist * lnjnetrdist, data = data_flats))$r.squared.
Теперь рассчитаем p-value для этого теста с помощью следующих команд:
LM <- dim (data)[1]*R_sq p_value <- 1 — pchisq (LM, 14) p_value.
Получим
[1] 5.55 1115e-16.
Исходя из полученных результатов, можно заключить, что нулевая гипотеза
0 гомоскедастичности ошибок отвергается.
Проведем тест Бройша — Пагана, предположив, что остатки зависят от оригинальных регрессоров, с помощью команды
1 bptest (reg).
Получим
studentized Breusch-Pagan test data: reg.
BP = 69.195, df = 4, p-value = 3.357e-14.
Опять получилось, что в модели присутствует гетероскедастичность. Поскольку все три теста дали однозначный результат, что гетероскедастичность есть, то необходимо провести коррекцию. Для этого используем оценки стандартных отклонений в форме Уайта. Команда vcovHC из пакета sandwich позволяет оце-
нить робастную ковариационную матрицу (по умолчанию используется вариант НСЗ), а команда coeftest из пакета Imtest позволяет оценить значимость коэффициентов, используя робастную ковариационную матрицу.
Применив эти команды:
|| coeftest (reg, vcov = vcovHC (reg)).
получаем.
t test of coefficients:
Estimate. | Std. Error. | t value. | PrOltl). | ||
(Intercept). | 13.513 481. | 0.253 623. | 53.2817 < 2.2e-16. | ***. | |
ln_livesp. | — 0.211 379. | 0.76 129. | — 2.7766. | 0.5 701. | **. |
ln_kitsp. | 0.13 885. | 0.29 957. | 0.4635. | 0.643 221. | |
ln_dist. | — 0.258 789. | 0.23 006. | — 11.2488 < 2.2e-16. | ***. | |
ln_metrdist. | — 0.82 927. | 0.13 303. | — 6.2336 9.756e-10. | ***. | |
Signif. codes: 0 '***. | ' 0.001 '**. | * «—I. о о. | о о. сл. | 1 0.1. | |
Теперь сопоставим полученные результаты с результатами оценки оригинальной регрессии с помощью команды.
|| summary (reg).
Получим.
Call:
lm (formula = ln_price_metr — 1 + ln_livesp + ln_kitsp + ln_dist + ln_metrdist, data = data).
Residuals:
Min IQ Median 3Q Max.
— 0.65 287 -0.8 929 0.854 0.9 527 0.60 461.
Coefficients :
Estimate Std. Error t value Pr (>ItI).
(Intercept) 13.51 348 ln_livesp -0.21 138 ln_kitsp 0.1 388 ln_dist -0.25 879 ln_metrdist -0.8 293.
* * * ***.
***.
***.
0.17 326 77.996 < 2e-16 0.5 282 -4.002 7.25e-05 0.2 955 0.470 0.639 0.2 304 -11.230 < 2e-16 0.1 367 -6.068 2.58e-09.
Signif. codes:
- 0 '***' 0.001 '**' 0.01 0.05 0.1
- 1
Residual standard error: 0.1761 on 496 degrees of freedom Multiple R-squared: 0.2638, Adjusted R-squared: 0.2579 F-statistic: 44.43 on 4 and 496 DF, p-value: < 2.2e-16.
Можно заметить, что для двух моделей существует разница в оценках стандартных отклонений коэффициентов (хотя и в этом случае качественная картина не меняется, но так бывает не всегда).