Сводка и группировка данных статистического наблюдения

Существуют различные способы разбиения заданной совокупности элементов на классы. Для того чтобы определить сравнительное качество различных способов разбиения заданной совокупности элементов на классы, т. е. определить тот количественный критерий, следуя которому можно было бы предпочесть одно разбиение другому, в постановку задачи кластерного анализа часто вводится понятие так называемого… Читать ещё >
Сводка и группировка данных статистического наблюдения (реферат, курсовая, диплом, контрольная)
В результате проведения статистического наблюдения получают массивы данных, содержащие сведения о признаках каждой обследованной единицы статистической совокупности. Однако целью статистического исследования является не получение характеристик единиц совокупности, а изучение совокупности в целом. Для этого необходимо обобщить и систематизировать полученные в ходе статистического наблюдения сведения.
Таким образом, после проведения статистического наблюдения, являющегося первым этапом статистического исследования, переходят ко второму этапу — этапу сводки и группировки статистических данных. Основной задачей данного этапа является получение полной и всесторонней характеристики как совокупности в целом, так и отдельных ее частей и представление полученной информации об изучаемой совокупности в удобной для пользователей форме.
Статистическая сводка — систематизация единичных фактов, позволяющая перейти к обобщающим показателям, относящимся ко всей изучаемой совокупности и ее частям, и осуществлять анализ и прогнозирование изучаемых явлений и процессов.
Сводка может быть простой или сложной.
Простая сводка — это операция подсчета общих итогов по совокупности единиц наблюдения и оформление этого материала в таблицах. Простая сводка проводится без распределения полученных сведений на группы.
Сложная сводка — это комплекс операций, включающих группировку единиц наблюдения, подсчет итогов по каждой группе и по всему объекту и представление результатов в виде статистических таблиц.
Полнота, обоснованность и достоверность результатов сводки обеспечивается программой и планом ее проведения.
Проведение сводки обязательно включает следующие этапы:
- • выбор группировочного признака;
- • определение порядка формирования групп;
- • разработка системы статистических показателей для характеристики групп и объекта в целом;
- • разработка макетов статистических таблиц для представления результатов сводки.
По форме обработки материала статистическая сводка бывает:
централизованной — это способ организации сводки статистических данных, при котором весь первичный материал поступает в одну организацию, подвергается в ней обработке от начала до конца;
децентрализованной — это способ организации сводки статистических данных, при котором обобщение материала осуществляется снизу доверху по иерархической лестнице управления, подвергаясь на каждом уровне соответствующей обработке, т. е. отчеты предприятий сводятся статистическими органами субъектов РФ, а полученные итоги поступают в Федеральную службу государственной статистики и там определяются итоговые показатели в целом по народному хозяйству страны.
По технике выполнения статистическая сводка бывает:
- • механизированная (с использованием электронно-вычислительной техники);
- • ручная.
Группировкой называется расчленение единиц изучаемой совокупности на однородные группы по определенным существенным для них признакам. Например, признак квалификации продавцов представлен тремя категориями: первой, второй, третьей. При расчленении совокупности продавцов по этому признаку получают группы работников по квалификации. Их можно дифференцировать и, но стажу работы. Однако и здесь, систематизировав всю численность продавцов по признаку стажа работы, их можно объединить в отдельные группы, например с пятилетним интервалом: до 5 лет, от 5 до 10 и т. д.
Виды группировок представлены на рис. 2.7.
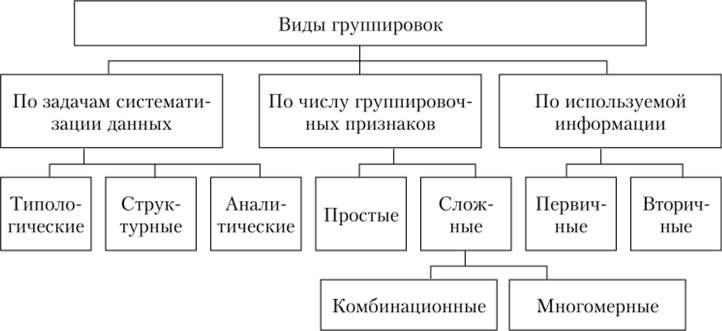
Рис. 2.7. Виды группировок.
По задачам систематизации данных различают следующие виды группировок.
- 1. Типологические — предназначены для выявления качественно однородных групп совокупностей, т. е. объектов, близких друг к другу по всем группировочным признакам, т. е. типологические группировки служат для характеристики социально-экономических типов.
- 2. Структурные — характеризуют структуру совокупности по какомулибо одному признаку.
- 3. Аналитические — предназначены для выявления зависимости между признаками.
Примером типологической группировки может служить группировка стран по уровню социально-экономического развития (развитые страны, развивающиеся страны, страны с переходной экономикой), группировка предприятий по формам собственности, по отраслям экономики, социальные группы населения и т. д. Пример такой группировки представлен в табл. 2.1.
Таблица 2.1
Индексы производительности труда в экономике РФ в 2013 г.
(в % к предыдущему году).
Отрасль. | Значение индекса. |
Сельское хозяйство, охота и лесное хозяйство. | 106,0. |
Рыболовство, рыбоводство. | 103,2. |
Добыча полезных ископаемых. | 96,9. |
Обрабатывающие производства. | 105,5. |
Производство и распределение электроэнергии, газа и воды. | 99,2. |
Строительство. | 98,3. |
Оптовая и розничная торговля; ремонт автотранспортных средств, мотоциклов, бытовых изделий и предметов личного пользования. | 100,1. |
Гостиницы и рестораны. | 101,9. |
Транспорт и связь. | 103,6. |
Операции с недвижимым имуществом, аренда и предоставление услуг. | 101,8. |
Источник: официальный сайт ФСГС. URL: http://www.gks.ru/wps/wcm/connect/ rosstat_main/rosstat/ru/statistics/efficiency/#.
Примером структурной группировки может служить группировка обязательств предприятия по степени срочности их оплаты, состав товарооборота по товарным группам и др. В качестве примеров структурной группировки приведем структурную группировку денежных доходов населения по основным источникам их формирования (табл. 2.2) и группировку населения по возрастным группам (табл. 2.3).
Структура денежных доходов населения по основным источникам их формирования в целом по России за 2013 г. (в % к итогу).
Денежные доходы — всего. | В том числе. | ||||
доходы от предпринимательской деятельности. | оплата труда. | социальные выплаты. | доходы от собственности. | другие доходы (включая скрытую заработную плату). | |
100,0. | 8,6. | 41,4. | 18,6. | 5,5. | 25,9. |
Таблица 23
Источник: официальный сайт ФСГС. URL: http://www.gks.ru/free_doc/new_site/ population/bcdnost/tabl/1−1 -2.htm.
Распределение населения РФ по возрастным группам (на 1 января 2014 г.), тыс. чел.
Возрастные группы. | Численность. |
Все население. | 143 667. |
в том числе в возрасте, лет: | |
0−4. | |
5−9. | |
10−14. | |
15−19. | |
20−24. | |
25−29. | 12 522. |
30−34. | 11 661. |
35−39. | 10 614. |
40−44. | |
45−49. | |
50−54. | 11 184. |
55−59. | 10 634. |
60−64. | |
65−69. | |
70 и более. | 13 587. |
Источник: официальный сайт ФСГС. URL: http://www.gks.ru/wps/wcm/connect/ rosstat_main/rosstat/ru/statistics/population/demography/#.
Явления и процессы, происходящие в общественной жизни, взаимосвязаны, взаимозависимы, взаимообусловлены. Некоторые из них между собой связаны непосредственно, другие — косвенно. При проведении факторного анализа необходимо строить аналитические группировки, когда перед исследователями ставится задача выявить связи между двумя признаками (например, как зависит производительность труда от фондовооруженности или как зависит доходность акций компании от среднерыночной доходности). При изучении взаимосвязей тот показатель, который рассматривается как результат действия одной или нескольких причин и выступает в качестве объекта исследования, называется результативным показателем. Показатели, определяющие поведение результативного показателя, называются факторными. Например, при изучении зависимости производительности труда от фондовооруженности производительность труда выступает в качестве результативного показателя, а фондовооруженность — в качестве факторного показателя.
Пример аналитической группировки приведен в табл. 2.4.
Таблица 2.4
Характеристика зависимости рентабельности активов от продолжительности оборота активов предприятия.
Продолжительность оборота активов, дни. | ||||||
Рентабельность активов, %. | 14,2. | 15,7. | 20,3. | 28,3. | 27,0. | 33,2. |
В данном примере продолжительность оборота активов — факторный показатель, рентабельность активов — результативный показатель.
Группировка первичных данных может осуществляться по одному или нескольким признакам.
По числу группировочных признаков различают:
- • простые группировки — группировка проводится по одному признаку;
- • сложные группировки — группировка проводится, но двум или более признакам.
В случае простой группировки из множества признаков, описывающих объект, отбирается один, наиболее информативный с точки зрения исследователя, и производится группировка в соответствии со значениями данного признака. Примером простой группировки может служить распределение населения на группы, но одному признаку — величине среднедушевых денежных доходов (табл. 2.5).
Таблица 2.5
Распределение населения РФ на группы по величине среднедушевых денежных доходов в 2014 г., %
Величина среднедушевых денежных доходов. | Доля. |
Все население. | |
в том числе со среднедушевыми денежными доходами в месяц, руб.: | |
до 5000,0. | 3,3. |
Величина среднедушевых денежных доходов. | Доля. |
от 5000,1 до 7000,0. | 4,8. |
от 7000,1 до 9000,0. | 6,1. |
от 9000,1 до 12 000,0. | 10,0. |
от 12 000,1 до 15 000,0. | 9,9. |
от 15 000,1 до 20 000,0. | 14,4. |
от 20 000,1 до 25 000,0. | 11,4. |
от 25 000,1 до 30 000,0. | 8,8. |
от 30 000,1 до 35 000,0. | 6,7. |
от 35 000,1 до 40 000,0. | 5,1. |
от 40 000,1 до 50 000,0. | 7,0. |
от 50 000,1 до 60 000,0. | 4,2. |
свыше 60 000,0. | 8,3. |
Источник: официальный сайт ФСГС. IJRL: http://www.gks.ru/wps/wcm/connect/ rosstat_main/ rosstat / ru/stat istics/populat ion/level / #.
В сложных группировках выделяют:
- • комбинационные группировки — строятся путем разбивки каждой группы на подгруппы в соответствии с дополнительными признаками;
- • многомерные группировки — проводятся не последовательно по отдельным признакам, а одновременно по большому числу признаков. Данные группировки строятся с помощью специальных алгоритмов. Каждому признаку придается смысл координаты. Если в наборе п признаков, то каждый объект рассматривается как точка в и-мерном пространстве, и задача сводится к выделению сгущений точек в этом пространстве. Нахождение этих групп осуществляется методами кластерного анализа. Простейшим вариантом многомерной классификации является группировка на основе многомерных средних.
Если требуется провести классификацию по нескольким признакам, ранжированным между собой по степени важности, строятся комбинационные группировки. Для этого сначала производится группировка по первому признаку, затем каждая из полученных групп разбивается на подгруппы по второму признаку и т. д.
Комбинационные группировки бывают произвольные и иерархические. В произвольной группировке очередность разбиения совокупности на группы выбирается произвольно. Примером произвольной комбинационной группировки может служить табл. 2.6.
В иерархической группировке порядок разбиения совокупности по признакам четко определен и диктуется самой логикой изучаемой совокупности. Примером иерархической группировки может служить группировка институциональных единиц по секторам экономики (табл. 2.7).
Уровень средней заработной платы педагогических работников дошкольных образовательных учреждений в организациях государственной и муниципальной форм собственности по субъектам РФ за январь — март 2015 г.
Регион. | Средняя заработная плата, руб. | |||
Всего. | В том числе по формам собственности организаций: | |||
федеральная. | субъектов РФ. | муниципальная. | ||
Российская Федерация. | 24 513. | 20 663. | 35 306. | 23 894. |
Центральный федеральный округ. | 25 128. | 23 544. | 27 265. | 25 134. |
Северо-Западный федеральный округ. | 31 304. | 26 237. | 39 667. | 26 764. |
Южный федеральный округ. | 19 484. | 16 735. | 18 749. | 19 493. |
СсвероКавказски й федеральный округ. | 16 832. | 18 229. | 17 766. | 16 784. |
Приволжский федеральный округ. | 20 789. | 17 287. | 21 571. | 20 760. |
Уральский федеральный округ. | 28 649. | 20 711. | 31 878. | 28 660. |
Сибирский федеральный округ. | 23 795. | 19 552. | 23 616. | 23 818. |
Дальневосточный федеральный округ. | 35 297. | 28 980. | 43 975. | 35 344. |
Крымский федеральный округ. | 18 217. | 18 884. | …". | 17 942. |
О Данные не публикуются в целях обеспечения конфиденциальности первичных статистических данных, полученных от единственных организаций в соответствующей сфере деятельности в отдельных субъектах РФ в соответствии с Федеральным законом «Об официальном статистическом учете и системе государственной статистики в Российской Федерации» (ст. 4, 9).
Источник: официальный сайт ФСГС. URL: http://www.gks.ru/free_doc/new_site/ population/trud/itog_monitor/itog-monitor l-15.html.
Таблица 2.7
Группировка институциональных единиц по секторам экономики.
Код. | Наименование. |
S.1. | Экономика в целом. |
S.11. | Нефинансовые корпорации. |
S.111. | Государственные нефинансовые корпорации. |
Код. | Наименование. |
S.112. | Национальные частные нефинансовые корпорации. |
S.113. | Нефинансовые корпорации под иностранным контролем. |
S.12. | Финансовые корпорации. |
S.121. | Банк России. |
S.122. | Другие депозитные корпорации. |
S.1221. | Государственные депозитные корпорации. |
S.1222. | Национальные частные депозитные корпорации. |
S.1223. | Депозитные корпорации под иностранным контролем. |
S.123. | Другие финансовые посредники (кроме страховых корпораций и негосударственных пенсионных фондов). |
S.1231. | Г осударственн ые. |
S.1232. | Национальные частные. |
S.1233. | Под иностранным контролем. |
S.124. | Вспомогательные финансовые организации. |
S.125. | Страховые корпорации и негосударственные пенсионные фонды. |
S.1251. | Государственные страховые корпорации. |
S.1252. | Национальные частные страховые корпорации и негосударственные пенсионные фонды. |
S.1253. | Страховые корпорации и негосударственные пенсионные фонды под иностранным контролем. |
S.13. | Государственное управление. |
S.131. | Федеральные органы государственной власти и управления. |
S.132. | Органы государственной власти и управления субъектов Федерации. |
S.133. | Органы местного самоуправления. |
S.134. | Фонды государственного социального обеспечения. |
S.14. | Домашние хозяйства. |
S.15. | Некоммерческие организации, обслуживающие домашние хозяйства. |
S.2. | ОСТАЛЬНОЙ МИР. |
S.21. | Содружество независимых государств. |
S.22. | Дальнее зарубежье. |
Источник: КИЕС — Классификатор институциональных единиц, но секторам экономики (с учетом изменений 1/2007, 2/2008 и 3/2011).
Наиболее простым методом многомерной группировки, применяемым в тех случаях, когда не представляется возможным упорядочить группировочные признаки, является создание интегрального показателя (индекса), функционально зависящего от исходных признаков, с последующей классификацией, но этому показателю. Развитием этого подхода является вариант классификации, но нескольким обобщающим показателям (главным компонентам), полученным с помощью методов факторного или компонентного анализа.
При наличии нескольких признаков (исходных или обобщенных) задача группировки может быть решена методами кластерного анализа.
Рассмотрим основные понятия кластерного анализа.
На первом этапе должна быть сформулирована цель работы. Дачее необходимо определить критерии качества, целевую функцию, значения которой позволят сопоставить различные схемы группировки. В экономических исследованиях целевая функция, как правило, должна минимизировать некоторый параметр, определенный на множестве объектов (например, целью классифицировать оборудование может явиться группировка, минимизирующая совокупность затрат времени и средств на ремонтные работы).
Не во всех случаях удается формализовать цель задачи. Тогда критерием качества группировки может служить возможность содержательной интерпретации найденных групп.
Предположим, что исследуемая совокупность состоит из п объектов. Каждый из объектов характеризуется k признаками. Нашей задачей является разделение исследуемой совокупности па однородные в некотором смысле группы. При этом практически отсутствует априорная информация о характере распределения измерений признаков внутри групп. Группы, которые будут получены в результате разбиения, называют кластерами, а методы нахождения этих групп — кластерным анализом.
Исходные данные в задачах кластерного анализа представляются в виде матрицы.
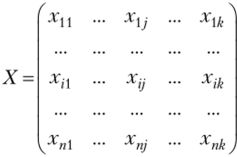
Каждая строка данной матрицы представляет собой результат измерений к рассматриваемых признаков на одном из обследованных объектов. Таким образом, количество строк данной матрицы равно числу объектов совокупности (п), количество столбцов равно числу наблюдаемых признаков.
Исходная информация наряду с заданием матрицы X может быть задана в виде матрицы расстояний (или близостей):
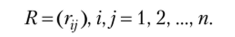
Каждый элемент матрицы близостей (г^) определяет степень близости объекта совокупности i к объекту совокупности j.
Отметим, что в большинстве алгоритмов кластерного анализа исходят из матрицы близостей. Поэтому если данные исследования представлены в виде матрицы X, то первым этапом поиска кластеров будет выбор способа вычисления расстояний (близостей) между объектами совокупности. В каждом случае выбор производится по-своему и зависит от цели исследования, физической и статистической природы вектора наблюдений Xt (вектором наблюдений назовем строку матрицы X), априорных сведений о характере распределения X. Выбор меры близости является узловым моментом исследования, так как от него в основном зависит окончательный вариант разбиения объектов на классы.
Наиболее широкое распространение в задачах кластерного анализа получили следующие меры расстояния (близости).
- 1. Обычное евклидово расстояние, использование которого оправдано в следующих случаях:
- а) наблюдения берутся из генеральной совокупности, имеющей многомерное нормальное распределение с ковариационной матрицей вида о2Ек (Ек — единичная матрица), т. е. компоненты X взаимно независимы и имеют одну и ту же дисперсию;
- б) компоненты вектора наблюдений X, однородны по физическому смыслу и одинаково важны для классификации;
- в) признаковое пространство совпадает с геометрическим пространством.
Расстояние между объектами совокупности в данном случае вычисляется, но формуле.
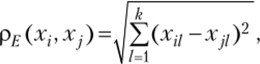
где Хф Xji — величины компоненты / (наблюдаемого признака) у объектов i и j соответственно, i, j =1,2,…, п.
В случае, когда наблюдаемые признаки измеряются в разных единицах, евклидово пространство, естественное с геометрической точки зрения, с точки зрения содержательной интерпретации оказывается бессмысленным. В этих случаях прибегают к нормированию каждого признака путем деления центрированной величины на среднее квадратическое отклонение и переходят от матрицы X к нормированной матрице, элементы которой вычисляются по формуле.
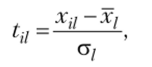
где Хц— значение признака / у объекта i; xt — среднее значение признака /; G/ — среднее квадратическое отклонение признака /, определяемое по формуле.
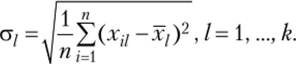
Подробно понятие и методика расчета среднего квадратического (стандартного) отклонения будут рассмотрены в гл. 5 учебника.
Отметим, что если кластеры хорошо разделены по одному признаку и не разделены по другому, то после нормирования дискриминирующие возможности первого признака будут уменьшены в связи с увеличением «шумового» эффекта второго, и операция нормирования приведет к нежелател ь н ы м п оследствия м.
2. Взвешенное евклидово расстояние, которое применяется в случаях, когда каждой компоненте xt (/ = 1, 2, …, k) вектора наблюдений X, можно задать некоторый весовой коэффициент со/, пропорциональный степени важности признака в задаче классификации. Обычно весовой коэффициент принимает значения от нуля до единицы. Определение весовых коэффициентов, как правило, связано с дополнительными исследованиями.
Расстояние между объектами совокупности в данном случае вычисляется по формуле.
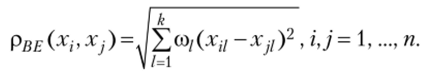
3. Хеммингово расстояние используется как мера различия объектов, задаваемых дихотомическими (альтернативными) признаками. Расстояние между объектами совокупности в данном случае равно числу несовпадений значений соответствующих признаков в рассматриваемых i-м и j-м объектах и вычисляется по формуле.
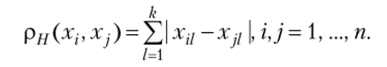
В некоторых задачах классификации объектов в качестве меры близости объектов можно использовать физические содержательные параметры, так или иначе характеризующие взаимоотношения между объектами. В качестве примера можно привести задачу классификации отраслей народного хозяйства с целью агрегирования, решаемую на основе матрицы межотраслевого баланса. Объектом классификации в данной задаче является отрасль народного хозяйства. Матрица межотраслевого баланса представлена элементами а1}, характеризующими затраты продукции отрасли г на производство продукции отрасли j. В качестве меры близости (г") принимают симметризованную нормированную матрицу межотраслевого баланса. С целью нормирования денежное выражение поставок г-й отрасли в j-ю заменяют долей этих поставок по отношению ко всем поставкам i-й отрасли. Симметризацию же нормированной матрицы межотраслевого баланса можно проводить, выразив близость между г-й и j-й отраслями через среднее значение из взаимных поставок, так что в этом случае г^ = г]{ | 15].
Как правило, решение задач классификации многомерных данных предусматривает в качестве предварительного этапа исследования реализацию методов, которые позволяют выбрать из компонент х{, х2, х^ наблюдаемых векторов Xj сравнительно небольшое число наиболее существенно информативных и тем самым уменьшить размерность наблюдаемого пространства.
В ряде процедур классификации (кластер-процедур) используют понятия расстояния между группами объектов и меры близости двух групп объектов.
Пусть 5, — г-я группа (класс, кластер), состоящая из п,• объектов; —.
среднее арифметическое векторных наблюдений группы Sh т. е. «центр тяжести» г-й группы; р (5), Sm) — расстояние между группами 5/ и Sm.
Наиболее часто употребляются следующие расстояния и меры близости между классами объектов:
• расстояние, измеряемое по принципу «ближайшего соседа»,.
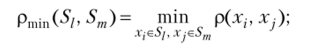
• расстояние, измеряемое по принципу «дальнего соседа»,.
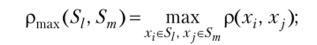
• расстояние, измеряемое по «центрам тяжести» групп:
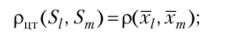
• расстояние, измеряемое по принципу «средней связи»,.
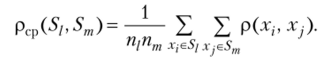
Академик А. Н. Колмогоров предложил «обобщенное расстояние» между классами, включающее в себя в качестве частных случаев все рассмотренные выше виды расстояний.
Расстояния между группами элементов особенно важно в так называемых агломеративных иерархических кластер-процедурах, так как принцип работы таких алгоритмов состоит в последовательном объединении элементов, а затем и целых групп, сначала самых близких, а затем все более и более отдаленных друг от друга.
При этом расстояние между классом S/ и классом S (,", q), являющимся объединением двух других классов Sm и Sq, можно определить по формуле.
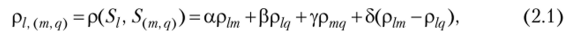
где р,т =р (5/, 5,"), plq =р (5/, Sq), pmq=p (Sm, Sq) — расстояния между классами 5/, Sni и Sq; а, р, б и у — числовые коэффициенты, значения которых определяют специфику процедуры, ее алгоритм.
Например, при, а = |3 = -8=½иу = 0 приходим к расстоянию, построенному по принципу «ближайшего соседа»; при, а = р = б=½иу = 0 расстояние между классами определяется по принципу «дальнего соседа», т. е. как расстояние между двумя самыми дальними элементами этих классов; п п
при, а =--—; Р =--—; у = б = 0 расстояние между классами определя;
nm+nq nm+nq
ется как рср, вычисленное как среднее из расстояний между всеми парами элементов, один из которых берется из одного класса, а другой — из другого.
Существуют различные способы разбиения заданной совокупности элементов на классы. Для того чтобы определить сравнительное качество различных способов разбиения заданной совокупности элементов на классы, т. е. определить тот количественный критерий, следуя которому можно было бы предпочесть одно разбиение другому, в постановку задачи кластерного анализа часто вводится понятие так называемого функционала качества разбиения, определенного на множестве всех возможных разбиений. Отметим, что существует много разновидностей функционалов качества кластеризации (например, в качестве функционала качества может быть принята сумма («взвешенная») внутриклассовых дисперсий, сумма попарных внутриклассовых расстояний между элементами и др.). Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается на эмпирические соображения. Наилучшим разбиением считается такое, которое обеспечивает экстремум выбранного функционала качества.
Наиболее распространенными алгоритмами кластерного анализа являются иерархические процедуры, которые бывают двух типов: агломеративные и дивизимные. В агломеративных процедурах начальным является разбиение, состоящее из п одноэлементных классов, а конечным — из одного класса; вдивизимных — наоборот.
Принцип работы иерархических агломеративных (дивизимных) процедур состоит в последовательном объединении (разделении) групп элементов сначала самых близких (далеких), а затем все более отдаленных (близких) друг от друга. Большинство этих алгоритмов исходит из матрицы расстояний (сходства).
Большинство программ, которые реализуют алгоритм иерархической классификации, предусматривают графическое представление результатов классификации в виде дендрограммы.
Под дендрограммой обычно понимается дерево, т. е. граф без циклов, построенный по матрице мер близости. Дендрограмма позволяет изобразить взаимные связи между объектами из заданного множества. В работах по кластерному анализу описан довольно внушительный ряд способов построения дендрограмм, в частности метод «ближайшего соседа», метод «дальнего соседа», метод «средней связи», центроидный метод, метод Уорда.
Пример 2.1. Исследуемая совокупность состоит из шести (п = 6) объектов. Каждый из объектов характеризуется двумя (k = 2) признаками. Нашей задачей является разделение исследуемой совокупности на однородные группы.
Номер объекта. | Номер признака. | |
И. | ||
Решение
Изобразим данные объекты па плоскости. По оси абсцисс отложим значение признака 1, по оси ординат — значение признака 2. Таким образом, на плоскости представлены шесть точек, соответствующие шести объектам наблюдения (рис. 2.8).
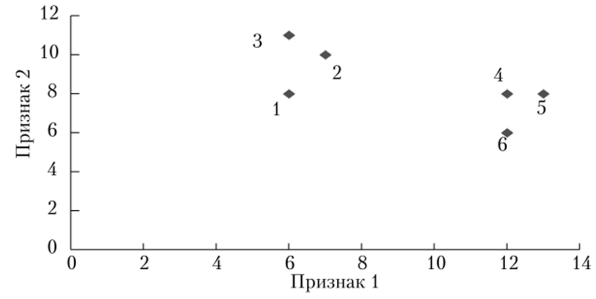
Рис. 2.8. Расположение объектов на плоскости.
При классификации объектов используем агломеративный иерархический алгоритм кластерного анализа.
В качестве меры близости (расстояния) между объектами совокупности будем.
[*.
использовать обычное евклидово расстояние рЕ(xjt Xj)= ./?(% -*//)2 , k = 2 (число признаков), i, j = 1, 2,…, 6 (номер объекта).
Рассчитаем расстояния:
между объектами 1 и 2: pl2 =yj (6—7)2 + (8 — 10)2 =2,24; между объектами 1 и 3: р, 3 =^(6−6)2+(8−11)2 =3,00: между объектами 1 и 4: р, 4 = >/(6 — 12)2 + (8 — 8)2 =6,00; между объектами 1 и 5: Plt5 =-у/(6−13)2 +(8−8)2 =7,00: между объектами 1 и 6: р[ 6 =-у/(6 — 12)2 + (8 — 6)2 =6,32; между объектами 2 и 3: р2 3 =л/(7-б)2+(10−11)2 =1,41; между объектами 2 и 4: р2 4 =д/(7−12)2 +(10−8)2 =5,39; между объектами 2 и 5: р2 5 =^/(7−13)2 + (10−8)2 =6,32; между объектами 2 и 6: р2 6 =^/(7−12)2 -+ (10 — 6)2 =6,40; между объектами 3 и 4: р3 4 =л/(6−12)2 +(11 -8)2 =6,71; между объектами 3 и 5: р3 5 =-^(6−13)2 +(11−8)2 =7,62; между объектами 3 и 6: р3 4 =^(6−12)2 +(11−6)2 =7,81; между объектами 4 и 5: р4 5 =-J ( 12−13)2+(8−8)2 =1,00; между объектами 4 и 6: р4 6 =л/(12 — 12)2 +(8−6)2 = 2,00; между объектами 5 и 6: р5 е =^/(13—12)2 + (8 — 6)2 =2,24.
Очевидно, что р" =0, р22 =0, р33 =0, р44 =0, р55 =0, р66 =0. Построим матрицу расстояний:
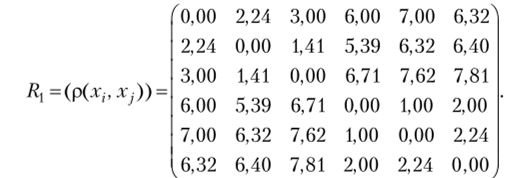
Проведенные расчеты показали, что наиболее близки объекты 4 и 5, так как расстояние между ними равно единице. Поэтому объекты 4 и 5 объединим в один кластер. 13 результате после такого объединения имеем пять кластеров:
Номер кластера. | |||||
Состав кластера. | (1). | (2). | (3). | (4,5). | (6). |
Найдем расстояние между кластерами по принципу «ближайшего соседа», для чего воспользуемся формулой пересчета (2.1), где, а = Р = -8 = ½ и у = 0. Расстояние между объектом 5, и кластером .У(4 ^ равно.
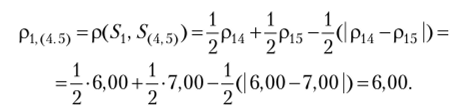
Расчеты показали, что расстояние от объекта 1 до кластера, в который входят объекты 4 и 5, равно расстоянию от объекта 1 до объекта 4, входящего в кластер S(4,5):
Pl,(4.5) = Pi, 4 =6,00.
Построим матрицу расстояний:
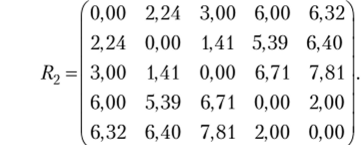
Проанализировав матрицу R2, обнаруживаем, что наименьшее расстояние — между объектами 2 и 3: р23 =1,41. Поэтому объекты 2 и 3 объединим в один кластер. В результате после такого объединения имеем четыре кластера:
11омер кластера. | ||||
Состав кластера. | (1). | (2,3). | (4,5). | (6). |
Найдем матрицу расстояний, воспользовавшись матрицей R>: расстояние между объектом 5] и кластером S(2 3)
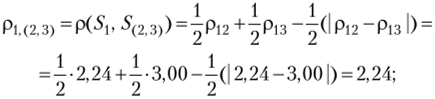
расстояние между кластером 5(2, з> и кластером 5^ 5) 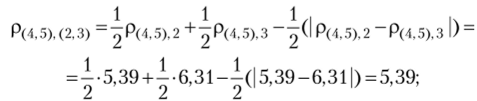 и т. д.
и т. д.
Построим матрицу расстояний:
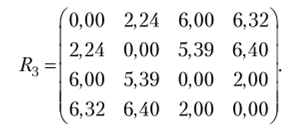
Проведенные расчеты показывают, что наиболее близки кластер 5<4 5ч и кластер, включающий объект 6, расстояние между ними равно p(i Г|) 6 =2. Объединяем их. В результате после такого объединения имеем три кластера:
Номер кластера. | |||
Состав кластера. | (1). | (2, 3). | (4, 5, 6). |
Построим матрицу расстояний:

Теперь наименьшее расстояние отмечается между кластером 5, и кластером 5(2 з>: Р) (2 з) =2,24. Объединим их в один кластер. В результате после такого объединения имеем два кластера:
Номер кластера. | ||
Состав кластера. | (1,2,3). | (4, 5, 6). |
Расстояние между этими двумя кластерами, найденное по принципу «ближайшего соседа», равно р(12 3) <4 5 6) =5,39.
Представим результаты иерархической классификации объектов в виде дендрограммы (рис. 2.9). Слева приведено расстояние между объединяемыми на данном этапе объектами (кластерами).
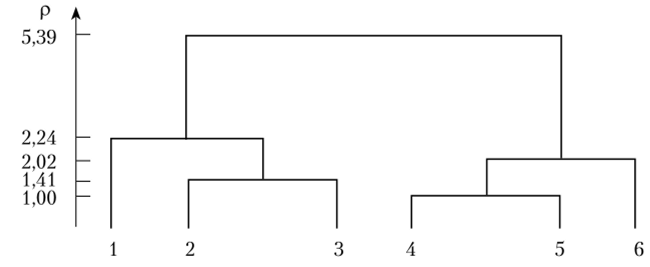
Рис. 2.9. Дендрограмма.
Вернемся к классификации группировок.
По используемой информации различают:
- • первичные группировки — производятся на основе исходных данных, полученных в результате статистического наблюдения;
- • вторичные группировки — результат объединения или расщепления первичной группировки.
Признаки, по которым проводится разбиение единиц совокупности на отдельные группы, называются группировочными признаками.
По форме выражения группировочные признаки могут быть атрибутивными, не имеющими количественного значения, и количественными, т. е. признаками, принимающими различные цифровые характеристики у отдельных единиц изучаемой совокупности. При этом количественные признаки, в свою очередь, могут быть дискретными (прерывными), значения которых отличаются друг от друга на некоторую конкретную величину, обычно целое значение или число с одним дробным разрядом (число квартир в доме, разряд рабочего и т. д.), и непрерывными, принимающими любые значения в некотором числовом интервале, отличаясь один от другого на сколь угодно малую величину (объем проданных населению товаров в стоимостном выражении, сумма издержек обращения).
Группировки, полученные по качественным признакам, называются атрибутивными, или качественными.
Группировки, полученные по количественным признакам, называются количественными.
Следующим важным шагом после определения группировочного признака является распределение единиц совокупности по группам. Здесь встает вопрос о количестве групп и величине интервала, которые между собой взаимосвязаны. Число групп зависит от задач исследования и вида показателя, положенного в основание группировки, объема совокупности, степени вариации признака.
При определении количества групп необходимо стремиться к тому, чтобы были учтены особенности изучаемого явления. Поэтому количество групп должно быть оптимальным, в каждую группу должно входить достаточно большое число единиц совокупности, что отвечает требованию закона больших чисел. Однако в отдельных случаях представляют интерес и малочисленные группы: новое, передовое, пока оно не станет массовым, проявляется в незначительном числе фактов; поэтому задача статистики — выделить эти факты, изучить их.
Таким образом, при решении вопроса о численности единиц в группах нужно руководствоваться не формальными признаками, а знанием сущности изучаемого явления.
Количество групп во многом зависит от того, какой признак служит основанием группировки. Так, нередко атрибутивные группировочные признаки предопределяют число групп. По аналогии также расчленяется совокупность по дискретному признаку, изменяющемуся в незначительном диапазоне. В совокупности, где варьирующий признак носит дискретный характер и принимает ограниченное число значений, количество групп, как правило, равно количеству возможных значений. Интервалы групп устанавливаются только при значительной колеблемости дискретного признака и тем более при непрерывно изменяющемся количественном признаке (например, величина зарплаты).
Число групп может быть задано на основе опыта предыдущих обследований. Если вопрос о числе групп надо решать самостоятельно, можно использовать формулу Стерджесса.
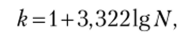
где k — число групп; N — число единиц совокупности.
Недостаток формулы состоит в том, что се применение дает хорошие результаты, если совокупность состоит из большого числа единиц и если распределение единиц по признаку, положенному в основание группировки, близко к нормальному.
Когда определено число групп, то следует определить интервалы группировки.
Интервал — это значения варьирующего признака, лежащие в определенных границах. Каждый интервал имеет свою величину, верхнюю и нижнюю границы или хотя бы одну из них. Нижней границей интервала называется наименьшее значение признака в интервале, а верхней границей — наибольшее значение признака в интервале. Величина интервала представляет собой разность между верхней и нижней границами.
Интервалы группировки в зависимости от их величины бывают равные и неравные. Последние делятся на прогрессивно возрастающие, прогрессивно убывающие, произвольные и специализированные.
Если распределение признака в границах его вариации достаточно равномерно или близко к нормальному, диапазон колебаний признака разбивают на равные интервалы, длину которых определяют по формуле.
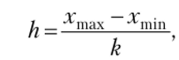
где хтах и хт[п — максимальное и минимальное значения признака в совокупности соответственно; k — число групп.
Если значения варьирующего признака распределены таким образом, что при использовании равного интервала для образования групп излишне увеличивается их количество и при этом многие группы будут малочисленными, то надо использовать группировку с неравными интервалами.
Применение неравных интервалов обусловлено тем, что в одних группах небольшая разница в показателях имеет большое значение, а в других группах эта разница не существенна. Например, будет неправильным применять равновеликий интервал по товарообороту для мелких, средних и крупных магазинов, поскольку разница в обороте в несколько тысяч рублей для мелких магазинов, палаток имеет решающее значение, а для крупных — несущественное. Нужны интервалы более короткие для мелких и более длинные (широкие) — для крупных магазинов.
Интервалы группировок могут быть закрытыми и открытыми.
Закрытыми называются интервалы, у которых имеются верхняя и нижняя границы.
Открытые — это те интервалы, у которых указана только одна граница: верхняя — у первого, нижняя — у последнего. Например, группы коммерческих банков по размеру прибыли (млн руб.): до 200, 200—300, 300—400, 400 и более.
В практике построения группировки нередко возникают ситуации, когда одно и то же число служит одновременно верхней границей одного интервала и нижней границей следующего за ним интервала. При таком построении интервалов вопрос об разнесении единиц наблюдения по группам решается, но принципу «включительно» (или «исключительно»).
Пример 2.2. Имеются следующие данные об успеваемости 20 студентов группы по теории статистики в летнюю сессию 2014 г.: 5, 4, 4, 4, 3, 2, 5, 3, 4, 4, 4, 3, 2, 5, 2, 5, 5, 2, 3, 3. Необходимо построить ряд распределения студентов по баллам оценок, полученных в сессию.
Решение
В рассматриваемом примере речь идет о количественной группировке. В исследуемой совокупности варьирующий признак (оценка) носит дискретный характер и принимает ограниченное число значений. В данном случае следует построить дискретный ряд, и количество групп должно быть равно количеству возможных значений признака:
Оценка. | ||||
Количество студентов. |
Построенная нами группировка является первичной, так как она производилась на основе исходных данных, полученных в результате статистического наблюдения.
Предположим, что нам необходимо построить ряд распределения студентов по уровню успеваемости, выделив в нем две группы студентов: неуспевающие (2 балла), успевающие (3 балла и выше). В данном случае речь идет об атрибутивной группировке:
Результат сдачи экзамена. | Неуспевающие. | Успевающие. |
Количество студентов. |
Рассмотрим на конкретном примере построение вторичных группировок.
Пример. 2.3. Имеется следующее распределение предприятий по объему продаж:
Объем продаж, млн руб. | 1−3. | 3−5. | 5−10. | 10−30. | 30−50. | Всего. |
Распределение предприятий, %. |
Используя метод вторичной группировки, необходимо образовать следующие группы предприятий по объему продаж:
- 1) 1−10, 10−20, 20−30, 30−40, >40;
- 2) 1−15, 15−30, 30−45, >45.
Решение
1. Первые три группы надо объединить, четвертую и пятую фуппы надо разделить.
Разделение должно проводиться пропорционально делению величины интервала:
1−10. | 10−20. | 20−30. | 30−40. | >40. |
4 + 14+16 = 34. | — = 26 2. | — = 26 2. | И=7 | И = 7 2. |
2. Решение аналогично п. 1, только при расщеплении интервалов необходимо учесть, что величина интервала делится на неравные части:
1−15. | 15−30. | 30−45. | > 45. |
|
|
| — = 3,5 4. |
Особым видом группировок являются классификации, получившие широкое распространение в статистике. Классификацией называется систематизированное распределение явлений и объектов на определенные группы, классы, разряды на основании их сходства и различия. Классификации отличаются от группировок более устойчивым и подробным разделением изучаемого явления на классы, группы по основным, обычно качественным признакам.
Объективная необходимость разработки классификации обусловлена многообразием атрибутивных признаков при изучении многочисленных явлений и процессов, создающих трудности при отнесении единиц совокупности к определенной группе или классу. При наличии нескольких признаков у отдельной единицы статистической совокупности ее относят к определенной группе по признаку, имеющему преимущественное значение: кассир и продавец, шофер и грузчик и т. п.; в подобных случаях этих работников относят к конкретной группе по их основной деятельности.
Классификация, представляющая устойчивую номенклатуру классов и групп, образованных на основе сходства и различия единиц наблюдаемого объекта, имеет фундаментальное значение для всего цикла статистических работ.
Отличительными чертами классификаций является то, что в основу их кладется качественный признак; они стандартны и устанавливаются органами государственной и международной статистики; они устойчивы, так как остаются неизменными в течение длительного периода времени.
Контрольные вопросы и задания
- 1. Какие требования предъявляются к проведению статистического наблюдения?
- 2. Назовите основные формы статистического наблюдения.
- 3. Что такое ошибки репрезентативности? Каким видам статистического наблюдения они свойственны?
- 4. Какие виды несплошного наблюдения вы знаете?
- 5. Что такое критический момент и критическая дата наблюдения?
- 6. Какие группировочные признаки называются атрибутивными? Приведите примеры.
- 7. Дайте определение простой и сложной сводки.
- 8. Какова роль группировок в статистике?
- 9. Каковы принципы выбора группировочного признака, образования групп и интервалов группировки?
- 10. Дайте определение и приведите примеры аналитических группировок.