Модели логической организации данных в базах данных.
Применение реляционных моделей данных в маркетинговых базах данных

Для моделирования данных со сложными логическими связями сетевая модель, как более общая, предоставляет большие возможности по сравнению с иерархической, однако она намного сложнее в реализации и использовании. Построение прикладных программ для сетевых БД является трудоемким процессом, так как необходимо знать все связи между разнородными объектами и перестраивать множество различных связей… Читать ещё >
Модели логической организации данных в базах данных. Применение реляционных моделей данных в маркетинговых базах данных (реферат, курсовая, диплом, контрольная)
В любой БД данные должны быть определенным образом структурированы, т. е. должна существовать информационная модель (называемая моделью данных), определяющая метод логической организации данных в БД. Модель реализуется СУБД и устанавливает правила размещения данных в памяти в виде структур данных, а также возможные (допустимые) операции манипулирования с этими структурами.
Совокупность взаимосвязанных структур данных БД и операций их обработки называется моделью БД.
Распространенными моделями БД являются: иерархическая, сетевая, реляционная. Соответственно говорят об иерархических, сетевых и реляционных СУБД, реализующих и поддерживающих в БД эти виды моделей.
Иерархическая модель позволяет строить БД с иерархической древовидной структурой данных. Эта структура определяется как дерево, образованное попарными связями (рис. 4.24, а). Узлы дерева представляют некоторые данные (записи, файлы), расположенные на разных иерархических уровнях. Ребра между узлами отображают наличие того или иного отношения между данными (например, между узлами «клиент» и «заказ» может быть отношение «делает», а между «заказ» и «товары» — отношение «состоит из»).
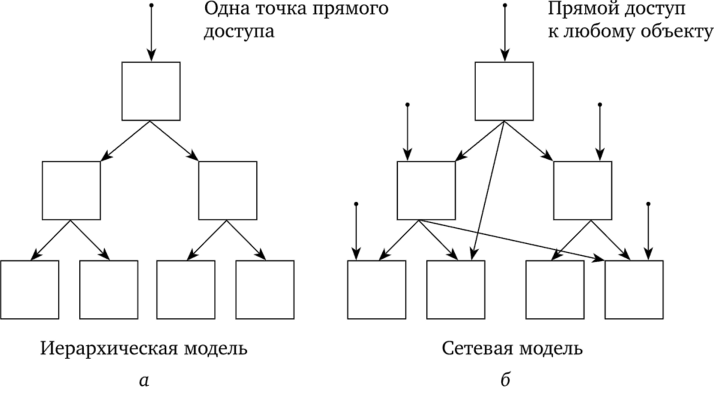
Рис. 4.24. Топология данных иерархической и сетевой моделей.
На самом верхнем уровне дерева имеется только один узел, называемый корнем. Узлы, расположенные на более низком уровне, называются порожденными (или потомками), на более высоком уровне — исходными (или предками). Каждый узел может иметь только одного исходного и любое количество порожденных. Доступ к определенному узлу осуществляется по цепочке — от узла-предка к узлу-потомку, начиная с корневого узла, т. е. в каждый узел имеется только один путь.
В маркетинговых БД иерархическая модель может использоваться для отражения реальных иерархических связей, существующих между маркетинговыми объектами (например, иерархическая классификация товаров), а также для представления сложных объектов, состоящих из более простых (например, в состав объекта ЗАКАЗ входят объекты ТОВАР, ПОКУПАТЕЛЬ, КУРЬЕР).
Недостатком иерархической модели является ее громоздкость для обработки данных со сложными логическими связям, достоинством — эффективное использование памяти компьютера при хранении данных.
Сетевая модель данных является расширением иерархической модели, где каждый порожденный узел может иметь более одного исходного и узлы могут связываться между собой не только «сверху вниз», но и «по горизонтали» (рис. 4.24, б). Модель обеспечивает возможность образования в БД произвольных связей между узлами и прямой доступ к любому узлу.
Для моделирования данных со сложными логическими связями сетевая модель, как более общая, предоставляет большие возможности по сравнению с иерархической, однако она намного сложнее в реализации и использовании. Построение прикладных программ для сетевых БД является трудоемким процессом, так как необходимо знать все связи между разнородными объектами и перестраивать множество различных связей, если приходится проводить изменение структуры данных в БД.
В настоящее время наибольшее распространение в построении БД получила реляционная модель данных (от англ, relation — отношение), разработанная Е. Коддом. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением информации и возможностью использования формального аппарата (реляционной алгебры и реляционного исчисления) для обработки данных.
Реляционная модель представляет объекты и взаимосвязи между ними в виде двумерных таблиц, называемых отношениями. Строки таблицы соответствуют записям, а столбцы — полям. Основные структурные элементы модели описаны на рис. 4.25.
Домен — это множество значений, принимаемых свойствами (характеристиками) отражаемого объекта.
Атрибут — имя множества значений, входящих в домен. Атрибуты используются в качества средства для обращения к доменам.
Кортеж — множество элементов из доменов, составляющих одну строку отношения (таблицы).
Отношение — таблица, состоящая из множества кортежей, отражающих свойства объекта.
Каждый атрибут задается одним столбцом, наименование которого — это имя атрибута, а элементы столбца — значения атрибута.
Таблицы реляционной модели строятся в рамках ограничений, диктуемых операциями их обработки. Это следующие ограничения:
• таблица должна иметь уникальное имя (например, ТОВАР, ПОСТАВЩИК, ПОСТАВКИ);
- • данные в пределах одного столбца должны быть однородны, т. е. элементы столбца должны иметь одинаковую структуру (тип и длину);
- • таблица не должна содержать в столбцах составные элементы (например, у поставщика должен быть только один номер телефона, указанный в одной строке);
- • в таблице не должно быть одинаковых строк и одинаковых столбцов;
- • имена столбцов должны быть уникальными, т. е. не могут совпадать;
- • порядок следования строк и столбцов может быть произвольным;
- • обращения к столбцам и строкам таблицы могут выполняться в произвольном порядке, т. е. может быть выбрана любая строка и любой столбец;
- • должен быть указан первичный ключ (простой или составной), используемый для поиска в таблице необходимых строк или выполнения других логических операций, а также внешние ключи (ключи связи между таблицами).
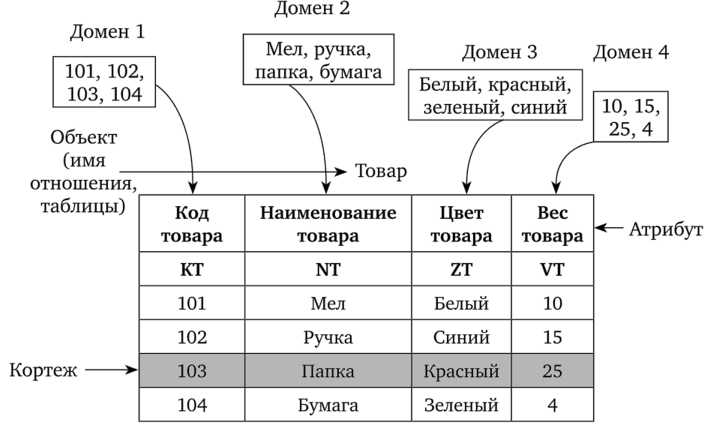
Рис. 4.25. Основные понятия реляционной модели
Связь между таблицами реализуется путем использования в разных таблицах одноименных полей, играющих роль ключей. Так, таблицы ПОСТАВЩИК и ПОСТАВКИ (рис. 4.26) связаны через ключ Код поставщика, а таблицы ТОВАР и ПОСТАВКИ — через ключ Код товара.
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы или ввести в структуру первой таблицы внешний ключ — ключ второй таблицы. На рис. 4.26 эти связи указаны с помощью стрелок.
Все операции над данными в реляционной БД сводятся к операциям над таблицами, выполняемым с помощью аппарата реляционной алгебры.
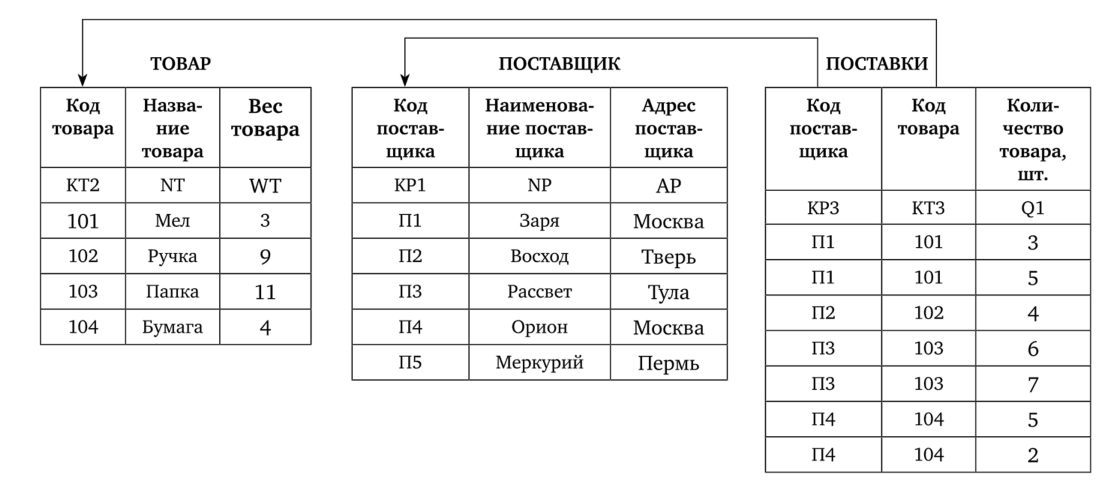
Рис. 4.26. Реляционная база данных «ПОСТАВЩИКИ — ТОВАР».
Выделяют три основных операций: ВЫБОРКА, ПРОЕКЦИЯ, СОЕДИНЕНИЕ. Первые две операции унарные (применяются к одной таблице), третья — бинарная. Рассмотрим примеры применения этих операций.
Примеры
1. Общая форма оператора ВЫБОРКА имеет вид:
ВЫБОРКА ИЗ
ГДЕ < условно.
ПОЛУЧАЯ
В результате получают новую таблицу, в которой находятся лишь те строки, которые удовлетворяют заданному условию.
Пусть из таблицы ПОСТАВКИ необходимо выбрать тех поставщиков, которые поставляли товар с кодом 101:
ПОСТАВКИ.
Код поставщика | Код товара | Количество (шт.) |
КР. | КТ. | Q. |
П1 | ||
П1 | ||
П2 | ||
ПЗ | ||
ПЗ | ||
П4 | ||
П4 |
Заполнив общую форму оператора, получим: ВЫБОРКА ИЗ ПОСТАВКИ ГДЕ КТ = 101.
ПОЛУЧАЯ ПОСТАВЛЕННЫЙ ТОВАР В результате будет получена следующая таблица: ПОСТАВЛЕННЫЙ ТОВАР.
Код Поставщика | Код товара | Количество (шт.) |
КР | КТ | Q. |
П1 | ||
П2 | ||
П4 |
В результате получают новую таблицу, в которую входят лишь столбцы с именами, указанными в операторе.
Выполнение оператора ПРОЕКЦИЯ ПОСТАВЛЕННЫЙ ТОВАР НА (КП, Q).
ПОЛУЧАЯ ОБЪЕМ ПОСТАВКИ дает результирующую таблицу.
ОБЪЕМ ПОСТАВКИ
Код поставщика | Количество (шт.) |
КР. | Q. |
П1. | |
П2. | |
П4. |
3. Для объединения таблиц используется оператор СОЕДИНЕНИЕ, общий вид которого следующий:
СОЕДИНЕНИЕ И.
ПО И
ПОЛУЧАЯ
Допустим необходимо для расшифровки кодов поставщиков в таблице ПОСТАВЛЕННЫЙ ТОВАР соединить ее с таблицей ПОСТАВЩИК (см. рис. 4.26). Тогда данный оператор приобретает вид:
СОЕДИНЕНИЕ ПОСТАВЛЕННЫЙ ТОВАР И ПОСТАВЩИК ПО КР И КР1.
ПОЛУЧАЯ ПОСТАВЩИКИ ТОВАРА Результаты выполнения оператора СОЕДИНЕНИЕ:
ПОСТАВЩИКИ ТОВАРА
Код поставщика | Код товара | Коли чество товара | Код постав щика | Наименование поставщика | Адрес постав щика |
КР. | КТ. | Q. | КР1. | NP. | АР. |
П1. | П1. | Заря. | Москва. | ||
П2. | П2. | Восход. | Тверь. | ||
ПЗ. | ПЗ. | Рассвет. | Тула. |
- — выделить входные оперативные документы, содержащие переменную информацию и отражающие текущие факты или операции;
- — выделить условно-постоянные документы, содержащие нормативно-справочные данные;
- — разработать результирующие документы, таблицы, отчеты;
- — определить документы, предназначенные для корректировки условно-постоянных данных.
Как правило, условно-постоянная информация, находящаяся в иных БД, доступна большинству пользователей и поэтому она не создается.
Далее осуществляется описание таблиц БД средствами СУБД, задание связей между таблицами и разработка форм отчетов, которые также описываются средствами СУБД. Пример созданной БД и полученных с ее помощью результатов представлен на рис. 4.27.
Существует несколько режимов взаимодействия пользователей СУБД:
- — режим конечного пользователя с применением конструктора БД и запросов;
- — программный режим, предполагающий знание пользователем языка СУБД и позволяющий создавать прикладные программы.
Конечный пользовать, как правило, пользуется конструктором, с помощью которого задается структура БД, формулы для расчетов и структура отчета. Достаточно популярной СУБД для данного класса является MS Access.
Программный режим предполагает создание программ с помощью программистов-профессионалов.
Профессиональные (промышленные) СУБД представляют собой программную основу для создания и функционирования крупных экономических объектов. На их базе создаются комплексы управления и обработки информации на крупных предприятиях, в банках, корпорациях или даже целых отраслях.
Мощные профессиональные СУБД, обеспечивающие хранение данных большого объема и сложной логической структуры, используются, как правило, в составе многоуровневой клиент-серверной архитектуры корпоративных ИС, размещаясь на одном или нескольких серверах БД. Среди них широкое применение получили СУБД реляционного типа: Informix Dynamic Server, InterBase, Oracle, DB2 Universal Database, Microsoft SQL Server, MySQL, Enterprise Edition (для крупных систем), WorkGroup Edition и/или Desktop Edition (для средних и малых систем) и др.
В последние годы все большее признание и развитие получают объектно ориентированные и многомерные БД.
Объектно ориентированные БД работают с объектами, представляющими практически все формы информации, воспринимаемые человеком: не только числовые и символьные данные, но и рисунки, фотографии, речь, полнофункциональное видео. Данные объекта, а также его методы помещаются в хранилище как единое целое, поэтому объекты можно сохранять и использовать непосредственно, не раскладывая их по таблицам.
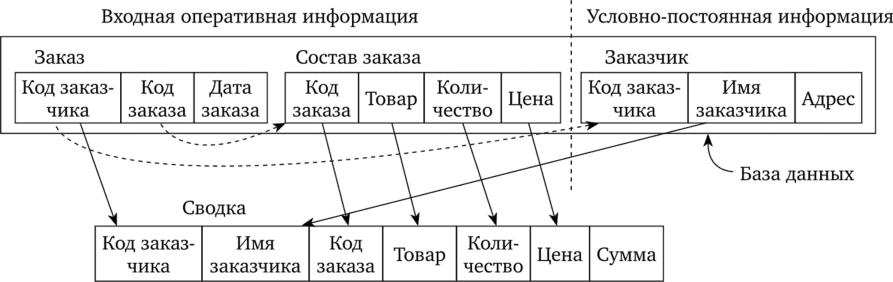
Рис. 4.27. Схема формирования базы данных «Заказы».
Объектные СУБД могут применяться для управления различного рода мультимедийными компонентами, используемыми в Webприложениях, которые обычно интегрируют фрагменты информации из разных источников. Удобны объектные СУБД и для маркетинговых, а также торговых приложений, так как им требуются модели данных, которые легко изменяются в соответствии с новыми экономическими условиями.
Многомерные БД рассматриваются в следующем параграфе.