Характеристики формы распределения

Но вернемся к нашему примеру об эффективности рекламной кампании. Если нам удастся показать, что зафиксированная в ходе опроса выборочная доля информированных о товаре (р = 0,48) так сильно превышает установленной нами плановый уровень (0,45), что, если бы во всей исследуемой совокупности доля информированных не превышала этот уровень (?? 0,45), результат опроса р = 0,48 был бы крайне… Читать ещё >
Характеристики формы распределения (реферат, курсовая, диплом, контрольная)
Характеристиками формы распределения значений измеряемого показателя являются асимметрия (skewness) и эксцесс (kurtosis). Они позволяют судить о том, в какой степени распределение по форме похоже на классический симметричный относительно центра распределения «колокольчик» нормального распределения. Расчет этих характеристик можно выполнить, например, в меню Analyze > Descriptive Statistics > Descriptives > Options (рис. 12.11).
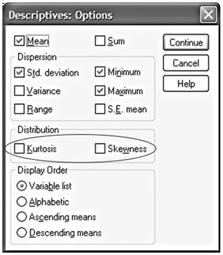
Рис. 12.11. Заказ параметров расчета асимметрии и эксцесса Если асимметрия распределения показателя положительна, то переменная отклоняется от своего среднего значения в правую сторону на несколько большие расстояния, чем в левую (правый «хвост распределения» длиннее левого). А если асимметрия отрицательна, то наоборот.
Рассмотрим, например, диаграмму распределения ответов респондентов, участвовавших в общероссийском репрезентативном опросе Фонда Общественное Мнение (август 2009 г.), на вопрос о размере дохода в расчете на одного члена семьи (рис. 12.12). Среднее значение этого распределения равно 5,94, среднеквадратическое отклонение составляет 6,22, а асимметрия положительна и равна 3,80. На том же рисунке для сравнения приведена кривая нормального распределения с таким же средним значением и среднеквадратическим отклонением. Легко заметить, что значения переменной вправо удаляются от среднего значения на большее протяжение, чем влево. Правый «хвост» длиннее левого.
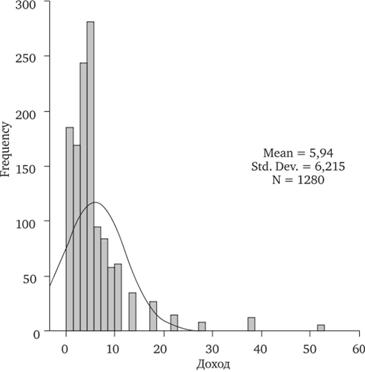
Рис. 12.12. Гистограмма распределения доходов населения в расчете на одного члена семьи, тыс. руб.
Эксцесс позволяет судить о крутизне изучаемого распределения: больше она по сравнению с нормальным распределением или меньше. Эксцесс для нормального распределения равен нулю, для более острых распределений он положителен, а для более пологих — отрицателен.
В рассматриваемом нами рис. 12.12 эксцесс положителен (20,0), т. е. наше распределение намного круче, чем «колокольчик» нормального распределения. Действительно, распределение в большей степени, чем соответствующее нормальное, сконцентрировано в центре.
Общие принципы проверки статистических гипотез. Гипотезы, проверяемые на основе частотного распределения ответов
Идея, лежащая в основе проверки маркетинговых гипотез. В ходе маркетинговых исследований проверяется много гипотез и некоторые из них — с помощью частотных распределений.
Пример 12.4.
Проведение выборочного опроса
Пусть фирма, производящая, скажем, кисломолочные продукты, видоизменила один из них и проводит рекламную кампанию модифицированного продукта. Фирма решила считать рекламную кампанию эффективной, если после ее окончания о новом продукте слышали более чем 45% представителей исследуемой (генеральной) совокупности (например, жителей определенного региона или страны в целом). Если обозначить через? долю знающих о новом товаре представителей исследуемой совокупности, то рекламная кампания будет признана успешной, если? > 0,45. Чтобы проверить, выполняется ли это условие, фирма провела выборочный опрос определенного числа случайным образом отобранных представителей исследуемой совокупности. Оказалось, что о товаре слышали 48% респондентов, т. е. выборочная доля (р) превысила запланированный фирмой уровень: р > 0,45.
Однако радоваться рано: ведь опрошены не все, а лишь некоторые случайным образом отобранные люди. Не исключено, что обнаруженное при опросе превышение над плановым уровнем — просто случайность, что, опроси фирма всех без исключения, оказалось бы, что истинная доля не превышает порог:? ? 0,45.
Как же на основе знания лишь выборочной доли сделать вывод об истинной доле информированных во всей исследуемой совокупности? На помощь приходит знакомая со школьной скамьи идея доказательства «от противного»: если предположение, обратное тому, которое мы стремимся доказать, приводит нас к противоречию, значит, то, что мы хотим доказать, — верно.
Заметим: противоречием называется событие, которое не может произойти никогда, ни при каком стечении обстоятельств, т. е. вероятность наступления которого равна нулю. Можно сказать, что в статистике понятие противоречия расширяется, условно говоря, к «настоящим противоречиям», т. е. совершенно невозможным ситуациям добавляются «почти противоречия» — практически невозможные ситуации. Таковыми признаются такие события, которые в принципе могут произойти, но очень редко, например не чаще, чем в пяти случаях из ста, или в одном случае из ста, т. е. вероятность возникновения которых не превышает 0,05 и 0,01 соответственно.
Эту идею можно проиллюстрировать еще и таким примером. Пусть мы хотим убедиться, что в непрозрачном барабане черных шаров больше, чем белых. Хорошенько перемешав и вытащив наугад десять шаров, мы обнаружили, что девять из них черные. Могло ли так получиться, если на самом в барабане черные шары не составляют большинства? Конечно, может, но интуиция нам подсказывает: вряд ли это так, скорее, черных шаров в барабане больше.
Но вернемся к нашему примеру об эффективности рекламной кампании. Если нам удастся показать, что зафиксированная в ходе опроса выборочная доля информированных о товаре (р = 0,48) так сильно превышает установленной нами плановый уровень (0,45), что, если бы во всей исследуемой совокупности доля информированных не превышала этот уровень (?? 0,45), результат опроса р = 0,48 был бы крайне маловероятен, практически невозможен, значит, на самом деле доля информированных потребителей выше порога (? > 0,45), т. е. рекламная кампания эффективна. В таком случае принято говорить, что выборочная доля (р = 0,48) значимо превышает заданный запланированный уровень (0,45), а также что сделанный по результатам выборочного опроса вывод о превышении запланированного уровня информированности можно распространить на всю исследуемую совокупность.
Нулевая и альтернативная гипотезы. Введем определения. В предыдущем подразделе мы показали, что логика, лежащая в основе проверки гипотез, аналогична логике доказательств «от противного». Поэтому начнем с формулировки утверждения, обратного тому, в истинности которого нам хотелось бы убедиться, т. е. сформулируем утверждение, которое будет отвергнуто (отклонено), если оно приведет нас к «почти противоречию». Такое утверждение называется нулевой гипотезой и обозначается Н0. Еще раз подчеркнем: нулевая гипотеза формулируется так, чтобы ее отклонение дало нам основание сделать желаемый вывод. В нашем примере — это гипотеза о том, что ситуация на самом деле не такова, как нам хотелось бы и каковой она кажется по результатам выборочного опроса, т. е. что доля знающих о новом продукте среди всех потребителей товара не выше 0,45, т. е. показатель эффективности рекламной кампании не достиг запланированного уровня. Нулевую гипотезу принято записывать так: Н0:? ? 0,45.
То утверждение, которое нам хотелось бы обосновать, называется альтернативной гипотезой и обозначается Н1. В нашем примере она состоит в том, что цель рекламной кампании достигнута, т. е. не только среди попавших в выборку респондентов, но и среди всех представителей исследуемой совокупности доля знающих о новом продукте превышает плановый уровень (Н1:? > 0,45). Если мы покажем, что по результатам опроса нулевая гипотеза (Н0) должна быть отвергнута (отклонена), значит, надо принять альтернативную гипотезу. Если же данные опроса не противоречат нулевой гипотезе (т.е. Н0 не отвергается (не отклоняется)), значит, альтернативная гипотеза не принимается и надо либо собрать больше данных для ее дополнительной проверки, либо признать, что вывод о превышении запланированного уровня эффективности рекламной кампании результатами исследования не подтвердился.
Обратим внимание на терминологию: Н0 отвергается (не отвергается) или отклоняется (не отклоняется), а Н1 принимается (не принимается). Эти словесные нюансы подчеркивают тот факт, что мы здесь оперируем не с настоящими противоречиями в точном, «школьном» смысле, а с «почти противоречиями», практически невозможными событиями. А значит, мы не можем, что называется, «дать руку на отсечение», что кампания эффективна, мы лишь утверждаем, что, судя по результатам опроса, это, скорее всего, именно так.
Итак, теория проверки статистических гипотез не располагает средствами, которые позволили бы утверждать, что интересующая нас альтернативная гипотеза ?1 бесспорно соответствует действительности. Нельзя полностью исключить, что это не так, но вероятность такого события столь мала, что на практике его можно считать невозможным.
Запишем все то, о чем говорилось выше, формальным языком:
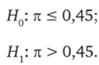
Если в предположении справедливости Н0 получим ver(p? 0,48)  0, то Н0 надо отклонить и принять Н1.
0, то Н0 надо отклонить и принять Н1.
Для полноты картины сделаем замечание. В описанной ситуации нулевая и альтернативная гипотезы выражаются неравенствами, т. е. направленно.
В теории проверки статистических гипотез иногда рассматриваются другие ситуации, которые трудно представить себе в маркетинге. Рассмотрим такой малореальный пример. Предположим, фирма точно знает: год назад о существовании некоторого кисломолочного продукта знали ровно 45% представителей исследуемой совокупности. Через год с помощью выборочного опроса фирма хочет узнать: изменился или не изменился этот показатель, причем неважно, в большую или в меньшую сторону.
В такой ситуации нулевая гипотеза выражается равенством, а альтернативная — отрицанием этого равенства, т. е. выражена ненаправленно:
H0:? = 0,45 — нулевая гипотеза;
?1:? ? 0,45 — альтернативная гипотеза.
Исходя из рассмотренных задач, существуют два типа статистических тестов для проверки гипотез: односторонние и двусторонние.
Когда исследователя интересует отклонение замеряемой характеристики от фиксированного значения в какую-либо определенную сторону, т. е. альтернативная гипотеза выражена направленно, используются односторонние статистические тесты (one-tailed tests).
Когда же исследователя интересует отклонение замеряемой характеристики от фиксированного значения (неважно, в какую сторону — большую или меньшую) используются двусторонние статистические тесты (two-tailed tests). В маркетинговых исследованиях такие тесты имеют гораздо меньшее практическое значение, так как обычно существует определенное предпочтительное направление различий.
Выбор тестовой статистики. Вернемся к нашему основному примеру. Итак, выборочная доля информированных о новом продукте респондентов (р) оказалась равной 0,48. Мы выясняем, значимо ли она превышает определенный выбранный заказчиком уровень 0,45. Иными словами, можно ли по полученному значению выборочной доли сделать вывод, что доля информированных потребителей среди всех интересующих заказчика жителей (?) тоже превышает этот запланированный уровень.
Напомним, утверждение, нуждающееся в проверке, называемое альтернативной гипотезой, в данном случае имеет вид: Н1:? > 0,45, а обратное утверждение, называемое нулевой гипотезой: Н0:? ? 0,45. Наша цель — показать, что если бы была верна нулевая гипотеза, то вероятность возникновения выборочных долей 0,48 и более была бы очень малой.
Поскольку охваченные опросом респонденты были отобраны случайным образом, выборочная доля (р) — это случайная величина. (Если бы мы построили другую выборку, опросили бы других людей, то у нас получилась бы иная выборочная доля.) Если бы мы знали закон распределения случайной величины р, мы могли бы рассчитать эту вероятность в предположении об истинности нулевой гипотезы.
Далее логика такова. Распределение интересующей нас случайной величины преобразуют к стандартизованному виду. Для стандартизованных распределений существуют таблицы вероятностей, а также специальные компьютерные программы и функции, с помощью которых можно рассчитать вероятность случайного возникновения такого же и всех больших или такого же и всех меньших значений.
Такая стандартизованная случайная величина называется тестовой статистикой.
В качестве тестовой статистики в зависимости от ситуации используются, например, стандартизованное нормальное распределение (z), стандартизованное распределение Стьюдента (0 или стандартизованное распределение ?2. В данном разделе мы ограничимся случаем, когда можно использовать стандартизованное нормальное распределение. Стандартизованным оно является в том смысле, что его среднее значение равно нулю, а дисперсия — единице. (Соответственно равно единице и среднеквадратическое отклонение, равное корню квадратному из дисперсии.).
В рассматриваемом нами примере речь идет о распределении выборочных долей. Если размер выборки достаточно велик (например, 1000 респондентов и более), то для практических целей можно считать, что распределение случайной величины р является нормальным.
Это следует из центральной предельной теоремы, согласно которой сумма, а значит, и среднее значение большого числа независимых случайных величин с любым, но одним и тем же законом распределения с ростом числа этих случайных величин стремится к нормальному распределению. Каждый конкретный случайным образом отобранный респондент может как знать, так и не знать о существовании интересующего нас нового продукта, причем люди, знающие о продукте, попадают в выборку с вероятностью ?. Если обозначить единицей факт знания о продукте, а нулем — не знания, то, усредняя по выборке набор нулей и единиц, получим число р, равное выборочной доле знающих о новом товаре. Эта операция усреднения и приводит к тому, что распределение случайных величин р стремится к нормальному со средним значением, равным? (неизвестной нам истинной доле знающих в исследуемой совокупности), и среднеквадратическим отклонением, равным ??.
Если преобразовать эту случайную величину по формуле.
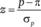 (12.8).
(12.8).
где р — доля опрошенных, знающих о новом продукте;? — доля представителей всей исследуемой совокупности, знающих о новом продукте; ?? — среднеквадратическое отклонение случайной величины р (т.е. случайной последовательности выборочных долей, которая возникла бы, если бы мы не ограничились одним выборочным опросом, а извлекали из исследуемой совокупности одну случайную выборку за другой).
Среднеквадратическое отклонение случайной величины р в данном случае рассчитывается по формуле.
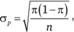 (12.9).
(12.9).
где n — размер выборки.
Далее мы будем рассуждать следующим образом. Нам в принципе не может быть известно число ?, входящее в приведенные выше формулы. Однако предположение, что выполняется нулевая гипотеза (Н0), означает, что это число не превышает 0,45. При этом наибольшей вероятность получения выборочных долей 0,48 и более будет при? = 0,45. Это значение и надо подставлять в формулы для проверки нулевой гипотезы. Обозначим через z* значение тестовой статистики для случая р = 0,48,? = 0,45. Тогда для отклонения нулевой гипотезы необходимо, чтобы вероятность наблюдения любых значений ?, больших или равных z*, была достаточно малой (ver(z 3 z* > О).
Теперь нам надо определиться, какие значения вероятностей мы будем считать малыми, близкими к нулю. Надо выбрать величину порога а, такую, что события, имеющие более низкую вероятность, мы будем считать практически невозможными. Величина, а называется уровнем значимости (level of significance).
Выбор уровня значимости. Ошибки первого и второго рода. Выбор уровня значимости — важная содержательная, а не формально-математическая задача. Дело в том, что, поскольку мы пытаемся сделать заключение о свойстве всей исследуемой совокупности на основе опроса выборки респондентов, мы можем совершить ошибку. Вернемся к нашему примеру. Предположим, что мы выбрали в качестве уровня значимости пороговую вероятность, а = 0,05. Пусть мы рассчитали ver(p 3 0,48) при условии справедливости Н0 о неэффективности рекламной кампании, и оказалось, что ver(p 3 0,48) < а. Это позволяет отвергнуть нулевую гипотезу? < 0,45 и признать рекламную кампанию нового продукта эффективной. (На этом основании руководство фирмы может, например, принять решение о продолжении данной рекламной кампании без всяких модификаций.) Однако ранее мы говорили, что теория проверки статистических гипотез не располагает средствами, которые позволили бы утверждать, что интересующая нас альтернативная гипотеза Н1 бесспорно соответствует действительности. Существует возможность, что рекламная кампания на самом-то деле не эффективна, а мы решили ее продолжить. Чтобы обезопасить себя от таких ситуаций, возникает естественное желание уменьшить уровень значимости а, повысив тем самым надежность наших выводов, например принять, а = 0,01. Но при этом может оказаться, что полученный по опросу результат (р = 0,48) уже не является практически невозможным событием, т. е. ver(p? 0,48) > а = 0,01, и мы теперь не сможем отвергнуть нулевую гипотезу — предположение о неэффективности рекламной кампании. И тогда руководство сможет перестраховаться и прекратить финансирование рекламной кампании. Но не зря говорят: «Кто не рискует, тот не пьет шампанское!» Ведь не исключено, что прекращенная рекламная кампания на самом деле была эффективной. И мы допустили ошибку, прекратив ее. Вероятность такой ситуации (обозначим ее? — вероятность прекращения эффективной рекламной кампании, т. е. вероятность ошибиться и не отклонить Н0, когда Н0 не соответствует действительности) зависит от неизвестного нам истинного значения ?. Вероятность? тем больше, чем меньше выбранное нами значение а, т. е. выше кажущаяся надежность выводов об эффективности рекламной кампании.
Таким образом, исследователь может совершить ошибку двоякого рода.
Ошибка первого рода возникает, когда мы по имеющимся у нас выборочным данным отвергаем нулевую гипотезу, считаем ее несправедливой и ошибаемся, тогда как на самом деле ее отвергать неправильно: Н0 справедлива и рекламная кампания неэффективна. Например, на основе выборочного опроса мы можем прийти к выводу, что новый продукт известен более чем 45% потребителей, тогда как в действительности среди всех (а не только опрошенных) представителей исследуемой совокупности эта доля не превышает 45%. Вероятность совершить ошибку первого рода равна, а — выбранному нами уровню значимости. Этот выбор делается, исходя из величины потерь в случае ошибки данного типа (цены ошибки).
Ошибка второго рода возникает, когда мы, напротив, не отвергаем на основании наших выборочных данных нулевую гипотезу Н0 считаем ее справедливой, тогда как если бы знали истинную долю информированных в исследуемой совокупности (?), то убедились бы, что? > 0,45, и нулевая гипотеза не соответствует действительности, несправедлива. В приведенном выше примере, когда мы понизили уровень значимости? до 0,01, полученный по опросу результат (р = 0,48) перестал быть практически невозможным событием. В результате мы не отвергли нулевую гипотезу (посчитали ее справедливой), сочли рекламную кампанию неэффективной и допустили ошибку второго рода, прекратив удачную рекламную кампанию. Вероятность совершить ошибку второго рода принято обозначать ?.
В то время как выбор? определяется исследователем, величина ?, напротив, целиком зависит от неизвестной исследователю величины: истинного значения оцениваемого с помощью опроса маркетингового показателя (в нашем примере — фактическая доля информированных потребителей ?).
Понятно, что вероятность? ошибочно не отклонить нулевую гипотезу тем выше, чем ниже выбранный нами уровень значимости а.
Введем связанное с этим важное понятие. Вероятность не допустить ошибку второго рода, равная 1 — ?, называется мощностью статистического критерия (power of statistical test). Это вероятность того, что нулевая гипотеза будет отвергнута в ситуации, когда она и должна быть отвергнута, так как не соответствует действительности, несправедлива.
Мощность статистического критерия зависит от истинного, а не принятого на основании гипотезы значения величины? и поэтому исследователю неизвестна, но она зависит от выбранного им уровня значимости а. Как мы показали, с уменьшением, а растет. Из чего следует, что, уменьшая а, исследователь всегда уменьшает, хотя и не зная с какой и до какой величины, мощность статистического критерия 1-?.
Таким образом, проверяя гипотезу, исследователь находится «между Сциллой и Харибдой» ошибок первого и второго рода. Чаще всего в качестве компромисса между ними избирают уровень значимости? = 0,05, существенно реже —? = 0,01, а более низкие значения не избирают почти никогда.
Будем считать, что в нашем сквозном примере мы выбрали уровень значимости 0,05.
Сбор данных для проверки гипотезы. После выбора уровня значимости с учетом его влияния на мощность статистического критерия, а также учитывая другие, в частности бюджетные ограничения, проводится опрос, собирается необходимое количество данных, например, путем опроса и рассчитывается значение статистического критерия.
Предположим, что мы опросили 1501 случайно отобранного респондента, 724 из которых сказали, что знают новый продукт. Тогда имеем:
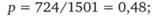
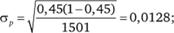
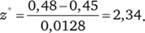
Сравнение эмпирической вероятности с критическим значением и заключения относительно гипотезы. По таблицам нормального стандартизованного распределения или, например, в приложении MS Excel с помощью функции НОРМСТРАСП (2,34) можно установить следующее: вероятность того, что случайная величина со стандартизованным нормальным распределением равна или превышает выявленное в ходе опроса значение z* = 2,34, равна 1 — 0,9904 = 0,0096.
Проиллюстрируем это рис. 12.13. На нем по горизонтальной оси откладываются значения стандартизованной случайной величины z. Значению z = 0 согласно формуле 12.8 соответствует значение нестандартизованной случайной величины? = 0,35, а точке z = 2,34 — полученное в ходе опроса значение р =0,48.
Площадь под колоколообразной кривой плотности нормального распределения, как известно, равна единице. Площадь области 1, ограниченной жирной линией, равна 0,9904, а площадь области 2, выходящей за пределы жирной линии, равна 0,0096. Именно этому небольшому числу равна вероятность события z? 2,34. Итак, учитывая способ построения стандартизованной случайной величины z, вероятность получить в ходе опроса р? 0,48 при условии, что согласно нашей нулевой гипотезе истинная доля знающих о новом продукте во всей исследуемой совокупности равна 0,45, равна 0,0096. Это меньше принятой нами доверительной вероятности 0,05, что дает нам основание отвергнуть нулевую гипотезу и принять альтернативную: р > 0,45, т. е. рекламная кампания эффективна.
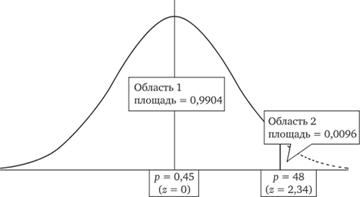
Рис. 12.13. Проверка гипотезы с помощью стандартизованного нормального распределения случайной величины z.
Заметим, что можно было поступить чуть иначе: до опроса наметить пороговую долю знающих о существовании продукта респондентов, такую, что, если в ходе опроса будет зафиксирована такая или более высокая доля, нулевая гипотеза должна быть отвергнута. Таким образом, можно сформулировать обратную задачу. Покажем, как это делается на нашем примере.
Обратная задача: найти самое низкое значение выборочной доли знающих о продукте, которое статистически значимо превышает ее плановое значение 0,45.
По таблицам обратного нормального стандартизованного распределения или с помощью функции MS Excel НОРМСТОБР(0,95) определим, что в стандартизованном нормальном распределении такая вероятность (1 —? = 0,95%) соответствует значению случайной величины z, равному 1,645. При нестандартизованном нормальном распределении со средним значением 0,45 и стандартным отклонением 0,0128 этому значению соответствует значение выборочной доли 0,45 + 0,0128 · 1,6450 = 0,471. Это означает, что нулевая гипотеза должна отвергаться, если в ходе опроса доля знающих о существовании продукта окажется не менее этой величины. Ту же мысль можно выразить так: полученная в ходе опроса доля знающих о новом продукте, равная или большая 47,1%, статистически значимо превышает 45%.
Заметим, что наши рассуждения касались одностороннего статистического критерия и задачи, когда нас интересуют отклонения от фиксированного значения только в одну сторону. Если же гипотеза состоит в отклонении частоты от фиксированного значения (неважно в какую сторону) то уровень значимости следует сравнивать с площадью не под одним «хвостом» кривой плотности нормального распределения, как показано на рис. 12.13, а под двумя (правым и левым) «хвостами» такой кривой. Поэтому уровень значимости (в нашем примере 0,05) следует разделить на 2, т. е. сравнивать площадь под каждым «хвостом» распределения не с числом 0,05, а с числом 0,025. С помощью таблиц или функции обратного нормального распределения легко установить, что такая вероятность (0,975) соответствует значению стандартизованной нормально распределенной случайной величины z*=1,960.
Умножив это число на стандартное отклонение 0,0128, легко установить, что нулевая гипотеза о том, что доли потребителей, осведомленных о старом и видоизмененном продукте, на самом деле совпадают, должна отвергаться, если полученная в результате опроса доля осведомленных респондентов выйдет за пределы интервала: 0,45 ± 0,0128 · 1,960 = 0,45 ± 0,0251.
Приведенный пример, в частности, иллюстрирует тот факт, что односторонние критерии при фиксированном уровне значимости всегда мощнее, чем соответствующие двусторонние. Так, полученный в ходе опроса результат (выборочная доля равна 0,48) с большим запасом оказался достаточным, чтобы отвергнуть нулевую гипотезу в случае одностороннего критерия (0,48 > 0,471), и с совсем небольшим запасом — для двустороннего (0,48  0,475%). Следовательно, во втором случае шансы, что искомое маркетинговое решение не будет принято из-за того, что исследователь совершит ошибку второго рода (не отклонит Н0, когда на самом деле ее надо отклонить), повышаются. Соответственно с повышением вероятности ошибки второго рода (?) снижается мощность статистического критерия (1 — ?).
0,475%). Следовательно, во втором случае шансы, что искомое маркетинговое решение не будет принято из-за того, что исследователь совершит ошибку второго рода (не отклонит Н0, когда на самом деле ее надо отклонить), повышаются. Соответственно с повышением вероятности ошибки второго рода (?) снижается мощность статистического критерия (1 — ?).