Прогнозирование спроса в логистике

Отслеживание ошибки прогнозирования Одним из существенных преимуществ модели экспоненциального сглаживания при краткосрочном прогнозировании является возможность постоянной адаптации прогноза с учетом самых последних наблюдений во временном ряде. При этом точность прогнозирования напрямую зависит от значения сглаживающей константы в каждый конкретный период времени. Следовательно, усложненная… Читать ещё >
Прогнозирование спроса в логистике (реферат, курсовая, диплом, контрольная)
В основном в сфере логистике требуется лишь небольшое количество методик прогнозирования. Поскольку прогнозы — особенно прогноз продаж, — необходимы различным сегментам организации, то прогнозирование обычно сосредотачивается в отделе маркетинга, плановом отделе или отделе экономического анализа. Долгосрочные и среднесрочные прогнозы часто составляются в отделе логистики. Однако потребности отдела логистики обычно ограничиваются краткосрочными прогнозами, которые необходимы для планирования запасов, календарного планирования перевозок, планирования загрузки складских помещений и т. п. Исключение составляют только потребности в каких-то специальных долгосрочных прогнозах.
Учитывая степень сложности, полезности, достоверности и доступности информации, лишь часть методик из тех, которые перечислены в таблице 1, имеет смысл рассматривать подробно. Многочисленные исследования показали, что «простые» модели анализа временных рядов позволяют прогнозировать продажи не хуже или даже еще лучше, чем более сложные и трудоемкие методики. Модель временного ряда относится к разряду факторных моделей и является наиболее распространенной в практике прогнозирования. В целом, усложнение модели прогнозирования не обеспечивает увеличения точности прогноза. Поэтому дальше будут рассмотрены только три наиболее популярные методики анализа временного ряда: экспоненциальное сглаживание, классический анализ временных рядов и множественный регрессионный анализ.
Экспоненциальное сглаживание Возможно, что экспоненциальное сглаживание — это наиболее популярный метод прогнозирования. Он очень прост, требует минимальных исходных данных, обладает высокой точностью и легко адаптируется под конкретные задачи прогнозирования. Метод является вариантом методики расчета скользящих средних, при котором результаты прошлых наблюдений имеют меньший вес, чем результаты новых, более свежих наблюдений за продажами.
Такая схема распределения весовых коэффициентов может быть задана простым уравнением, в котором прогноз на будущий период составляется на основе прогноза предыдущего периода и фактических продаж в текущем периоде:
Новый прогноз = (фактический спрос) + (1 —)(предыдущий прогноз) В этой формуле — это весовой коэффициент, или сглаживающая постоянная. Коэффициент варьируется от 0 до 1. Отметим, что все прошлые наблюдения за продажами включены в прогноз предыдущего периода. Таким образом, вся предыдущая история продаж отражена в одном числовом значении прогноза за предыдущий период.
Пример. Допустим, что прогноз спроса в текущем месяце составляет 1000 шт. Фактический спрос в текущем месяце составил 950 шт. Сглаживающая константа составляет = 0,3. Ожидаемый спрос в следующем месяце определяется по формуле:
Новый прогноз = 0,3950 + 0,71 000 = 985 шт.
Этот новый прогноз будет использоваться в формуле для расчета нового прогноза на второй месяц и т. д.
Для удобства расчетов запишем формулу экспоненциального сглаживания в виде следующей модели:
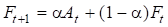
.
где t — текущий временной период; Ft — прогноз продаж на период t; Ft+1 — прогноз продаж на период (t+1); - константа сглаживания; At — продажи в период t.
Пример. Следующий квартальный временной ряд представляют данные о спросе на продукцию за полтора года:
Таблица 1.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | F3 = ? |
Нам необходимо построить прогноз на третий квартал текущего года. Допустим, что сглаживающая постоянная = 0,2. Прогноз предыдущего периода рассчитаем как средний уровень спроса в квартал по данным предыдущего года. Следовательно, А0 = (1200 + 700 + 900 + 1100)/4 = 975. Допустим, что прогноз продаж в прошлом году в среднем соответствовал фактическим продажам, т. е. F0 = А0 = 975.
Тогда прогноз на первый квартал текущего года:
F1 = 0,2A0 + (1 — 0,8)F0 = 0,2975 + 0,8975 = 975.
Прогноз на второй квартал текущего года:
F2 = 0,2A1 + (1 — 0,8)F1 = 0,21 400 + 0,8975 = 1060.
Прогноз на третий квартал текущего года:
F3 = 0,2A2 + (1 — 0,8)F2 = 0,21 000 + 0,81 060 = 1048.
В итоге получаем следующие результаты:
Таблица 2.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | F3 = ? | |
Прогноз. |
Выбор оптимального значения сглаживающей константы основывается на оценочных суждениях.
- § Чем выше значение константы, тем большее влияние на прогноз оказывают последние наблюдения за фактическими продажами. В результате модель более гибко и быстро реагирует на изменения в продажах. Однако слишком высокий уровень делает модель слишком «нервной», слишком чутко реагирующей на любой случайное колебание спроса без учета основной тенденции развития.
- § Чем ниже значение константы, тем больший вес в прогнозе имеют прошлые наблюдения за фактическими продажами. В виду этого модель реагирует на изменения в тенденциях развития спроса медленнее, с запозданием. При очень низком значение модель реагирует на изменения спроса крайне медленно и тяжело, что обеспечивает очень «стабильный» прогноз, но делает его крайне неправдоподобным, не похожим на временной ряд.
Наиболее приемлемые значения константы варьируются в интервале от 0,01 до 0,3. Более высокие значения могут использоваться при краткосрочном прогнозировании, когда ожидаются какие-то серьезные изменения на рынке. Например, падение продаж, краткосрочные и агрессивные маркетинговые компании, вывод из продуктовой линии некоторых устаревших продуктов, начало продаж нового продукта, когда нет еще достаточной статистики для прогнозирования спроса и пр.
Основное правило при выборе значения константы: модель должна отображать основную тенденцию в развитии спроса и сглаживать случайные колебания. Такая константа обеспечивает минимальную ошибку прогнозирования.
Корректировка прогноза с учетом тренда Простое экспоненциальное сглаживание удобно использовать в том случае, если отсутствует устойчивая тенденция к увеличению или уменьшению спроса, т. е. средний уровень спроса достаточно стабилен во времени. Если же в продажах обнаруживается, например, тренд к повышению спроса, то каждый новый прогноз будет устойчиво меньше фактического спроса.
К счастью, прогноз можно откорректировать, введя в методику дополнительную формулу, с помощью которой рассчитывается тренд. Для этого к экспоненциальному уравнению необходимо добавить еще одну формулу, которая будет учитывать тренд:
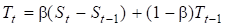
где St — начальный прогноз в пери од t, Тt — тренд в период t, Ft+1 -прогноз на период t+1 с учетом тренда, — сглаживающая постоянная для тренда.
Пример. Рассчитаем прогноз на третий квартал текущего года с учетом тренда:
Таблица 3.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | F3 = ? |
Для начала рассчитаем прогноз на первый квартал текущего года. В качестве исходных значений при расчетах будем использовать S0 = 975 (средний спрос за квартал по данным предыдущего года) и T0 = 0 (тренд отсутствует). Допустим, что сглаживающие постоянные = 0,2 и = 0,3. Теперь начнем расчеты.
Прогноз на первый квартал текущего года:
S0 = 975, T0 = 0 F1 = 975 + 0 = 975.
Прогноз на второй квартал текущего года:
S1 = 0,21 400 + 0,8(975 + 0) = 1060.
Т1 = 0,3(1 060 — 975) + 0,70 = 25,5.
F2 = 1060 + 25,5 = 1085,5.
Прогноз на третий квартал текущего года:
S2 = 0,21 000 +0,8(1060 + 25,5) = 1068,4.
Т2 = 0,3(1068,4 — 1060) + 0,725,5 = 20,37.
F2 = 1068,4 + 20,37 = 1088,77.
В итоге получаем:
Таблица 4.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | ||
Прогноз. | 1 086. | 1 089. |
Корректировка прогноза с учетом тренда и сезонности При прогнозировании можно учесть не только тренд, но и сезонные колебания спроса. Прежде чем использовать модель, которая рассмотрена в следующем примере, следует проверить временной ряд на выполнение следующих двух условий:
Сезонные пики и падения спроса должны четко проглядываться на статистическом ряде, т. е. они должны быть больше, чем случайные колебания спроса (так называемый «шум»).
Сезонные пики и падения спроса должны устойчиво повторяться из года в год.
Если эти два условия не соблюдаются, то есть сезонные колебания неустойчивы, незначительны и трудно отличаются от «шума», то использовать модель для точного прогноза спроса на следующий временной период будет крайне трудно. Если условия выполняются и в модели устанавливается высокое значение сглаживающей постоянной, чтобы учитывать большую амплитуду колебаний спроса, то имеет смысл усложнить модель.
В этой новой модели прогноз строится с учетом корректировок тренда и сезонности, которые отображаются в форме индексов. Это позволяет достичь высокой точности прогноза.
Уравнения усложненной модели:
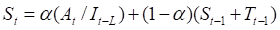
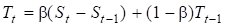
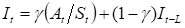
где Тt — тренд в период t, St — начальный прогноз в период t, Ft+1 — прогноз на период t+1 с учетом тренда и сезонности, It -индекс сезонных колебаний в период t, L — временной период, в течение которого совершается полный сезонный цикл, — сглаживающая постоянная для сезонного индекса.
Пример. Рассчитаем прогноз на третий квартал текущего года с учетом тренда:
Таблица 5.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | F3 = ? |
Для начала рассчитаем прогноз на первый квартал текущего года. В качестве исходных значений при расчетах будем использовать St-1 = 975 (средний спрос за квартал по данным предыдущего года) и Tt-1 = 0 (тренд отсутствует). Допустим, что сглаживающие постоянные = 0,2 и = 0,3, а = 0,4. Теперь начнем расчеты.
Прогноз на первый квартал текущего года:
S0 = 975 и T0 = 0. Тогда:
F1 = (975 + 0) 1,23 = 1200, потому что I1 = 1200 / 975 = 1,23.
И тогда:
Прогноз на второй квартал текущего года:
S1 = 0,21 400 / 1,23 + 0,8(975 + 0) = 1007,5.
I1 = 0,41 400 / 1007,5 + 0,61,23 = 1,29.
Т1 = 0,3(1007,5 — 975) + 0,70 = 9,75.
F2 = (1007,5 + 9,75)0,72 = 730,3, потому что I2 = 700 / 975 = 0,72.
Прогноз на третий квартал текущего года:
S2 = 0,21 000 / 0,72 +0,8(1007,5 + 9,75) = 1092,4.
I2 = 0,41 000 / 1092,4 + 0,60,72 = 0,8.
Т2 = 0,3(1092,4 — 1007,5) + 0,79,75 = 32,3.
F2 = (1092,4 + 32,3)0,92 = 1005, потому что I3 = 900 / 975 = 0,92.
В итоге получаем:
Таблица 6.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | ||
Прогноз. | 1 200. | 1 005. |
Ошибка прогнозирования Поскольку будущее никогда нельзя в точности предугадать по прошлому, то прогноз будущего спроса всегда будет содержать в себе ошибки в той или иной степени. Модель экспоненциального сглаживания прогнозирует средний уровень спроса. Поэтому следует построить модель так, чтобы уменьшить разность между прогнозом и фактическим уровнем спроса. Эта разность называется ошибкой прогнозирования.
Ошибка прогнозирования выражается такими показателями, как среднеквадратическое отклонение, вариация или среднее абсолютное отклонение. Раньше среднее абсолютное отклонение использовалось в качестве основного измерителя ошибки прогнозирования при использовании модели экспоненциального сглаживания. Среднеквадратическое отклонение отвергли из-за того, что рассчитывать его сложнее, чем среднее абсолютное отклонение, и у компьютеров на это просто не хватало памяти. Сейчас у компьютеров достаточно памяти, и теперь среднеквадратическое отклонение используется чаще.
Ошибку прогнозирования можно определить с помощью следующей формулы:
ошибка прогноза = фактический спрос — прогноз спроса Если прогноз спроса представляет собой среднее арифметическое фактического спроса, то сумма ошибок прогнозирования за определенное количество временных периодов будет равна нулю. Следовательно, значение ошибки можно отыскать путем суммирования квадратов ошибок прогнозирования, что позволяет избежать взаимного устранения положительных и отрицательных ошибок прогнозирования. Эта сумма делится на количество наблюдений и затем из нее извлекается квадратный корень. Показатель корректируется с уменьшением одной степени свободы, которая теряется при составлении прогноза. В результате, уравнение среднеквадратического отклонения имеет вид:
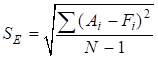
.
где SE — средняя ошибка прогнозирования; Ai — фактический спрос в период i; Fi — прогноз на период i; N — размер временного ряда.
Форма распределения ошибок прогнозирования является важной, когда формулируются вероятностные утверждения о степени надежности прогноза. Две типовые формы распределения ошибок прогнозирования показаны на рисунке 3.
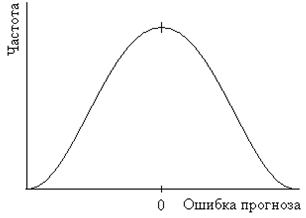
Рис. 3а. Нормальное распределение ошибок прогноза
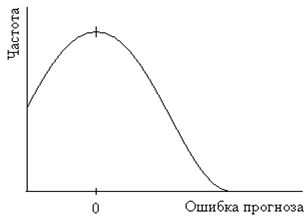
Рис. 3б. Скошенное распределение ошибок прогноза
Полагая, что модель прогнозирования отражает средние значения фактического спроса достаточно хорошо и отклонения фактических продаж от прогноза относительно невелики по сравнению с абсолютной величиной продаж, то вполне вероятно предположить нормальное распределение ошибок прогнозирования. В тех же случаях, когда ошибка прогнозирования сопоставима по величине с величиной спроса, имеет место скошенное, или усеченное нормальное распределение ошибок прогноза.
Определить тип распределения в конкретной ситуации можно с помощью теста на соответствие критерию согласия хи-квадрат. В качестве альтернативы можно использовать другой тест, с помощью которого можно определить, является ли распределение симметричным (нормальным) или экспоненциальным (разновидность скошенного распределения):
При нормальном распределении около 2% наблюдаемых значений превышают значение, равное сумме среднего и удвоенного значения среднеквадратического отклонения. При экспоненциальном распределении около 2% наблюдаемых значений превышают среднее на величину среднеквадратического отклонения, умноженного на коэффициент 2,75. Следовательно, в первом случае используется нормальное распределение, а во втором случае — экспоненциальное.
Пример. Снова вернемся к нашему примеру. В базовой модели экспоненциального сглаживания были получены следующие результаты:
Таблица 7.
Квартал. | ||||
I. | II. | III. | IV. | |
Прошлый год. | 1 200. | 1 100. | ||
Текущий год. | 1 400. | 1 000. | F3 = ? | |
Прогноз. | 1 200. | 1 005. |
Оценим стандартную ошибку прогнозирования по данным за первый и второй кварталы текущего года, по которым нам известны фактические и прогнозные значения. Допустим, что спрос имеет нормальное распределение относительно прогноза. Рассчитаем границы доверительного интервала с вероятностью 95% для третьего квартала.
Стандартная ошибка прогнозирования:
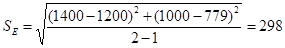
Используя таблицу, А (см. Приложение I), определяем коэффициент z95% = 1,96 и получаем границы доверительного интервала по формуле:
Y = F3 z (SE) =1005 1,96 298 = 1064 584,2.
Следовательно, с 95%-й вероятностью границы доверительного интервала прогноза спроса на третий квартал текущего года составляют значения:
420,8 < Y < 1589,2.
Отслеживание ошибки прогнозирования Одним из существенных преимуществ модели экспоненциального сглаживания при краткосрочном прогнозировании является возможность постоянной адаптации прогноза с учетом самых последних наблюдений во временном ряде. При этом точность прогнозирования напрямую зависит от значения сглаживающей константы в каждый конкретный период времени. Следовательно, усложненная процедура прогнозирования должна включать в себя регулярное отслеживание средней ошибки прогнозирования и соответствующую корректировку значения сглаживающей постоянной. Если временной ряд достаточно постоянный, то можно устанавливать низкие значения константы. В период больших колебаний спроса следует установить высокое значение константы. Но не следует ограничиваться каким-то одним значением, если изменение константы может привести к уменьшению ошибки прогнозирования, особенно в случае высокой динамики временного ряда.
Популярным методом отслеживания ошибки прогнозирования является метод усреднения отслеживающего сигнала. Отслеживающий сигнал — это результат сравнения, получаемого обычно в виде соотношения, текущий ошибки прогнозирования со средним значениям прошлых ошибок прогнозирования. В результате этого вычисления сглаживающая экспоненциальная константа может быть пересчитана или переопределена, если полученное соотношение превосходит ранее определенный контрольный уровень.
В целом, наилучшей сглаживающей константой является та, которая минимизирует ошибку прогнозирования так, как это было бы при стабильном временном ряде. Изменяя значение константы по мере того, как временной ряд пополняется новыми значениями, позволяет уменьшить ошибку прогнозирования. Адаптирующиеся модели, которые пересчитывают значения сглаживающей константы постоянно, работают хорошо в случае, когда временной ряд меняется быстро, но они малоэффективны в условиях стабильных продаж. Наоборот, модели, в которых пересчет сглаживающей константы происходит только в случае, когда ошибка прогнозирования превосходит некий контрольный уровень, хорошо работают в условиях стабильности, когда возможны резкие и неожиданные скачки временного ряда. Пример такой адаптирующейся модели показан на рисунке 5.