Параллельный эвристический алгоритм k-эталонов
Если данные описаны не полностью (шум велик), то выбирается еще одно направление — перпендикулярное к первому, так чтобы описать оставшееся изменение в данных и т. д. Метод главных компонент применяется к данным, записанным в виде матрицы X — прямоугольной таблицы чисел размерностью I строк и J столбцов. Поставим в соответствие объекту Оi код из k двоичных символов еi = (еi1, еi2, …, еik), где… Читать ещё >
Параллельный эвристический алгоритм k-эталонов (реферат, курсовая, диплом, контрольная)
Пусть для классификации имеется выборка O1, O2,…, On, причем i-ый объект характеризуется вектором признаков Хi = (x1, x2, …, xp). Рассмотрим р-мерное признаковое пространство вместе с функцией d (Xi, Xl), задающей в Rp расстояние (либо степень близости).
I) Выберем k эталонов X1*, X2*,…, Xk* и порог d0.
II) Поставим в соответствие объекту Оi код из k двоичных символов еi = (еi1, еi2, …, еik), где еil = 1, если d (Xi, Xl)? d0, и еil = 0 в противном случае.
Разобьем выборку на классы, отнесся к одному из классов объекты с одинаковым кодом. В зависимости от порога d0 и геометрии выборки число классов может варьироваться от 1 до 2k. После анализа разбиения выборки на классы исследователь может уточнить выбор эталонов и перейти к следующей итерации алгоритма. Набор эталонов можно составлять из случайно выбранных точек.
Метод главных компонент: аппроксимация данных линейными многообразиями
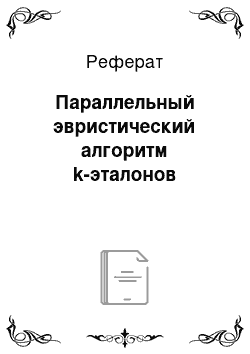
Метод главных компонент применяется к данным, записанным в виде матрицы X — прямоугольной таблицы чисел размерностью I строк и J столбцов.
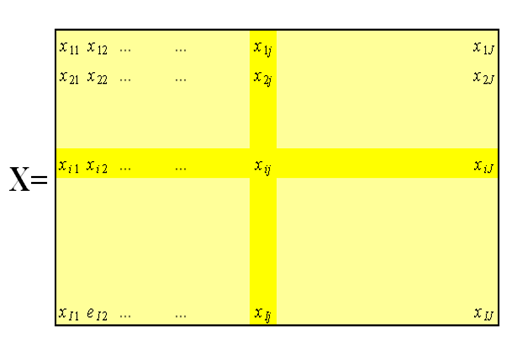
Рис. 2. Матрица данных
Традиционно строки этой матрицы называются образцами. Они нумеруются индексом i, меняющимся от 1 до I. Столбцы называются переменными, и они нумеруются индексом j= 1, …, J.
Цель МГК — извлечение из этих данных нужной информации. Что является информацией, зависит от сути решаемой задачи. Данные могут содержать нужную нам информацию, они даже могут быть избыточными. Однако, в некоторых случаях, информации в данных может не быть совсем.
Размерность данных — число образцов и переменных — имеет большое значение для успешной добычи информации. Лишних данных не бывает — лучше, когда их много, чем мало.
Передадим суть метода главных компонент, используя интуитивно-понятную геометрическую интерпретацию. Начнем с простейшего случая, когда имеются только две переменные x1 и x2. Такие данные легко изобразить на плоскости.
Рис. 3. Графическое представление двумерных данных
Каждой строке исходной таблицы (т.е. образцу) соответствует точка на плоскости с соответствующими координатами. Они обозначены пустыми кружками на Рис. 3. Проведем через них прямую, так, чтобы вдоль нее происходило максимальное изменение данных. На рисунке эта прямая выделена синим цветом; она называется первой главной компонентой. Затем спроецируем все исходные точки на эту ось. Получившиеся точки закрашены красным цветом. Теперь можно сделать предположение, что на самом деле все экспериментальные точки и должны были лежать на этой новой оси. Просто какие-то неведомые силы отклонили их от правильного, идеального положения. Тогда все отклонения от новой оси можно считать шумом, т. е. ненужной нам информацией. Проверить шум ли это, или все еще важная часть данных, можно поступив с этими остатками так же, как поступили с исходными данными — найти в них ось максимальных изменений. Она называется второй главной компонентой. И так надо действовать, до тех пор, пока шум уже не станет действительно шумом, т. е. случайным хаотическим набором величин.
В общем, многомерном случае, процесс выделения главных компонент происходит так:
- 1. Ищется центр облака данных, и туда переносится новое начало координат — это нулевая главная компонента (синяя точка на рис.4).
- 2. Выбирается направление максимального изменения данных — это первая главная компонента.
- 3. Если данные описаны не полностью (шум велик), то выбирается еще одно направление — перпендикулярное к первому, так чтобы описать оставшееся изменение в данных и т. д.

Рис. 4. Графическое представление метода главных компонент
МГК начинался с задачи наилучшей аппроксимации конечного множества точек прямыми и плоскостями. Пусть дано конечное множество векторов x1, x2,…, xm Rn. Для каждого k = 0, 1, …, n — 1 среди всех k-мерных линейных многообразий в Rn найти такое Lk Rn, что сумма квадратов уклонений xI от Lk минимальна:


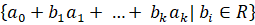
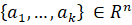
где — евклидово расстояние от точки до линейного многообразия. Всякое k-мерное линейное многообразие в Rn может быть задано множеством линейных комбинаций Lk =, где bi пробегают вещественную прямую R, a0 Rn , — ортонормированный набор векторов. В координатной форме:
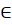


Решение задачи аппроксимации для k = 0,1, …, n — 1 даётся набором вложенных линейных многообразий L0 L1 L2 … Ln-1. Эти линейные многообразия определяются ортонормированным набором векторов (векторами главных компонент) и вектором a0:


Это выборочное среднее:. Векторы главных компонент могут быть найдены как решения однотипных задач оптимизации:

1) централизуем данные:. Теперь ;
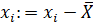
2) находим первую главную компоненту как решение задачи:

Если решение не единственно, то выбираем одно из них.
3) Вычитаем из данных проекцию на первую главную компоненту:

;
4) Находим вторую главную компоненту как решение задачи:
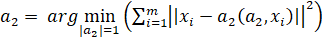
Если решение не единственно, то выбираем одно из них.
2k-1) Вычитаем проекцию на (k-1)-ую главную компоненту:

;
2k) находим k-ую главную компоненту:

геометрический зерно пшеница кластеризация Если решение не единственно, то выбирается одно из них.