Математическая модель, построенная на основе мультисловарей

Где F (X) — значение выхода нечеткой модели при значении входов, заданных вектором X =, М — количество текстов,? = 1 — степень уверенности принадлежности текста к предметной области НЛ. На вход модели в качестве степени уверенности принадлежности терминов текста к соответствующему словарю подаются относительные частоты терминов всех подсловарей в каждом тексте. Математическая модель определения… Читать ещё >
Математическая модель, построенная на основе мультисловарей (реферат, курсовая, диплом, контрольная)
лингвистический словарь тезаурус терминологический Для второй модели в качестве входных параметров системы нечёткого вывода также будем рассматривать 6 нечётких лингвистических переменных (см. модель 1.). А в качестве выходных параметров — 3 нечеткие лингвистические переменные, определяющие принадлежность текста к предметной области: «Fuzzy» — F, «Logik» — L, «Mathematik» — M.
В качестве терм-множества всех лингвистических переменных (ЛП) будем использовать множество Т1={"min", «med», «max», «none"} (Рис.3). При этом каждый из термов ЛП будем оценивать по шкале от 0 до 1, при которой цифре 0 соответствует наименьшая принадлежность терминов текста к определенному подсловарю, а цифре 1 — наибольшая.
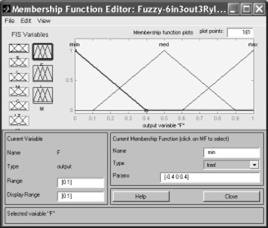
Рис. 3. Функции принадлежности выходной переменной F
После обработки 18 текстов по НЛ, 10 текстов по математике и 10 текстов по логике программой Fuzzy Base были получены частотные характеристики, на основе которых по средним значениям относительных частот встречаемости терминов построен частотный портрет (Рис. 4.). [Арзамасцева и др., 2008b].
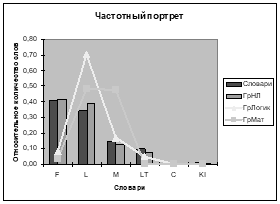
Рис. 4. Частотный портрет
Затем по данным усредненных частот групп текстов каждой предметной области были найдены минимальные и максимальные значения. (Табл.1.).
Табл. 1.
F. | L. | M. | C. | LT. | KI. | ||
F. | |||||||
Среднее. | 0,39 627. | 0,40 753. | 0,13 575. | 0,51. | 0,5 615. | 0,375. | |
min. | 0,031. | 0,086. | 0,013. | 0,000. | 0,000. | 0,000. | |
max. | 0,763. | 0,872. | 0,771. | 0,022. | 0,571. | 0,044. | |
L. | |||||||
Среднее. | 0,083. | 0,739. | 0,168. | 0,000. | 0,009. | 0,001. | |
min. | 0,000. | 0,500. | 0,049. | 0,000. | 0,000. | 0,000. | |
max. | 0,337. | 0,937. | 0,439. | 0,000. | 0,038. | 0,010. | |
M. | |||||||
Среднее. | 0,036. | 0,484. | 0,477. | 0,000. | 0,000. | 0,003. | |
min. | 0,000. | 0,222. | 0,000. | 0,000. | 0,000. | 0,000. | |
max. | 0,105. | 1,000. | 0,741. | 0,000. | 0,000. | 0,033. | |
По данным этих усредненных частот были сформулированы 3 нечетких правила отнесения текста к предметной области Нечеткой логики, Математики и Логики (система нечёткого вывода типа Мамдани):
ПРАВИЛО 1: ЕСЛИ уровень относительной частоты терминов F в тексте — «средний» И уровень относительной частоты терминов L — «средний» И уровень относительной частоты терминов M — «минимальный» И уровень относительной частоты терминов LT — «минимальный» И термины словарей C и KI — отсутствуют, ТО степень уверенности, что текст принадлежит к предметной области F — максимальная.
ПРАВИЛО 2: ЕСЛИ уровень относительной частоты терминов F в тексте — «минимальный» И уровень относительной частоты терминов L — «максимальный» И уровень относительной частоты терминов M — «минимальный» И термины словарей C, LT и KI — отсутствуют, ТО степень уверенности, что текст принадлежит к предметной области L — максимальная.
ПРАВИЛО 3: ЕСЛИ уровень относительной частоты терминов F в тексте — «минимальный» И уровень относительной частоты терминов L — «средний» И уровень относительной частоты терминов M — «максимальный» И термины словарей C, LT и KI — отсутствуют, ТО степень уверенности, что текст принадлежит к предметной области М — максимальная.
Формализованное множество данных правил выглядит следующим образом:
R1 — IF X1 is «med» AND X2 is «med» AND X3 is «min» AND LT is «min» then Text is F.
R2 — IF X1 is «min» AND X2 is «max» AND X3 is «min» then Text is L.
R2 — IF X1 is «min» AND X2 is «med» AND X3 is «max» then Text is M.
В таблице 2 приведены эти 3 правила базы знаний, сформулированные на основе частотных портретов текстов.
Табл. 2.
Правила. | F. | L. | M. | C. | KI. | LT. | Text F. | Text L. | Text M. | |
med. | med. | min. | none. | none. | min. | max. | none. | none. | ||
min. | max. | min. | none. | none. | none. | none. | max. | none. | ||
min. | med. | max. | none. | none. | none. | none. | none. | max. | ||
Задача идентификации предметной области состоит в определении степени принадлежности определенного текста к предметной области НЛ на основе нечеткого вывода на базе построенной модели. Точность модели будем оценивать с помощью значения среднеквадратической невязки [Штовба, 2003].
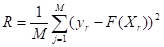
Где F (X) — значение выхода нечеткой модели при значении входов, заданных вектором X = [F, L, M, LT, C, KI], М — количество текстов, ? = 1 — степень уверенности принадлежности текста к предметной области НЛ.
На вход модели в качестве степени уверенности принадлежности терминов текста к соответствующему словарю подаются относительные частоты терминов всех подсловарей в каждом тексте.
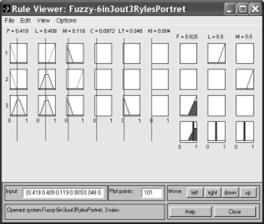
Рис. 5. Правила нечеткого вывода для вектора данных средних значений текстов по НЛ
Расчет выбранной оценки по первым десяти текстам представлен в таблице 3.
Табл. 3.
№. | F. | L. | M. | C. | LT. | KI. | Text F. | Text L. | Text M. | |
1993;1. | 0,256. | 0,395. | 0,326. | 0,000. | 0,023. | 0,000. | 0,775. | 0,5. | 0,5. | |
1993;2. | 0,244. | 0,415. | 0,171. | 0,000. | 0,171. | 0,000. | 0,794. | 0,5. | 0,5. | |
1993;3. | 0,206. | 0,235. | 0,382. | 0,000. | 0,176. | 0,000. | 0,758. | 0,5. | 0,5. | |
1993;4. | 0,453. | 0,333. | 0,189. | 0,000. | 0,025. | 0,000. | 0,811. | 0,5. | 0,5. | |
1993;5. | 0,293. | 0,414. | 0,150. | 0,000. | 0,143. | 0,000. | 0,807. | 0,5. | 0,5. | |
1993;6. | 0,497. | 0,293. | 0,156. | 0,000. | 0,054. | 0,000. | 0,807. | 0,5. | 0,5. | |
1993;7. | 0,053. | 0,342. | 0,289. | 0,000. | 0,316. | 0,000. | 0,500. | 0,5. | 0,5. | |
1993;8. | 0,137. | 0,402. | 0,206. | 0,000. | 0,255. | 0,000. | 0,764. | 0,5. | 0,5. | |
1993;9. | 0,155. | 0,397. | 0,207. | 0,000. | 0,241. | 0,000. | 0,769. | 0,5. | 0,5. | |
1993;10. | 0,139. | 0,417. | 0,111. | 0,000. | 0,333. | 0,000. | 0,765. | 0,5. | 0,5. | |
Среднее. | 0,419 | 0,409 | 0,119 | 0,000 | 0,048 | 0,000 | 0,825 | 0,5 | 0,5 | |
Невязка. | 0,0676. | |||||||||
Математическая модель определения принадлежности текста предметной области на основе мультисловарей, построенная на базе нечеткого вывода по Мамдани:
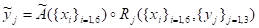
где.
? — нечеткая выходная переменная;
x — входная переменная;
i — индекс для входов;
j — индекс для выходов;
Г — функция принадлежности входных переменных {A1, A2, A3, A4, A5, A6};
Rk — множество правил.