«Внутревыборочное» тестирование модели (in-sample testing)

Для того чтобы провести тестирование на будущих значениях (out of sample testing) надо сначала прогнать модель по части данных, чтобы получить оценки коэффициентов, а затем построить прогнозы, используя оставшиеся данные. К сожалению, у меня в распоряжении всего 28 винтажей, длина которых уменьшается со временем (из-за того, что они не успели «прожить» 16 кварталов), поэтому я не могу провести… Читать ещё >
«Внутревыборочное» тестирование модели (in-sample testing) (реферат, курсовая, диплом, контрольная)
После того, как я получил модели, их надо протестировать. Есть два способа проверки качества модели: на данных, по которым она была построена (in sample testing) и на новых, будущих данных (out of sample testing).
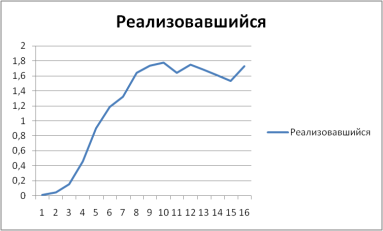
Показателем того, насколько модель хорошо описывает данные, по которым была построена, считают коэффициент R2, который я проанализировал выше. Однако, для лучшего понимания того, насколько модель качественная, я построил несколько прогнозных уровней просроченных платежей, и сравнил их с фактически реализовавшимися. Как и следовало ожидать, из-за показателя R2, наиболее точные предсказания я получил по агрегированной модели. Ее превосходство заключается в том, что она не выдает систематически завышенных или заниженных прогнозов. На графиках представлен реализовавшийся уровень просроченных платежей 90+ дней для ипотечных кредитов, выданных в 3 квартале 2007 года, и прогнозируемый по моей модели уровень просроченных платежей. По вертикальной оси отмечен уровень просроченных платежей 90+ дней в процентах от уровня выдачи, а по горизонтали — сколько кварталов прошло с момента выдачи винтажа.
График 4. Реализовавшийся уровень просроченных платежей.
(Источник: расчеты автора) График 5. Прогнозный уровень просроченных платежей.
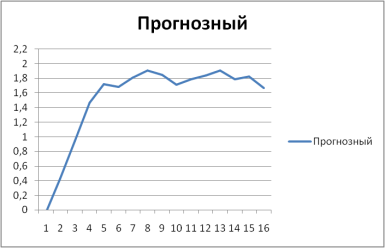
(Источник: расчеты автора) Можно заметить, что моя модель является консервативной — прогнозный уровень просроченных платежей растет быстрее, чем фактический. Также важно отметить, что разница между максимальными значениями составляет всего примерно 0,1%.
Модель с четырьмя разными регрессиями выдавала несколько хуже результаты — максимальные значения отличались на большую величину, и я заметил, что в спокойный период, модель выдавала заниженные прогнозные значения, а в период рецессии — завышенные. Такая систематическая ошибка, скорее всего, подразумевает что я не нашел важную объясняющую переменную для уравнения регрессии.
На последнем месте оказалась самая первая модель с набором фиктивных переменных, отвечающих за различные когорты. Эта модель занижала уровень просроченных платежей в любой период. Таким образом, можно сделать вывод, что самый надежный прогноз можно делать только по агрегированной модели, несмотря на то, что она не различает по риск параметрам LTV и PTI.
Для того чтобы провести тестирование на будущих значениях (out of sample testing) надо сначала прогнать модель по части данных, чтобы получить оценки коэффициентов, а затем построить прогнозы, используя оставшиеся данные. К сожалению, у меня в распоряжении всего 28 винтажей, длина которых уменьшается со временем (из-за того, что они не успели «прожить» 16 кварталов), поэтому я не могу провести такое тестирование, иначе полученные коэффициенты будут не надежными.